論文紹介 : Eyes Wide Shut?

概要
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs という論文を読んだので紹介します。
マルチモーダルモデルにおける近年の進歩は主に大規模言語モデル(LLM)の強力な推論能力によるものです。視覚的な要素は対照的な言語・画像事前学習モデル(CLIP)に依存しています。筆者らの研究は、最近のマルチモーダルLLM(MLLM)の視覚能力が系統的な欠陥を持っていることを明らかにしました。
これらのエラーの原因を理解するために、CLIPの視覚的埋め込み空間と、視覚のみの自己教師付学習(DINOv2など)との間のギャップを調べました。筆者らはこのギャップを使ってCLIP-blind pairsを作成しました。このペア画像には明確な視覚的差異があるにも関わらず、CLIPはペア画像を類似していると認識します。これらのペア画像を用いて、MMVP(Multimodal Visual Patterns)ベンチマークを構築しました。MMVPによって、GPT-4Vを含む最新のMLLMが9つの基本的な視覚的パターンにまたがる簡単な質問に悩まされ、不正解になる領域を明らかにします。
著者らはこの問題を解決するために、Mixture of Features(MoF)アプローチを提案しました。ビジョン付きの自己教師付き特徴量をMLLMと統合することで、その視覚的根拠付け能力を大幅に向上させることができることを実証しました。この研究は、視覚表現学習が依然として未解決の課題であり、将来のマルチモーダルシステムにとって、正確な視覚基盤が重要であることを示しました。

