🐒
30分でDynamoDBの仕組みをざっくり理解する
早速ですが、30分では到底無理でした。情報を少しずつ継ぎ足していきます。
DynamoDBとは
主な特徴
- マネージド型のKey-Valueデータベース
- サーバレスなので、サーバーの構築・パッチ適応・スケールが不要
- 水平型拡張性
- ストレージの容量無制限
- 高可用性=>自動的に3つのAZにデータを保存
- 外部APIから操作可能
オンデマンドモードとプロビジョンキャパシティモード
想定されるリクエストに応じた料金設定が必要
- 継続的なリクエストがある場合はプロビジョンモードの方がコスパが良い
- リクエストが常に発生しない、一度に集中する場合などはオンデマンドの方がコスパが良い
TTL(Time to Live)
- レコード毎にデータの有効期限を指定でき、その有効期限を過ぎるとデータが自動削除される
=> 不要なデータを削除する仕組みが不要になる
DAX(DynamoDB Accelerator)
- キャッシュクラスタで、読み取り性能を上げる仕組み
- Getリクエストが大量に実行される場合は、DAXによってDynamoDBテーブルへの読み取りリクエストを低減できるため、コスト低減とパフォーマンス向上に期待できる。
APIでの操作
DynamoDBテーブルへの操作はAPIを通して行われる
代表的なAPI
- PutItem(新規項目の追加)
- UpdateItem(Keyを指定して更新)
- GetItem(Keyを指定して取得)
- BatchGetItem(1回のAPIコールで複数テーブルにまたがるアイテムを取得可能)
