UniControlnetをgoogle colabで試してみた。
UniControlNetとは
UniControlNetはControlNetで出来る画像変換を一度にやってしまえる、multiControlNetの拡張版のControlNetです。それぞれの画像(人間、動物、背景等)はControlNetのどの前処理を利用するかで大きくクオリティが変化しましたが、その強みを活かせるモデルが降臨しました。
リンク
準備
Google Colabを開き、メニューから「ランタイム→ランタイムのタイプを変更」でランタイムを「GPU」に変更します。
環境構築
インストール手順です。
!git clone https://github.com/ShihaoZhaoZSH/Uni-ControlNet.git
!pip install gradio==3.16.2 albumentations==1.3.0 \
imageio==2.9.0 \
imageio-ffmpeg==0.4.2 \
pytorch-lightning==1.6.0 \
omegaconf==2.1.1 \
test-tube==0.7.5 \
streamlit==1.12.1 \
einops==0.3.0 \
transformers==4.19.2 \
webdataset==0.2.5 \
kornia==0.6 \
open_clip_torch==2.0.2 \
invisible-watermark==0.1.5 \
streamlit-drawable-canvas==0.8.0 \
torchmetrics==0.7.0 \
timm==0.6.12 \
addict==2.4.0 \
yapf==0.32.0 \
prettytable==3.6.0 \
safetensors==0.2.7 \
basicsr==1.4.2 \
datasets==2.10.1 \
pathlib==1.0.1
ただ上記のインストールだとエラーが出たりするので、以下のインストールも実行してください。
!pip install git+https://github.com/arogozhnikov/einops.git
!pip install xformers
推論
(1)モデルのダウンロード
# download models
!wget https://huggingface.co/shihaozhao/uni-controlnet/resolve/main/uni.ckpt -P ckpt
(2)WebUIの起動
%cd /content/Uni-ControlNet
!python src/test/test.py
起動後の画面です。

(3)推論
UniControlNetのgithubのサンプルを利用します。
(3-1) single conditions
ロードできたけどダメそうだーー、、
推論時にOOMで死んで舞いますね、、
ダメだったので少しコードと設定を改変してみます。読み込む前処理モデルを選択式にしてロードし、defaultで設定されていたnum_samples(images)の数を1に下げてみました。
コードは以下の通りです。
model_selected = ["hed", "sketch", "midas", "content"] # "canny", "mlsd", "openpose", "seg"
%cd /content/Uni-ControlNet
from utils.share import *
import utils.config as config
import cv2
import einops
import gradio as gr
import numpy as np
import torch
from pytorch_lightning import seed_everything
from annotator.util import resize_image, HWC3
from annotator.canny import CannyDetector
from annotator.mlsd import MLSDdetector
from annotator.hed import HEDdetector
from annotator.sketch import SketchDetector
from annotator.openpose import OpenposeDetector
from annotator.midas import MidasDetector
from annotator.uniformer import UniformerDetector
from annotator.content import ContentDetector
from models.util import create_model, load_state_dict
from models.ddim_hacked import DDIMSampler
if "canny" in model_selected:
apply_canny = CannyDetector()
else:
apply_canny = None
if "mlsd" in model_selected:
apply_mlsd = MLSDdetector()
else:
apply_mlsd = None
if "hed" in model_selected:
apply_hed = HEDdetector()
else:
apply_hed = None
if "sketch" in model_selected:
apply_sketch = SketchDetector()
else:
apply_sketch = None
if "openpose" in model_selected:
apply_openpose = OpenposeDetector()
else:
apply_openpose = None
if "midas" in model_selected:
apply_midas = MidasDetector()
else:
apply_midas = None
if "seg" in model_selected:
apply_seg = UniformerDetector()
else:
apply_seg = None
if "content" in model_selected:
apply_content = ContentDetector()
else:
apply_content = None
model = create_model('./configs/uni_v15.yaml').cpu()
model.load_state_dict(load_state_dict('./ckpt/uni.ckpt', location='cuda'))
model = model.cuda()
ddim_sampler = DDIMSampler(model)
def process(canny_image, mlsd_image, hed_image, sketch_image, openpose_image, midas_image, seg_image, content_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta, low_threshold, high_threshold, value_threshold, distance_threshold, alpha, global_strength):
seed_everything(seed)
if canny_image is not None:
anchor_image = canny_image
elif mlsd_image is not None:
anchor_image = mlsd_image
elif hed_image is not None:
anchor_image = hed_image
elif sketch_image is not None:
anchor_image = sketch_image
elif openpose_image is not None:
anchor_image = openpose_image
elif midas_image is not None:
anchor_image = midas_image
elif seg_image is not None:
anchor_image = seg_image
elif content_image is not None:
anchor_image = content_image
else:
anchor_image = np.zeros((image_resolution, image_resolution, 3)).astype(np.uint8)
H, W, C = resize_image(HWC3(anchor_image), image_resolution).shape
with torch.no_grad():
if canny_image is not None:
canny_image = cv2.resize(canny_image, (W, H))
canny_detected_map = HWC3(apply_canny(HWC3(canny_image), low_threshold, high_threshold))
else:
canny_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if mlsd_image is not None:
mlsd_image = cv2.resize(mlsd_image, (W, H))
mlsd_detected_map = HWC3(apply_mlsd(HWC3(mlsd_image), value_threshold, distance_threshold))
else:
mlsd_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if hed_image is not None:
hed_image = cv2.resize(hed_image, (W, H))
hed_detected_map = HWC3(apply_hed(HWC3(hed_image)))
else:
hed_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if sketch_image is not None:
sketch_image = cv2.resize(sketch_image, (W, H))
sketch_detected_map = HWC3(apply_sketch(HWC3(sketch_image)))
else:
sketch_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if openpose_image is not None:
openpose_image = cv2.resize(openpose_image, (W, H))
openpose_detected_map, _ = apply_openpose(HWC3(openpose_image), False)
openpose_detected_map = HWC3(openpose_detected_map)