図1はGPT-4Vが視覚的質問応答(VQA)において苦戦するケースを示したものです。これらの質問は一見簡単ですが、GPT-4Vは正解することができません。図の赤のテキストは誤答を、緑のテキストはハルシネーションを示しています。
MMVP(Multimodal Visual Patterns)ベンチマーク
CLIP-blindペア
CLIP視覚エンコーダーが「適切に」エンコードするのに苦労している画像を直接見つけるのは困難です。既存研究のアイデアを拡張することで、このブラインドペアを自動的に見つけられるようにしました。図2のStep1を見てください。2つの画像をCLIPとDINOv2で埋め込み表現に変換しています。CLIPでは2つの画像の埋め込みはかなり近くなりますが、DINOv2での結果は異なっています。このようにCLIPは同じとみなすが、他の視覚モデルは異なると判断する画像のペアをブラインドペアとしました。

コーパスデータセットである、ImageNetとLAIONAestheticsを用いて、これらのCLIP-blindペアを収集しました。CLIPの埋め込みでは0.95以上、DINOv2の埋め込みでは0.6以下のコサイン類似度をもつペアを収集しました。
収集したブラインドペアを用いて300問の問題を作成しました。このペアに対して、CLIPが見落としている視覚的詳細を手動でピンポイントで特定し、これらの視覚的詳細を探る質問を作成します。図2のStep2では「黄色い動物の頭部がどこに横たわっているか?(a)床 (b)カーペット」のような問題を作成します。
ベンチマーク結果
