この記事はAWS(Amazon Web Services) Advent Calendar 2023 14 日目の記事です。
概要
DynamoDBとOpenSearch Serviceの統合が発表されました。
今までリアルタイムにDynamoDBを連携して検索できるような処理はなく、自前でDynamoDB streamを利用して行う必要があったので、マネージドなものが出てくれるのは今後の選択肢としてとてもありがたいです。
個人的にはOpenSearch Serviceに慣れてないので、実運用するのは難しいなと思いつつも動作を確認してみることにしました。
結論
初回に設定を行うだけで、データをインポートしてくれるようになりました。
データの追従も特に意識せずにいい感じにしてくれるので、便利だなと思う一方で、OpenSearch Serviceの維持コストがそこそこ高いので、ちゃんと使いこなす必要がありそうだと感じました。
詳細
公式ドキュメントを見ながら進めていきます。
DynamoDBの設定
DynamoDBはそのまま利用できるわけではなく
- PITR
- DynamoDB stream
を設定している必要があります。
なお、設定したとしてもダウンタイムは発生しません。
PITRは初回のデータ読み込み、DynamoDB streamはリアルタイムなデータ反映に利用しているようです。
この後の設定ファイルを見た感じでは、用途によって、どちらかが設定されていれば動きそうに見えましたが、現時点では設定されていないとエラーになります。
試しにPITRが設定されていないテーブルで設定しようとしたところ、以下のような警告がでました。

また、先にOpenSearch Serviceのクラスターを起動している必要があるので、OpenSearch Serviceから起動を行います。
OpenSearch Serviceの設定
とりあえず最低限の動作確認をするために、一番小さく簡単な設定で起動します。
今回、1-az、t3.medium、ノードの数を1に設定しました。
以下の記事などを参考に構築しました。
手元での検証をするのであれば、ネットワークをパブリックにしつつ、自分のIPアドレスからのみアクセスを許可するような設定をするのが簡単だと思います。
Roleの作成
DynamoDBからOpenSearch Serviceに連携するためのRoleを作成します。
RoelのUsecaseは「OpenSearch Ingestion Pipelines」とします。
基本的にはRegion(us-east-1)、アカウントID({account-id})、テーブル名(my-table)、バケット名(my-bucket)とバケットのprefix(export)を変更すればOKです。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "allowRunExportJob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:DescribeContinuousBackups",
"dynamodb:ExportTableToPointInTime"
],
"Resource": [
"arn:aws:dynamodb:us-east-1:{account-id}:table/my-table"
]
},
{
"Sid": "allowCheckExportjob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeExport"
],
"Resource": [
"arn:aws:dynamodb:us-east-1:{account-id}:table/my-table/export/*"
]
},
{
"Sid": "allowReadFromStream",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator"
],
"Resource": [
"arn:aws:dynamodb:us-east-1:{account-id}:table/my-table/stream/*"
]
},
{
"Sid": "allowReadAndWriteToS3ForExport",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::my-bucket/export/*"
]
}
]
}
ここで作成したRoleのARNをコピーしておいてください。
DynamoDBの設定