else:
openpose_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if midas_image is not None:
midas_image = cv2.resize(midas_image, (W, H))
midas_detected_map = HWC3(apply_midas(HWC3(midas_image), alpha))
else:
midas_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if seg_image is not None:
seg_image = cv2.resize(seg_image, (W, H))
seg_detected_map, _ = apply_seg(HWC3(seg_image))
seg_detected_map = HWC3(seg_detected_map)
else:
seg_detected_map = np.zeros((H, W, C)).astype(np.uint8)
if content_image is not None:
content_emb = apply_content(content_image)
else:
content_emb = np.zeros((768))
detected_maps_list = [canny_detected_map,
mlsd_detected_map,
hed_detected_map,
sketch_detected_map,
openpose_detected_map,
midas_detected_map,
seg_detected_map
]
detected_maps = np.concatenate(detected_maps_list, axis=2)
local_control = torch.from_numpy(detected_maps.copy()).float().cuda() / 255.0
local_control = torch.stack([local_control for _ in range(num_samples)], dim=0)
local_control = einops.rearrange(local_control, 'b h w c -> b c h w').clone()
global_control = torch.from_numpy(content_emb.copy()).float().cuda().clone()
global_control = torch.stack([global_control for _ in range(num_samples)], dim=0)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
uc_local_control = local_control
uc_global_control = torch.zeros_like(global_control)
cond = {"local_control": [local_control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)], 'global_control': [global_control]}
un_cond = {"local_control": [uc_local_control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)], 'global_control': [uc_global_control]}
shape = (4, H // 8, W // 8)
if config.save_memory:
model.low_vram_shift(is_diffusing=True)
model.control_scales = [strength] * 13
samples, _ = ddim_sampler.sample(ddim_steps, num_samples,
shape, cond, verbose=False, eta=eta,
unconditional_guidance_scale=scale,
unconditional_conditioning=un_cond, global_strength=global_strength)
if config.save_memory:
model.low_vram_shift(is_diffusing=False)
x_samples = model.decode_first_stage(samples)
x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)
results = [x_samples[i] for i in range(num_samples)]
return [results, detected_maps_list]
block = gr.Blocks().queue()
with block:
with gr.Row():
gr.Markdown("## Uni-ControlNet Demo")
with gr.Row():
canny_image = gr.Image(source='upload', type="numpy", label='canny')
mlsd_image = gr.Image(source='upload', type="numpy", label='mlsd')
hed_image = gr.Image(source='upload', type="numpy", label='hed')
sketch_image = gr.Image(source='upload', type="numpy", label='sketch')
with gr.Row():
openpose_image = gr.Image(source='upload', type="numpy", label='openpose')
midas_image = gr.Image(source='upload', type="numpy", label='midas')
seg_image = gr.Image(source='upload', type="numpy", label='seg')
content_image = gr.Image(source='upload', type="numpy", label='content')
with gr.Row():
prompt = gr.Textbox(label="Prompt")
with gr.Row():
run_button = gr.Button(label="Run")
with gr.Row():
with gr.Column():
with gr.Accordion("Advanced options", open=False):
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=4, step=1)
image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=512, step=64)
strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=0.75, step=0.01)
global_strength = gr.Slider(label="Global Strength", minimum=0, maximum=2, value=1, step=0.01)
low_threshold = gr.Slider(label="Canny Low Threshold", minimum=1, maximum=255, value=100, step=1)
high_threshold = gr.Slider(label="Canny High Threshold", minimum=1, maximum=255, value=200, step=1)
value_threshold = gr.Slider(label="Hough Value Threshold (MLSD)", minimum=0.01, maximum=2.0, value=0.1, step=0.01)
distance_threshold = gr.Slider(label="Hough Distance Threshold (MLSD)", minimum=0.01, maximum=20.0, value=0.1, step=0.01)
alpha = gr.Slider(label="Alpha", minimum=0.1, maximum=20.0, value=6.2, step=0.01)
ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=50, step=1)
scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=7.5, step=0.1)
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, value=42, step=1)
eta = gr.Number(label="Eta (DDIM)", value=0.0)
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, extremely detailed')
n_prompt = gr.Textbox(label="Negative Prompt",
value='longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality')
with gr.Row():
image_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=4, height='auto')
with gr.Row():
cond_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=4, height='auto')
ips = [canny_image, mlsd_image, hed_image, sketch_image, openpose_image, midas_image, seg_image, content_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, strength, scale, seed, eta, low_threshold, high_threshold, value_threshold, distance_threshold, alpha, global_strength]
run_button.click(fn=process, inputs=ips, outputs=[image_gallery, cond_gallery])
# block.launch(server_name='0.0.0.0')
block.launch(share=True, debug=True)
これならsingle_condition/case1実行できました!

