3DOIをgoogle colabで試してみた。



3DOIとは
3DOIとは画像内で指定したポイントにあるObjectに対して人間がどのようなアクションを起こせるのかを推薦する3D Object InteractionのAIモデルです。
リンク
準備
Google Colabを開き、メニューから「ランタイム→ランタイムのタイプを変更」でランタイムを「GPU」に変更します。
環境構築
huggingfaceにDemoが紹介されているので試したい方はそちらでも大丈夫です。今回は実際に自分のgoogle colabでも動かしてみます。
インストール手順です。
!git clone https://huggingface.co/spaces/shengyi-qian/3DOI
!pip install gradio
推論
(1)WebUIの起動
最初にapp.pyの一番下の行のdemo.launch(*****)を以下のように書き換えます。
demo.launch(share=True)
その後以下のコードを実行してください。
%cd /content/3DOI
!python app.py
(2)サンプルの結果。
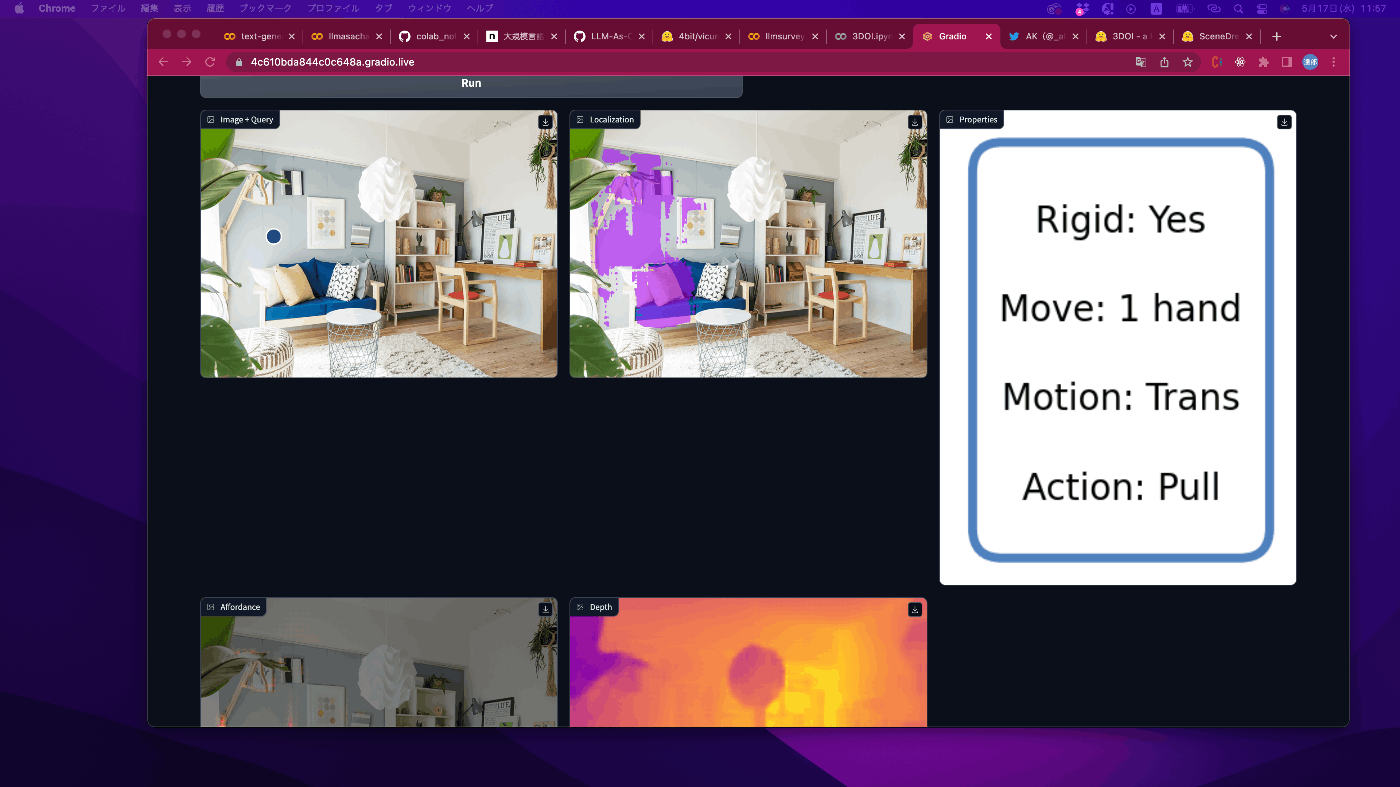
洗濯物籠のところにポイントを打ってみました。
画像のところに点を打ってRunを押すと以下のような結果が出てきます。