- DeleteItem(Keyを指定して削除)
- Query(クエリ)(項目の配列を返す)
- Scan(テーブルの全項項目をスキャンする。重たいのであまり推奨はされない)
- Batch(大量データの書き込み、読み込みを行う。途中で失敗しても続ける)
- Transaction(複数のアクションをまとめてグループ化して処理する)
キーの設計
- DynamoDBはパーティションキー、ソートキーを設定できる
- パーティションキーはパーティション毎に一意であるため、プライマリキーとして使うことができる。
- ソートキーは、パーティションキーと併せて複合プライマリキーとして使われる。
- パーティションキーのみしか設定していない場合は、同じパーティションキーの項目は登録できないが、ソートキーを設定している場合は、同じパーティションキーの項目も登録できる。
(ソートキーが異なれば、別の項目として扱われる)
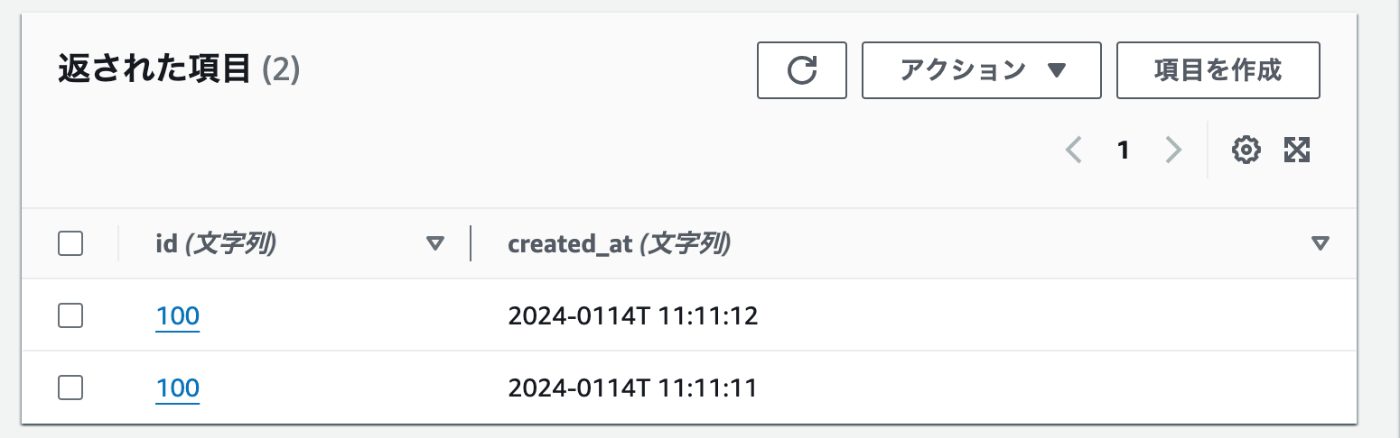
読み込みキャパシティーユニット
読み込みには2つのモードが存在する。
- 結果整合性のある読み込み(Eventually Consistent Reads)
- 強力な整合性のある読み込み(Strongly Consistent Reads)
デフォルトでは、「結果整合性のある読み込み」となっており、getやqueryのオプションでConsistentRead 属性を true にすることで、「強力な整合性のある読み込み」を行う。しかし、 グローバルセカンダリインデックス (GSI) では利用できない。
⚫︎クエリオペレーション vs スキャンオペレーション