次にsingle_condition/case2を試してみます。
model_selected = [ "seg" ]と変更してみてください。
実行できました!

(3-2)multi condition
最後にmulti_condition/case3をやってみます。
model_selected = ["hed", "sketch", "midas", "content"]
推論時のインプット画面はこんな感じ
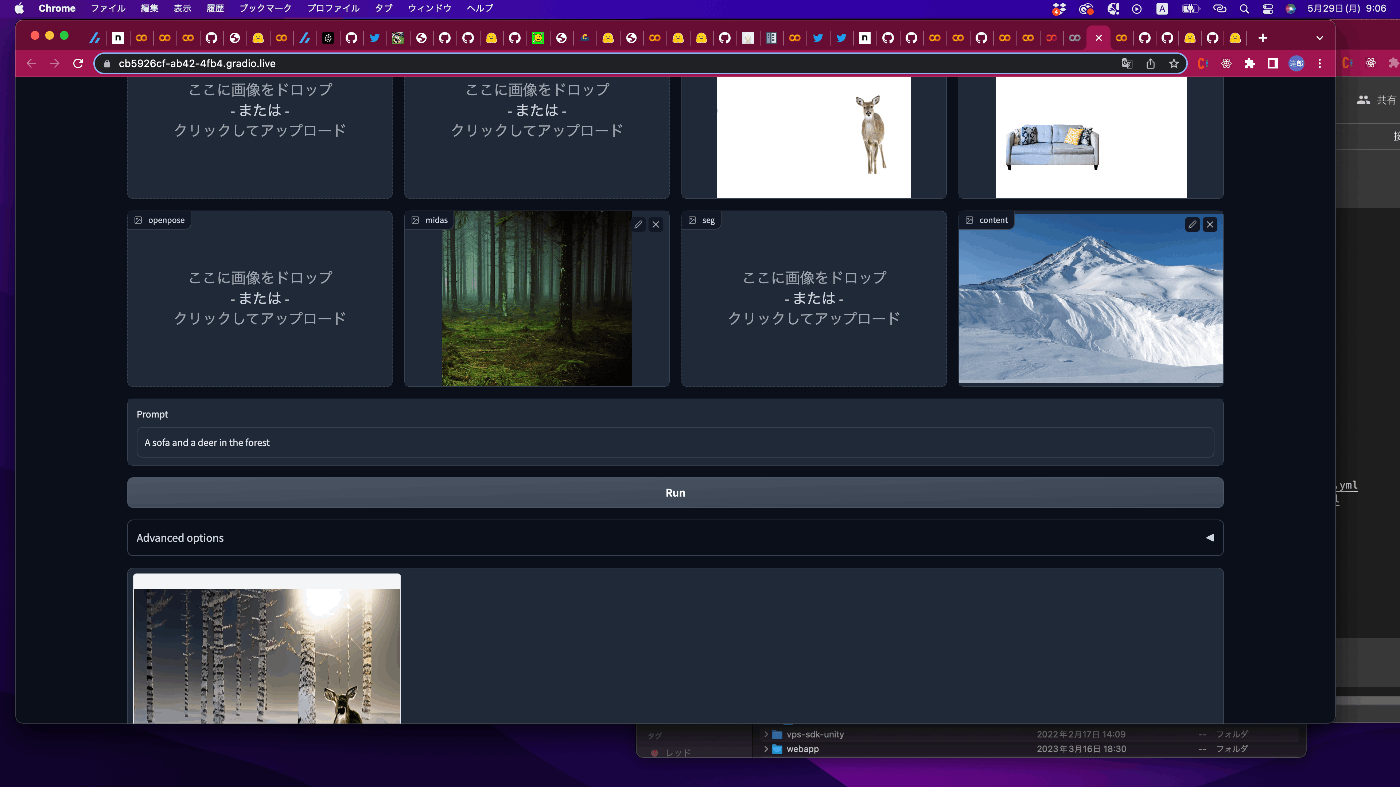
おーーー推論できた!
結果はこんな感じ!

最後に
今回はControlNet、MultiControlNetの派生系でAdvancedであるUniControlNetを試してみました。最初はOOMで死んで、くっそー試せないんかと頭を抱えましたが、実際にうまく治して試せて非常に面白かったです。これは流石に色々なところで適用できそうな気しかしないです。
今後ともLLM, Diffusion model, Image Analysis, 3Dに関連する試した記事を投稿していく予定なのでよろしくお願いします。
Discussion