なるほどいい感じですね。
(3)お部屋の画像
椅子のところに打ってみました。なるほど

ソファもそりゃそうって感じ?
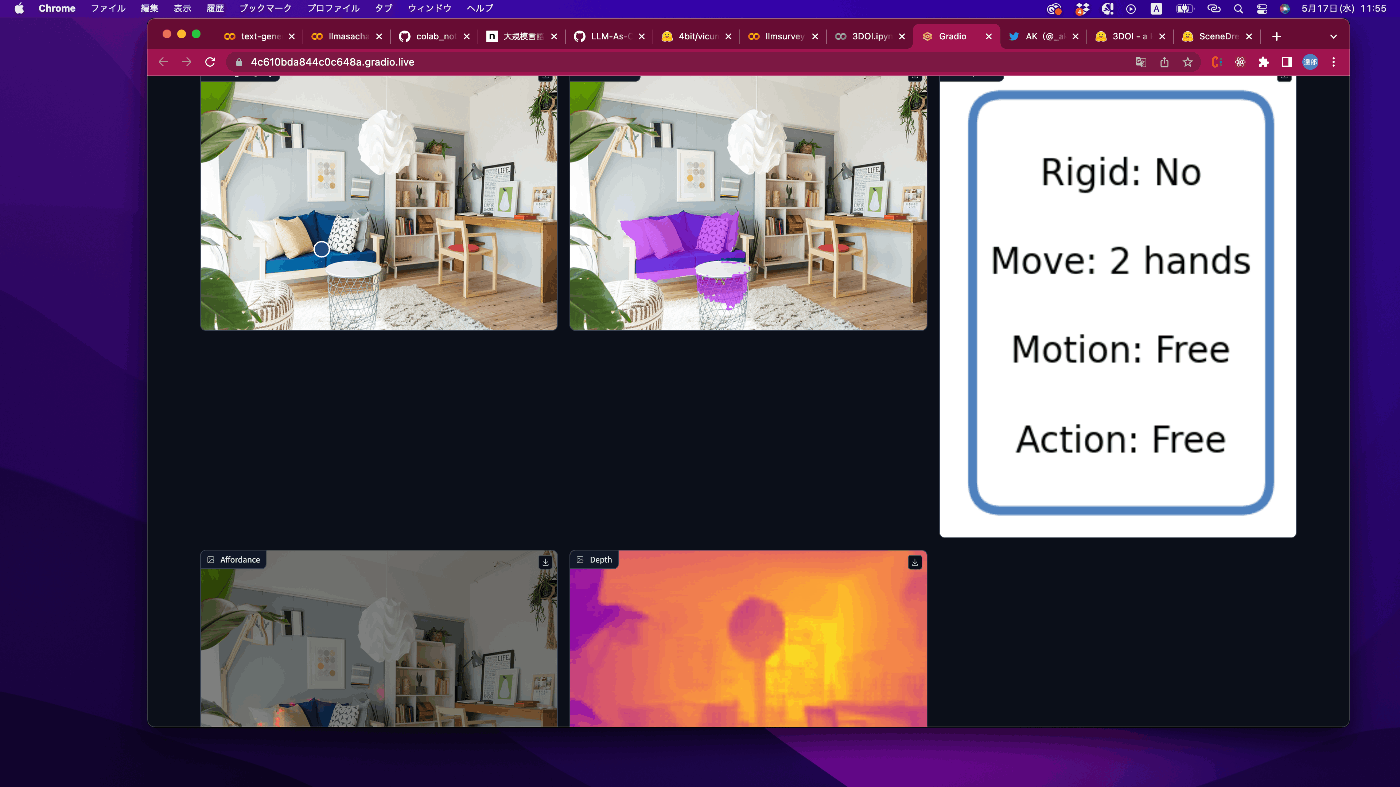
壁はどうか
微妙な感じですね。
本棚とか絵は動かせるよって出ました!
ちょっとなにに使えるのかはあんまりパッと思い浮かばないけどActionと検出が結びついてきているというのはいいことですね。
最後に
今回は画像内のObjectとそれに対する人間が可能そうなアクションを推薦する3DOIというAIモデルを試してみました。Action recognitionとObject detection+Semantic Segmentationとかが組み合わさったモデルがいよいよ登場してきましたね!応用していくとStable diffusionとかとアニメーション作成が可能になったり、データセットをスポーツ用に変更したりすればスポーツとかでも利用可能な場面が出てきそう。
自分的には新しい概念だったので試してみて面白かったです。
今後ともLLM, Diffusion model, Image Analysis, 3Dに関連する試した記事を投稿していく予定なのでよろしくお願いします。
Discussion