はじめに
アクセスの少ないオブジェクトをS3 Glacier Instant Retrievalなど低頻度アクセス用のストレージクラスに移行するライフサイクルを設定したい。
でも、ストレージクラスの移行(ライフサイクル移行リクエスト)には費用がかかり、大量のオブジェクトを移行すると一時的に高額な費用が発生する。
この料金の試算ができず、いくらかかるかわからないから今はやめておこう。そう思って放置しているS3バケットはありませんか?
今回はそのライフサイクル移行リクエストにかかる料金を簡単に算出する方法をご紹介します。
移行リクエスト料の算出は難しい?
ライフサイクル移行の費用を試算するのは意外に簡単ではありません。
S3 Glacier Instant Retrievalでは、移行対象のオブジェクト1000件ごとに0.02USDかかりますが、対象となるオブジェクトの数を正確に算出するのが難しいのです。
バケット全体のオブジェクト数はメトリクスからわかりますが、移行対象になるオブジェクトには基本的に以下の条件がつくため、条件に合わないオブジェクトは移行対象から除外する必要があります。
- アップロードから一定期間以上経過したオブジェクト
- 容量が128KB以上のオブジェクト(※128KBより小さいオブジェクトは移行対象外)
力技で条件に合うオブジェクト数を算出しようとすると、CLIでオブジェクトのメタデータをすべて取ってきて、csv化したりAthena使ったりしてカウントする方法しかないように思います。しかし、この方法だとファイルを整形して、S3にアップロードして、Athenaでテーブルをつくって、と手間がかかります。また、バケット内のオブジェクト数が多いとメタデータの取得に時間がかかります。
そこで活躍するのが S3インベントリ です。
この機能を使用すれば、短時間で簡単に条件に合ったファイル数を算出できます。
最初に結果
こちらの操作のみで、移行対象のファイル数を正確に取得して、移行リクエストにかかる料金を算出できました!
- 対象S3バケットのインベントリを有効化
- インベントリによって出力されたデータに対してAthenaからクエリを実行
こちらがAthenaで結果を取得した画面です。※テーブル名とバケット名を同値にしたためテーブル名を隠しています。
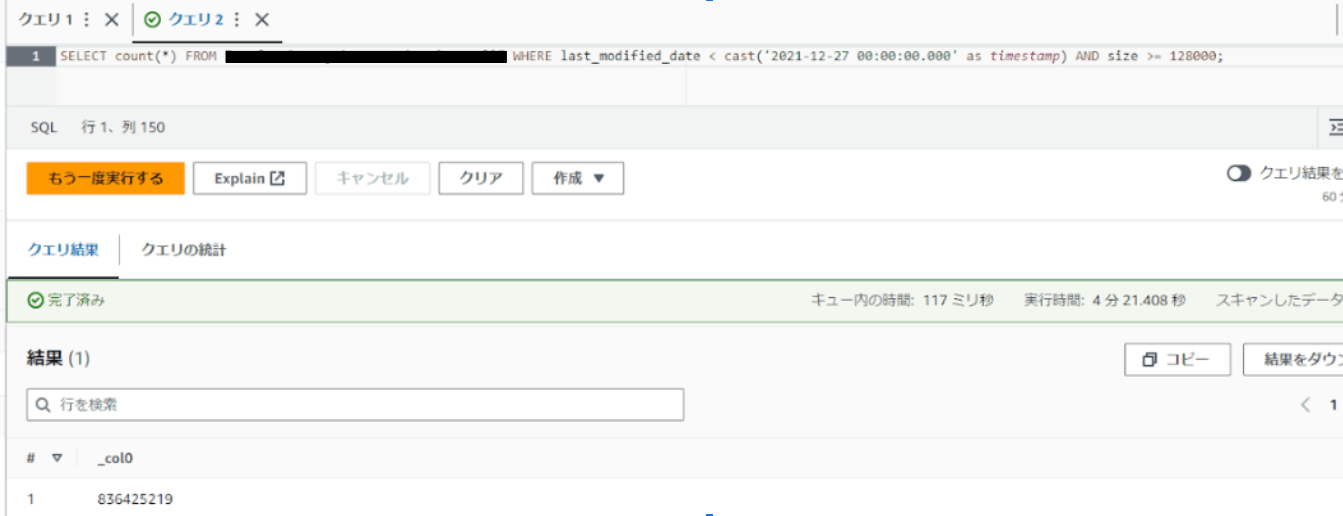
SELECT count(*) FROM "テーブル名" WHERE last_modified_date < cast('2021-12-27 00:00:00.000' as timestamp) AND size >= 128000;
このクエリを実行して、2021年12月27日より前にアップロードされた128KB以上のオブジェクトをカウントしました。その結果、オブジェクト数は836,425,219であることがわかったので、これらを移行した場合の費用を簡単に計算できます。
※S3 Glacier Instant Retrievalに移行した場合(オブジェクト数1,000あたり0.02USD)
836425219 * 0.02/1,000 = 16,728.50438 USD
日本円にして、約240万円
費用の大きさはさておき、移行にかかる具体的な金額を算出できました。
※この金額を払ってもストレージクラス移行ってコストメリットある?という議論は、以下の記事で移行によるコストメリットの試算方法を紹介していますのでご覧ください。
では、事項より具体的なインベントリ設定の手順を紹介します。
S3インベントリ設定
大まかな流れとしてはこちらになります。
- インベントリレポート出力用S3バケットの作成
- インベントリ設定の有効化(※最大48時間後にレポート出力)
- Athena テーブルを作成
- Athena オブジェクト数カウントクエリ実行
インベントリレポート出力用S3バケットの作成
既存のバケットを使用することもできますが、ここではレポート出力用バケットを新規に作成します。レポート用S3バケットは特に特別な設定は不要なので、すべてデフォルト値での作成で問題ありません。バケット名やフォルダの作成は、運用に合わせて設定してください。
インベントリ設定の有効化
レポーティング対象のS3バケットに対してインベントリを有効化します。
AWSマネージドコンソールより対象S3バケットに移動し、"管理"タブから"インベントリ設定"の作成を押下します。