SOTAオープンソースモデル(LLaVA-1.5, InstructBLIP, Mini-GPT4)、クローズドなモデル(GPT-4V, Gemini, Bard)で質問を評価しました。任意のペアに対して、両方の質問に正確に答えられる場合のみ、正解とみなしました。
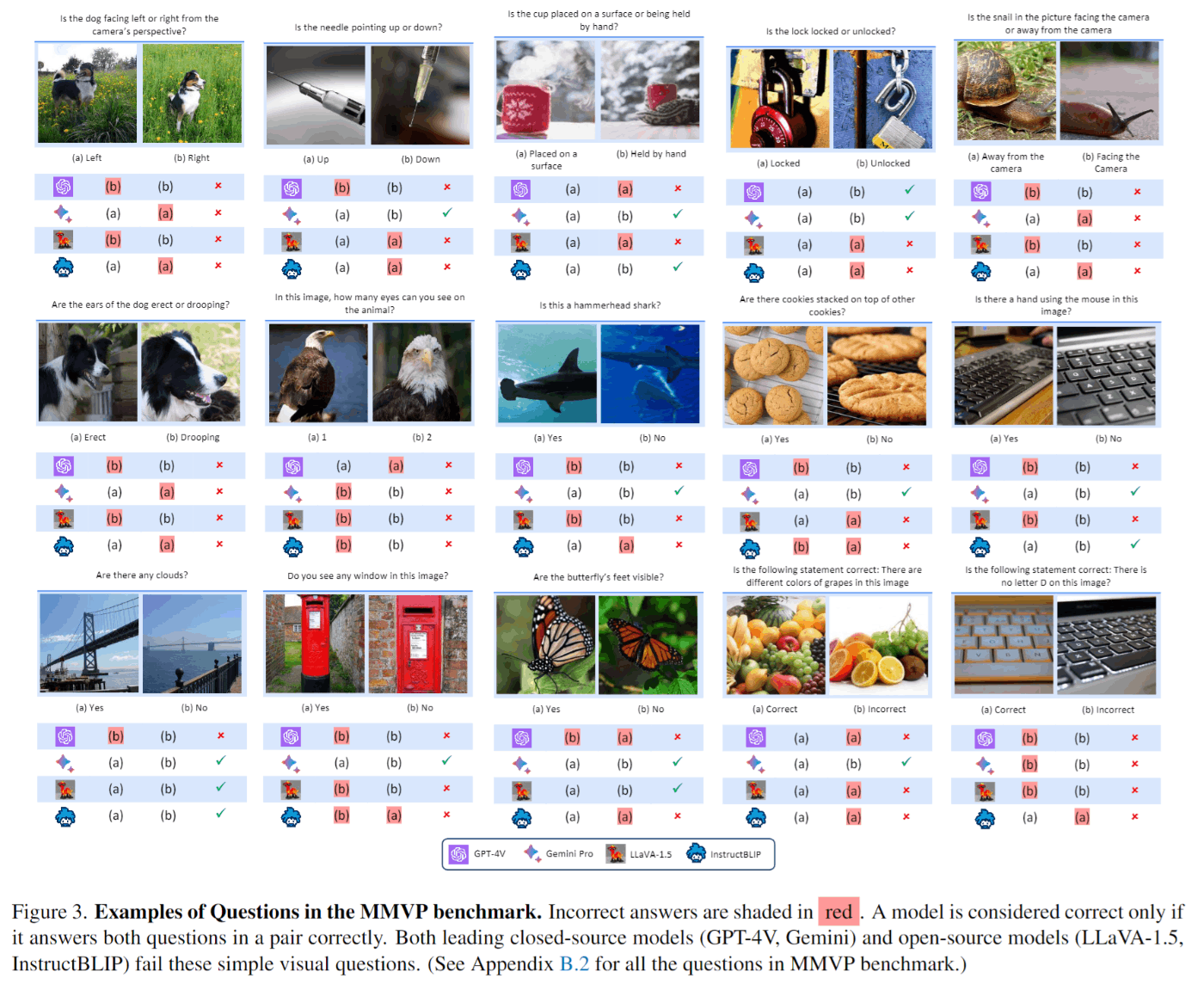
図3はMMVPベンチマークの質問と結果です。SOTAのモデルでも失敗している問題が多いことがわかります。
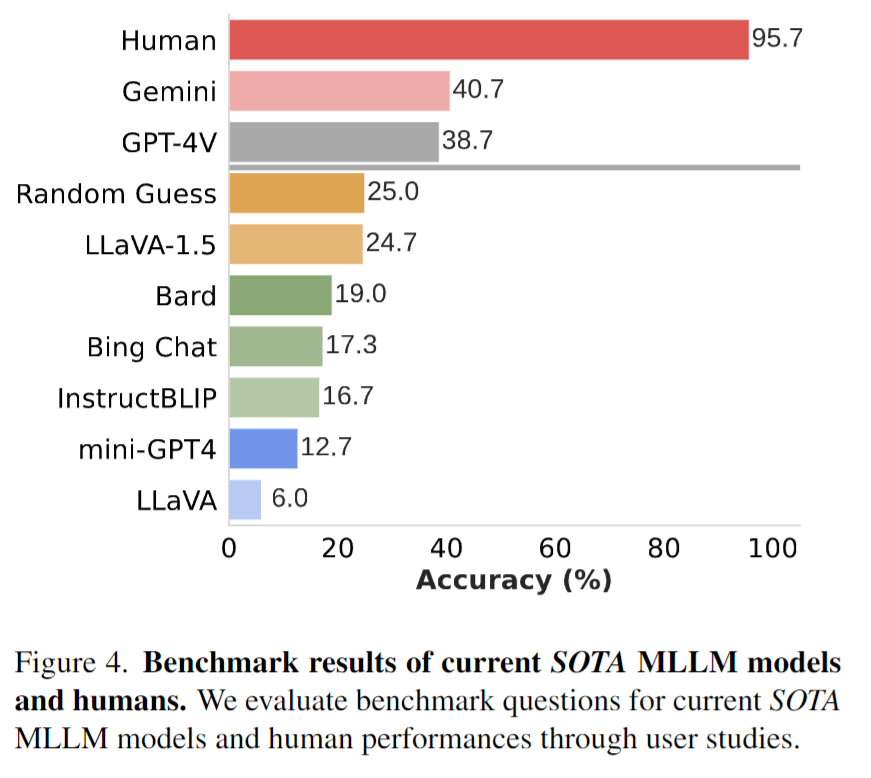
人間による調査では、質問が簡単であることが確認されています。図4に示すように人間の参加者は平均95.7%の質問に正確に回答しています。
CLIPにおける系統的な失敗例
MMVPベンチマークで失敗するケースを系統的な視覚パターンを要約します。こちらの研究ではGPT-4を用いて一般的なパターンを以下のように促して分類しました。今回は下の画像のように9つのパターンに分類しました。

MMVPベンチマークの質問を9つのパターンに分割しました。各パターンについてバランスがとれるように質問を追加して、各パターンが15のテキストと画像のペアで表現されるようにしました。分類パターンとペア画像の例を図5に示します。
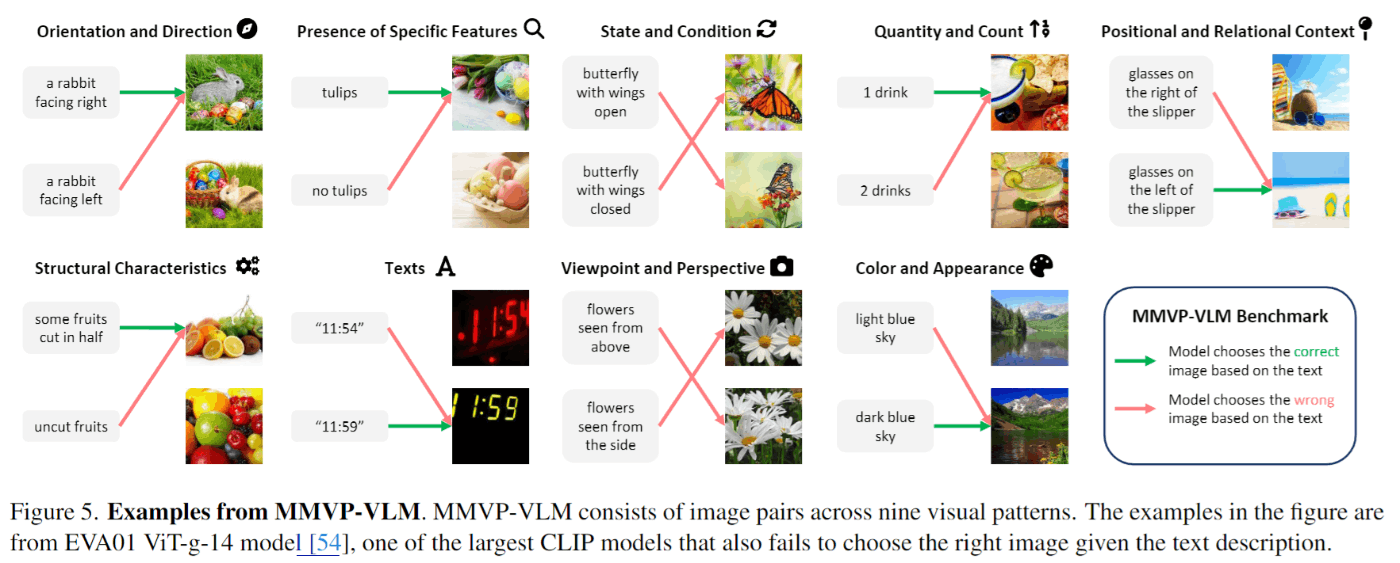
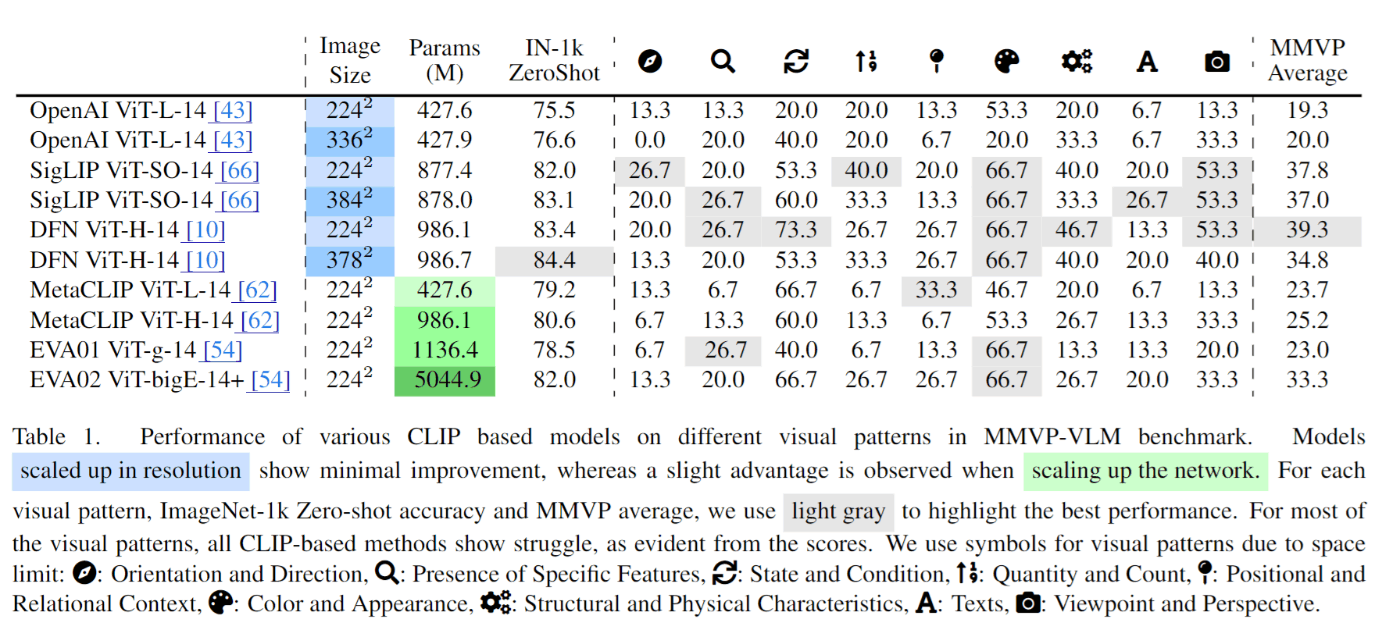
表1はパターンごとの正解率です。これによると「color and appearance」「state and conditio」の2つのパターン以外ではCLIPが苦戦していることがわかります。
MLLMの混合特徴量(MoF)