=> クエリオペレーションの方が読み込み消費量は低い
⚫︎結果整合性 vs 強力な整合性
=> 結果整合性の方が読み込み消費量は低い
※ 結果整合性のある読み込みを利用すると、直近の書き込みオペレーションの結果が反映されていないことがある。
セカンダリインデックス
-
グローバルセカンダリインデックス(GSI) ・・・プライマリキーと別の属性を使って作成するインデックス
-
ローカルセカンダリインデックス(LSI) ・・・テーブルと同じパーティション内で検索
-
GSIはパーティションキー or パーティションキー/ソートキーが異なるインデックスとなり、全てのパーティションにまたがるインデックス。
-
LSIはパーティションキーは同じだが、ソートキーが異なるインデックス。
-
GSIはテーブル作成後でも設定可能だが、LSIはテーブルを作成するときに設定する必要がある。
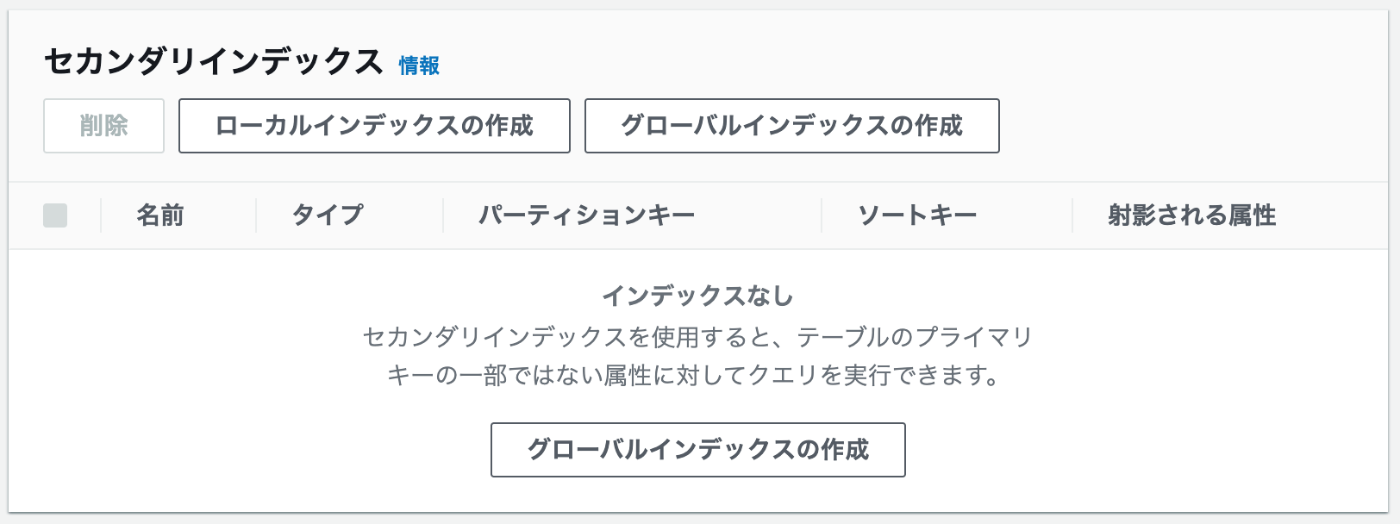
ローカルセカンダリインデックス設定
テーブル作成時に設定したパーティションキーはそのままに、ソートキーのみテーブル作成時に設定したキーとは別のキーを設定する仕組み。
-
新規テーブル作成時のみ、下記のようにローカルインデックスの作成が可能。
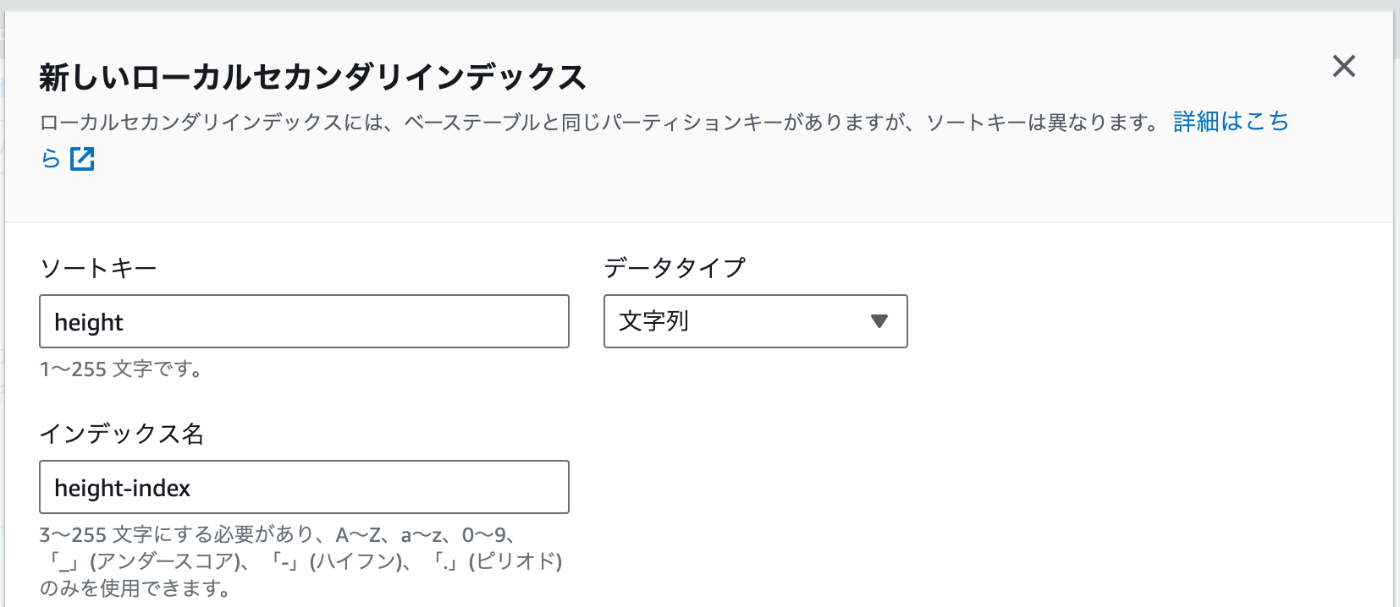
-
ローカルインデックスのソートキーを指定する
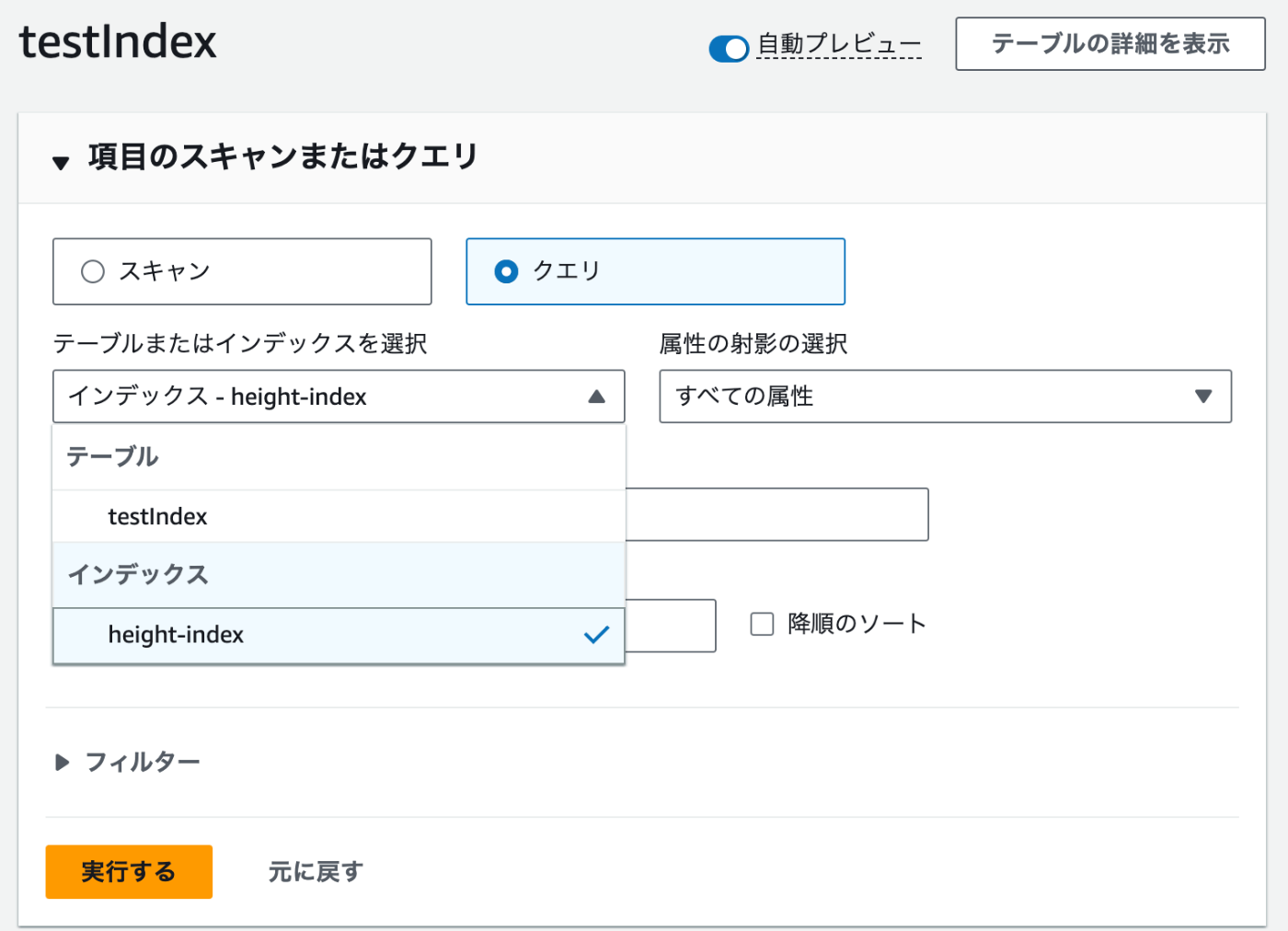
-
クエリを実行する際に、インデックスを指定できるようになる。これで検索性能が向上できる可能性がある。
#参考資料
Discussion