CartoonSegmentationの論文を読んでみた


概要
最近話題になっているCartoonSegmentationというモデルの元論文「Instance-guided Cartoon Editing with a Large-scale Dataset」を読んでみました。長いので以下ではCartoonSegmentationと呼びます。
CartoonSegmentationはアニメ・漫画などの画像に特化したセグメンテーションマスクを生成するモデルです。論文を読んだところ高品質のデータセットを新しく作っているのが最大のコントリューションだと思いました。今回はこのデータセット作成の部分について説明してみます。
データセットについて
漫画・アニメに特化したセグメンテーション用のデータセットはいくつか存在するのですが、非公開だったり数が足りなかったりするのでCartoonSegmentationでは新しくデータセットを作成しました。
前景と後景の画像の調達
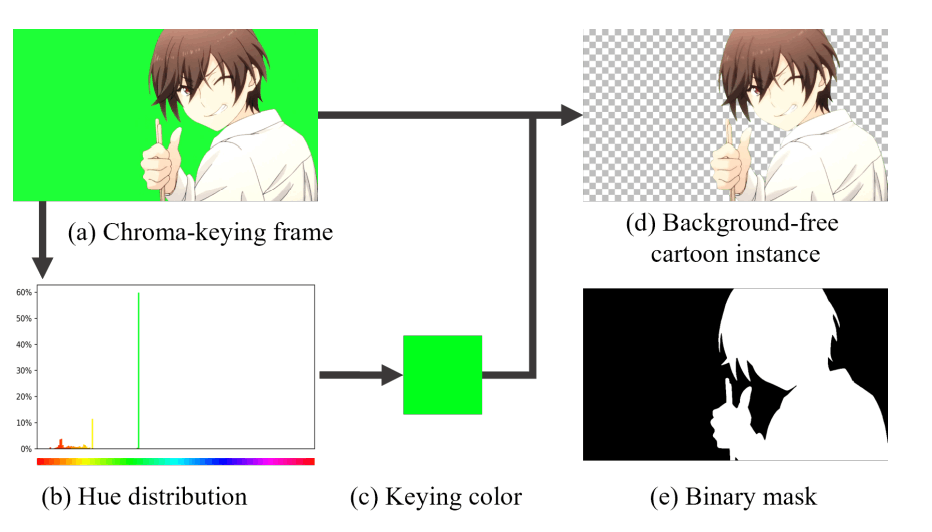
データセットは前景(キャラクター)と後景(背景)を合成して作成します。まず前景ですが、こちらは背景が透過されたキャラクターの画像が必要です。こちらの研究ではニコニコ、ビリビリ、Youtubeなどからクロマキービデオを収集して透過画像を作成しました。また追加でDanbooru2021の静止画も利用しています。ここでは「solo」「transparent_background」タグの付いた画像を利用しています。クロマキービデオから26,844枚、Danbooruから38,908枚の合計65,752枚を用意しました。
後景はDanbooru2021データセットの8,163枚利用しました。これは「scenery」「no_humans」タグを使って取り出しました。またbizarre pose estimatorから背景画像を8057枚取り出しています。
前景と後景の合成
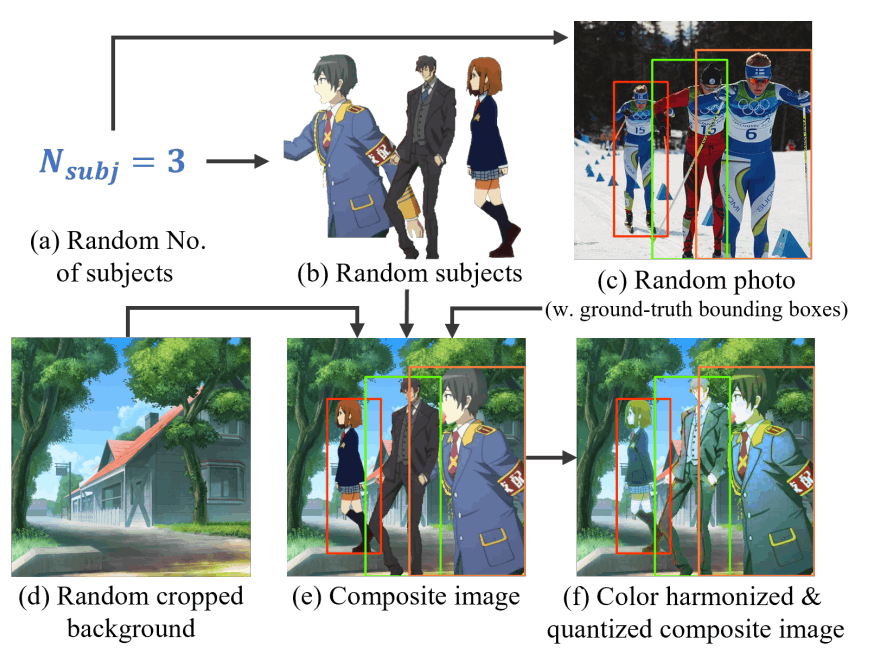
個人的はこの部分が一番工夫されていると思いました。前景と後景を合成するのですが、ランダムに配置するとまばらな配置になったり、混雑した配置になってしまいます。そこで配置のための参照画像を用意して、同じような配置になるように前景のキャラクターを置いていきます。実際にはMSCOCOデータセットからランダムに画像を取り出して(c)、そのバウンディングボックスとできるだけ近くなるように前景のキャラクターを配置します(e)。配置するキャラクターの人数はポアソン分布でばらつくようにしています。
このままでは前景と後景のトーンが違うのでいかにも合成しているように見えてしまいます(e)。後処理としてヒストグラムマッチングを行っています(f)。後処理はsupplemental materialに詳細が記載されているそうなのですが、こちらは見つけられませんでした。
データセットの公開について
こちらのデータセットはまだ非公開です。論文がアクセプトされたら公開されるそうです。ライセンスまわりがどうなるのか気になるところです。NC(商用利用不可)かなぁ・・・
Discussion