より有能な視覚エンコーダーを構築するにはどうしたらいいでしょうか? ここではMixture of Features(MoF)を研究します。まず、CLIPと教師あり視覚モデルの特徴量を混在させたAdditive MoFから始めます。次に両方の特徴をMLLMに統合し、モデルの指示に従く能力を損なうことなく、視覚的な根拠づけを強化するInterleaved MoFを提案します。
Additive MoF
CLIPとDINOv2の特徴量をαと1-αで線形に加算します。DINOv2の比率を0.0, 0.25, 0.50, 0.75, 1.0と変化させて測定しました。このとき、MMVPによる視覚的能力と、LLaVAベンチマークを用いたモデルの指示追従能力を評価しました。この結果が表2です。DINOv2の特徴量の割合が増加すると、MLLMは命令追従性が低下します。DINOv2の割合が87.5%を超えると、急激に減少することがわかりました。DINOv2の割合が高いほど、モデルの視覚的根拠づけ能力は向上しますが、DINOv2比率が0.75を超えるとこの優位性は弱くなります。

Interleaved MoF
著者らはCLIPとDINOv2の両方の埋め込みの利点を活用し、画像表現を強化するために、インターリーブMoFを提案します。画像は同時にCLIPとDINOv2エンコーダーに渡され、得られた埋め込みは個々にアダプターによって処理されます。CLIPとDINOv2から処理された特徴を取り出し、元の空間順序を維持したままインターリーブします。次にインターリーブされた特徴量をLLMに与えます。図7の左がインターリーブMoFの構成です。

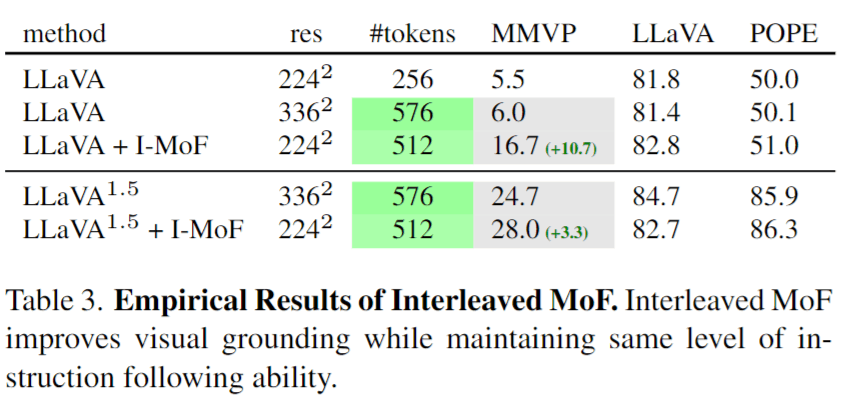
