論文紹介 : Octopus v2


概要
Octopus v2: On-device language model for super agentというVLMの論文を読んだので面白かった点だけに絞って紹介します。スタンフォード大学の研究です。
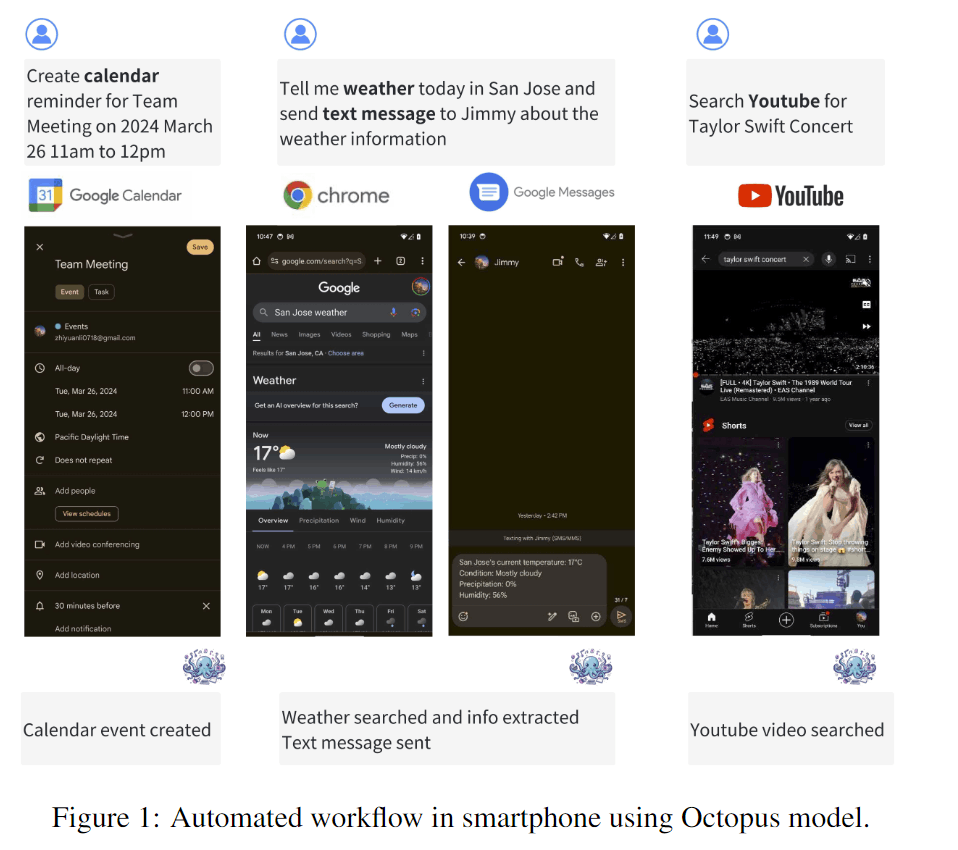
著者らはスマートフォンなどのエッジデバイスで動作するAIエージェントとしてOctopus v2を開発しました。AIエージェントとしてはGPT4などを使うこともできるのですが、プライバシーとコストが問題になります。AIボットとの1時間にわたるインタラクションをGPT4で行う場合、0.24ドルのコストになります。
コストを軽減しつつ、プライバシーを強化するためにはスマートフォンなどのエッジデバイス上で動作する小型のモデルを開発する必要があります。しかしエッジデバイスで大きなLLMを動作させる場合はバッテリーの寿命が問題となります。1BパラメータのLLMを動かす場合、1トークン当たりのエネルギー消費量は0.1Jとなります。従来のRAGに7Bのモデルを利用すると、1回の呼び出しに700J使うことになり、iPhoneの50kJのバッテリーの1.4%を消費します。つまり71回しか呼び出せません。
著者らはエッジデバイス上で動作する2Bモデルを開発しました。こちらはAIエージェントとしての関数呼び出しの精度と、レイテンシの両方を向上させ、SOTAを達成しました。提案手法ではよく使う関数の名前をトークン化し、この「関数トークン」を使ってモデルをファインチューニングします。この関数トークンを使うことで推論時のコンテキスト長を95%以上節約することができます。提案手法ではGemma2Bをファインチューニングすることで、GPT4に対してバッテリー消費を37倍抑え、レイテンシが35倍改善しました。
方法
この論文では「関数トークン」の部分がかなり独自性があるので、そこを紹介します。AIエージェントはユーザーの入力(例:カレンダーにイベントを登録してください)に対して、適切なスマートフォンの関数を呼び出します。入力に対して、どの関数(API)を呼び出すか?、関数の引数はなにか?をLLMで推論します。LLMで呼び出す関数名を推論する場合、1つの関数名に対して複数のトークンを使う必要があります。また複数トークンを使うことで不正確な関数名となってしまう恐れがあります。
著者らは関数をユニークな「関数トークン」として指定することを提案します。例えばN個の関数プールにおいて<nexa_0>から<nexa_N-1>までのトークン名を割り当てます。これにより関数名の予測タスクを、N個の関数トークン間の1トークン分類タスクに変換します。関数名の予測精度を向上させると同時に、必要なトークン数を減らすことができます。この特殊トークンを扱うためにトーカナイザーへ追加して、事前学習を行います。
まとめ
論文の残りの部分ではAndroid APIに関数トークンを割り当てて呼び出せるようにした点、GPT3.5, GPT4との精度とレイテンシの比較などが書かれています。
Discussion