コンソールでDynamoDBのIntegrationを選択すると以下のような画面が表示されます。
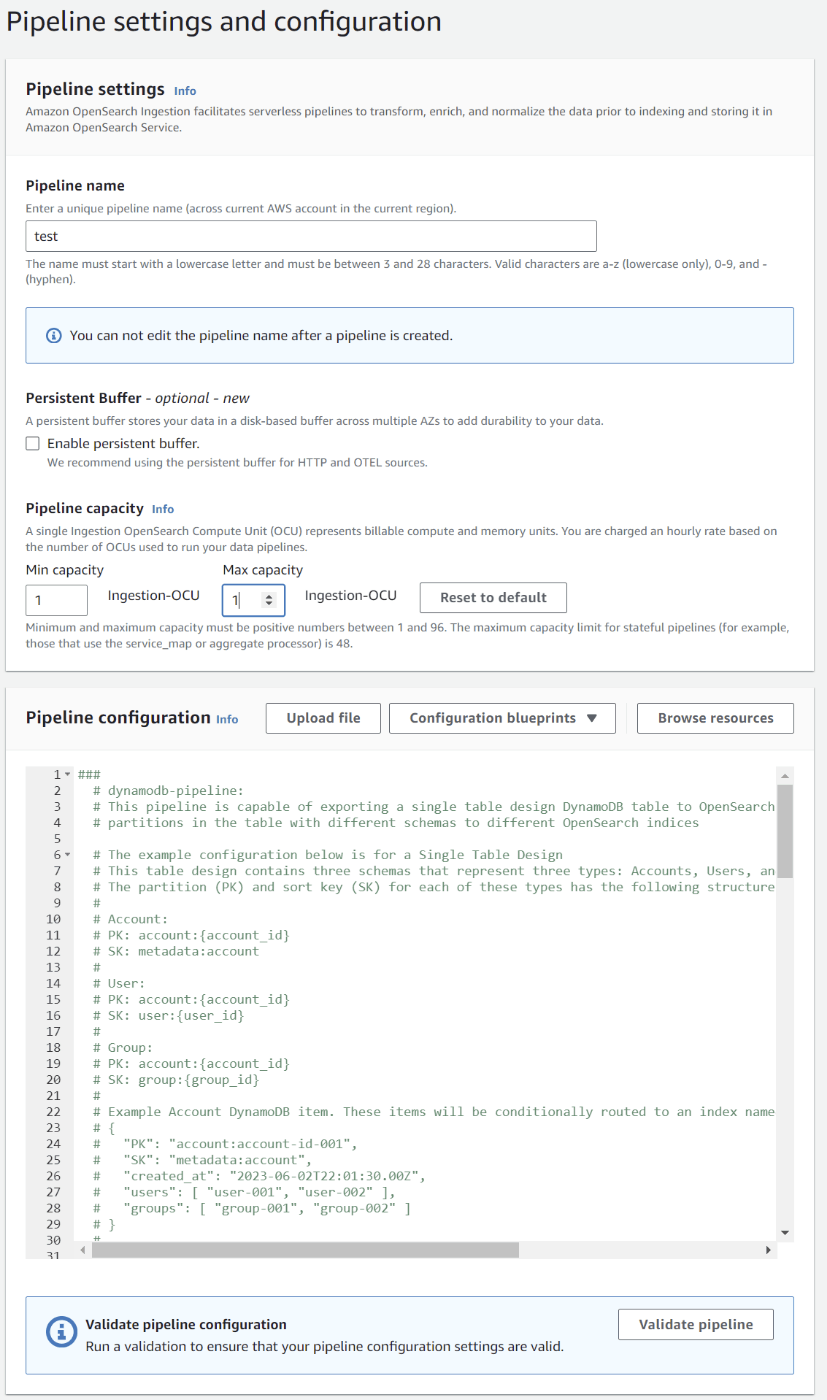
ymlの設定はサンプルを見ると何を設定していいのかがわかりやすいです。
以下は「AWS-DynamoDBSingleTableDesignPipeline」のサンプルを選んだ例です。
気になった部分にコメントを追加しています。
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
# DynamoDBのテーブルのARNを指定します。PITR、DynamoDB streamの設定が必要です。
- table_arn: "arn:aws:dynamodb:us-east-1:123456789012:table/MySingleTable"
# Remove the stream block if only export is needed
stream:
start_position: "LATEST"
# Remove the export block if only stream is needed
export:
# 初回にexportするデータのバケットです。ARNではなくバケット名です。
s3_bucket: "<<my-bucket>>"
# Specify the region of the S3 bucket
s3_region: "<<us-east-1>>"
# prefixです。なぜかroleで指定した値と違っているので注意が必要です。
s3_prefix: "ddb-to-opensearch-export/"
aws:
# 作成したRoleを指定します。
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# Provide the region to use for aws credentials
region: "<<us-east-1>>"
route:
# 値によってindexを分けることができるようです。
# DynamoDBをシングルテーブルで利用している場合に利用します。
# ここでの例ではaccountsとusersとgroupsの3つのテーブルに内部的に分かれるようです。
# accountsではSortKeyが固定、usersとgroupsではそれぞれの文言が含まれる場合に一致するようにしています。
- accounts_route: '/SK == "metadata:account"'
- users_route: 'contains(/SK, "user:")'
- groups_route: 'contains(/SK, "group:")'
sink:
# routeごとに設定します。
# usersの設定
- opensearch:
# OpenSearch Serviceのエンドポイントです。
hosts: [ "<<https://search-mydomain-1a2a3a4a5a6a7a8a9a0a9a8a7a.us-east-1.es.amazonaws.com>>" ]
index: "users"
routes: [ "users_route" ]
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# 作成したRoleを指定します。DynamoDB側で指定したものと同じでOKです。
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# Provide the region of the domain.
region: "<<us-east-1>>"
# Enable the 'serverless' flag if the sink is an Amazon OpenSearch Serverless collection
# serverless: true
# serverless_options:
# Specify a name here to create or update network policy for the serverless collection
# network_policy_name: "network-policy-name"
# Enable the S3 DLQ to capture any failed requests in an S3 bucket. This is recommended as a best practice for all pipelines.