表3はインターリーブMoFの結果です。こちらは同じレベルの指示追従能力を維持したまま、視覚的な根拠付け能力を改善します。
ディスカッション
最初の問いかけに戻ると、視覚は言語にとって十分でしょうか? MLLMは、事前に学習したCLIPビジョンエンコーダーが、画像中の重要な視覚的詳細を見落とし、単純な問題でも失敗します。しかし、CLIPタイプのモデルは、今日でも最もスケーラブルで広く使われています。データとモデルのスケーリングは万能であるという一般的な考えとは逆に、著者らの研究は、スケーリングだけではCLIPモデルに内在する欠陥を是正できないことを実証しています。
本研究により、一般的な視覚表現学習モデルである視覚言語モデルと、視覚のみの自己教師付き学習モデルが、それぞれ異なる側面で優れていることが明らかなりました。Mixture-of-Featuresのアプローチは、視覚的な制限を緩和し、これら2つの学習パラダイムの長所を活かすことができるが、新しい視覚表現学習アルゴリズムの開発を促進するための新しい評価指標を開発することが必要です。著者らは、当研究がビジョンモデルにおける更なるイノベーションの動機付けとなることを期待しています。
論文を読んだ感想
マルチモーダルモデルの欠陥については他の研究でも指摘されています。物体の位置や向きに関する情報はCLIPの学習データに含まれていないので、理解することが難しいと言われています。一方、CLIPタイプのモデルは広く使われているので、他のモデルに変更することは難しそうです。CLIPの学習データを改善することで性能を向上させていくのがシンプルな解決方法ではないかと思いました。
Discussion