次に、インベントリの各設定です。
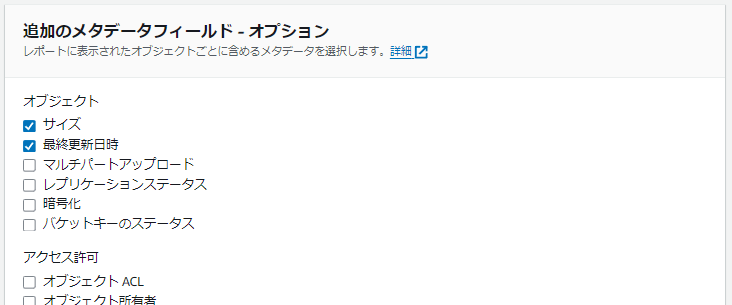
頻度、出力形式、追加のメタデータフィールドを以下の設定にします。
| 設定項目 | 値 |
|---|---|
| 頻度 | 日別 |
| 出力形式 | Apache Parquet |
| 追加のメタデータフィールド | サイズ・最終更新日時 |

それ以外の設定は任意の設定を入力してください。設定値を選択する箇所はデフォルトの設定で問題ありません。
設定後48時間以内に、指定のS3バケットのインベントリ名/hiveフォルダ以下にレポートが出力されます。

Athena テーブルを作成
Athenaで任意のデータベースを選択し、テーブル作成クエリを実行します。
クエリの内容はこちらです。
CREATE EXTERNAL TABLE table_name(
bucket string,
key string,
size bigint,
last_modified_date timestamp
) PARTITIONED BY (
dt string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://[S3バケット名]/[インベントリ名]/hive/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.dt.type" = "date",
"projection.dt.format" = "yyyy-MM-dd-HH-mm",
"projection.dt.range" = "2024-02-01-01-00,NOW",
"projection.dt.interval" = "1",
"projection.dt.interval.unit" = "HOURS"
);
"projection.dt.range" = "2024-02-01-01-00,NOW",

Athena オブジェクト数カウントクエリ実行
テーブルが作成できれば、記事の冒頭でも記載した通り、カウントクエリを実行するのみです。
SELECT count(*) FROM "テーブル名" WHERE last_modified_date < cast('2021-12-27 00:00:00.000' as timestamp) AND size >= 128000;
もちろんSQLが使用できるので、オブジェクト数のカウントだけでなく、オブジェクトサイズの合計なども算出可能です。
まとめ
今回はS3のインベントリ機能でメタデータの一覧を出力し、条件に合ったオブジェクト数を算出することができました。
オブジェクト数ってどうやってカウントしようかと考えていた当初は、AWS CLIのS3 lsでメタデータを取得しようとしました。
ですが、対象バケット内のオブジェクト数の多さから1日経っても完了せず、1日どころか全部取得するのに1か月くらいかかるぞ!とわかって、方法を再検討した際にインベントリの機能が使えることがわかりました。
メタデータの一覧が簡単にできるので、今回はオブジェクト数のカウントでしたが、他にも様々なことができそうです。
例えば、AWS公式ドキュメントにもある通り、コンプライアンス対策にも有効です。
- 日時でレポートを監視し、レプリケーションステータスが"FAILED"のオブジェクトに対してアラートを上げる。
- S3バケットキーのステータス、オブジェクトのアクセス制御リストを取得して監査に利用。
We're Hiring!
DELTAではチームの一員になっていただける仲間を募集中です!
下記フォームよりお気軽にご連絡ください!

DELTAは、ベンチャースタートアップなどの成長企業向けに、ソフトウェア・プロダクト開発や技術選定支援などの技術支援事業を提供しています。 また、成長企業向けに様々な事業支援を提供するSEVENRICH GROUPに属して、グループ内の事業会社や、出資先の支援もおこなっています。
Discussion