# dlq:
# s3:
# Provide an S3 bucket
# bucket: "your-dlq-bucket-name"
# Provide a key path prefix for the failed requests
# key_path_prefix: "dynamodb-pipeline/dlq"
# Provide the region of the bucket.
# region: "us-east-1"
# Provide a Role ARN with access to the bucket. This role should have a trust relationship with osis-pipelines.amazonaws.com
# sts_role_arn: "arn:aws:iam::123456789012:role/Example-Role"
# accountsの設定
- opensearch:
# REQUIRED: Provide an AWS OpenSearch endpoint
hosts: [ "<<https://search-mydomain-1a2a3a4a5a6a7a8a9a0a9a8a7a.us-east-1.es.amazonaws.com>>" ]
index: "accounts"
routes: [ "accounts_route" ]
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# REQUIRED: Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# Provide the region of the domain.
region: "<<us-east-1>>"
# groupsの設定
- opensearch:
# REQUIRED: Provide an AWS OpenSearch endpoint
hosts: [ "<<https://search-mydomain-1a2a3a4a5a6a7a8a9a0a9a8a7a.us-east-1.es.amazonaws.com>>" ]
index: "groups"
routes: [ "groups_route" ]
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# REQUIRED: Provide a Role ARN with access to the domain. This role should have a trust relationship with osis-pipelines.amazonaws.com
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# Provide the region of the domain.
region: "<<us-east-1>>"
Nextを押すと、バリデーションが実行されて、ymlにエラーがないかをチェックします。
regionは存在する値かどうかのチェックがされているようですが、opensearchのhosts等は値が入っていればエラーにならないように設定されているようなので、あくまで簡易的なバリデーションのようです。
Create Pipelineを選択するとパイプラインが作成されます。
パイプラインのメトリクス等を参照するとデータが入っていることが確認できます。
値のマッピングについて
基本的にはこれだけで、OpenSearch Serviceと連携が完了になりますが、DynamoDBのデータの状況によってはエラーが発生することがあります。
DynamoDBからOpenSearch Serviceに連携するときに、Objectのkeyが初めて出てきた値を正として、データの型の定義を行います。
OpenSearch dynamically maps various attributes based on the first sent document. If you have a mix of data types for the same attribute in DynamoDB, such as both a whole number and a fractional number, mapping might fail.
例えば
{
"value": 123
}
であれば、valueはlongとして認識します。
この値に例えば以下の値が入っていると連携に失敗してエラーとなります。
{
"value": 123.0
}
これは、valueはlongだと設定しているにも関わらず、floatが入っているためにエラーになります。
エラーはCloudWatch Logsに出力されます。
2023-12-08T13:22:18.039 [dynamodb-pipeline-sink-worker-2-thread-2] WARN org.opensearch.dataprepper.plugins.sink.opensearch.OpenSearchSink - Document failed to write to OpenSearch with error code 400. Configure a DLQ to save failed documents. Error: mapper [accumulateData.amountValue] cannot be changed from type [long] to [float]
定義をいい感じに決めるのではなく、指定したい場合はOpenSearch Service側のmapping templateを利用する必要があります。
そのため、単純にimportすればいいわけではなく、実業務で利用する場合には、mapping templateの設定をしてエラーなく取込ができるようにテストをする必要がありそうです。
OpenSearch Serviceで値を確認する
OpenSearch Serviceのダッシュボードから値が入っていることを確認します。
シングルテーブルで利用しているDynamoDBから連携したので、様々なデータが入っていましたが、連携できることを確認できました。
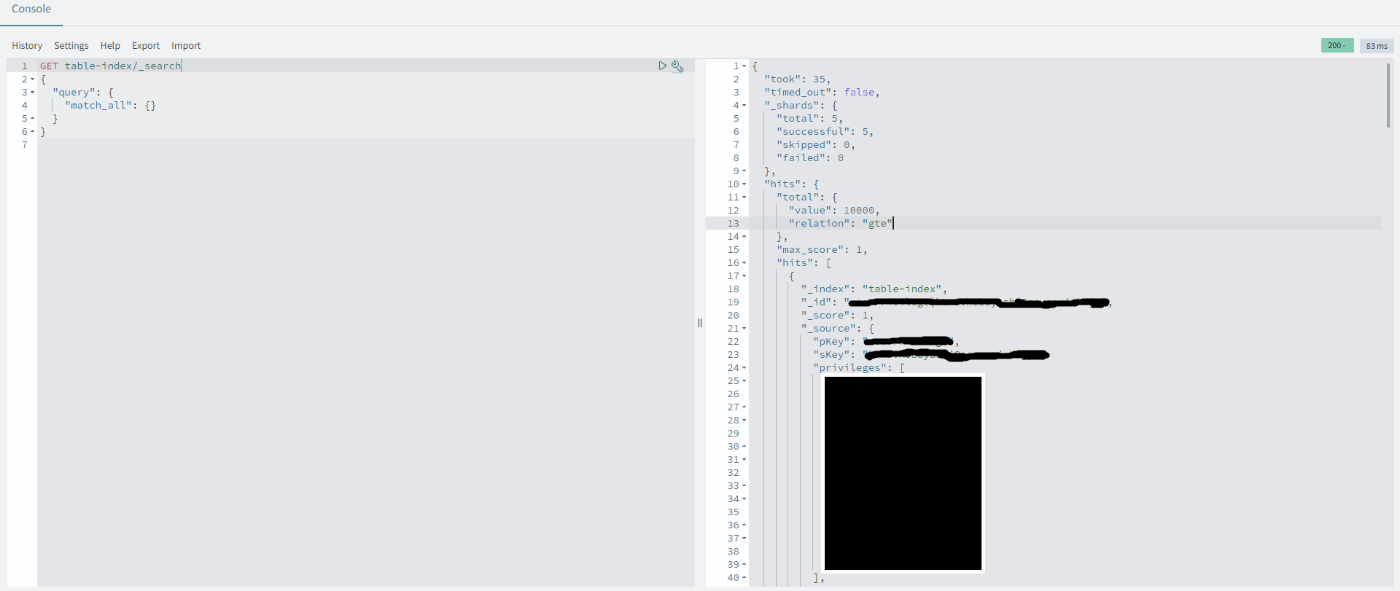
該当の画面へはダッシュボードのTOPページの右側にある「Dev Tool」のボタンを選択すると表示されます。
コストについて
追加でかかる費用としては、
- OpenSearch Serviceのインスタンス
- インスタンス
- t3.medium.search:USD 0.112 / h
- EBSボリューム
- GP3:USD 0.1464 / GB / Month
- インスタンス
- 連携処理(Amazon OpenSearch Ingestion)
- OCUあたり:0.326 / h
連携処理の値が意外と高いですね。
1か月を30日だとすると、 連携処理のみで0.326 * 24 * 30 ≒ 235ドルが月にかかる追加コストになります。
OpenSearch Serviceを使ってない場合はさらに料金がかかります。
- OCUあたり:0.326 / h
検証用に利用している環境では、フルタイムでメンテナンスしているサービスではないこともあり、普段は月に1ドルもかからないのですが、半日程度の今回の検証で費用が跳ね上がりました。

低コストでの運用を売りにしている場合は導入は厳しいのかもしれないですね。
まとめ
DynamoDBとOpenSearch Serviceの連携を試してみました。
初回にデータの定義をちゃんとしておけば、連携が簡単にできることを確認できました。
一方で費用がそこそこかかるものなので、ある程度の規模感でないと導入するのは難しそうな印象を受けました。
We're Hiring!
私が所属している株式会社DELTAでは特定の技術にこだわらず、ユーザのニーズに合った提案を行っています。
一緒に働いてくださる仲間を大募集中です!
ご興味をお持ちいただけましたら、私に直接連絡か、お気軽にフォームからご連絡ください。

DELTAは、ベンチャースタートアップなどの成長企業向けに、ソフトウェア・プロダクト開発や技術選定支援などの技術支援事業を提供しています。 また、成長企業向けに様々な事業支援を提供するSEVENRICH GROUPに属して、グループ内の事業会社や、出資先の支援もおこなっています。
Discussion