論文紹介 : MMBench
概要
MMBench: Is Your Multi-modal Model an All-around Player? という論文を読んだので、面白かったところに絞って紹介します。
MMBenchはビジョン言語向けの新しいベンチマークです。特徴は次の2つです。評価質問数と多様な能力の点で既存の類似ベンチマークを凌駕します。二つ目の要素は新しいCircularEval戦略を紹介し、ChatGPTを評価のためのツールとして導入しています。これにより、モデルの自由形式の予測をあらかじめ定義された選択に変換することで、モデルの予想をよりロバストに評価できるように設計されています。
既存ベンチマークには以下のような問題があります。
- モデルの予測が「bicycle」でVLMの回答が「bike」であったとしても不正解となってしまい、かなりの数の偽陰性サンプルとなります
- 現在の公開データセットは、主に特定のタスクに対するモデルの性能を評価することに重点を置いており、これらのモデルのきめ細やかな能力に関する洞察は限られています。
これらの問題に対して、最近の研究では評価プロセスに人間の判断や知覚を取り入れることで、人間が関与した主観評価戦略を提案しています。しかし人間の主観的評価には別の問題があります。第一に人間の評価は本質的に偏っています。その結果、異なるアノテーションデータグループによる論文で示された結果を再現することは困難です。また既存の主観評価戦略では、スケーラビリティの問題に直面しています。各実験の後、モデル評価のためにアノテーターを採用するのは大変な労力です。さらに小規模な評価データセットでは、統計的に不安定になる可能性があります。つまり、堅牢な評価を行うためには、より多くのデータセットを収集する必要があり、その結果、多大な人手が必要になってしまいます。
著者らは新しいベンチマークとしてMMBenchを提案します。MMBenchはVLMのためのオブジェクトローカライゼーションや社会的推論など、20の異なる能力次元をカバーする約3000の単一選択問題を含んでいます。現在のVLMの指示追従能力が弱いため、選択ラベルを直接出力することができません。そのため出力をグラウンドトゥルースと直接比較することができません。提案手法ではモデルの予測と選択肢の一つをマッチングするためにChatGPTを採用しました。ChatGPTは87%の曖昧なケースで人間の評価と完全に一致することがわかっています。また評価をロバストにするためにCircularEvalと名付けた新しい評価戦略を提案します。
この研究では、MMBench上で14の有名な視覚言語モデルを包括的に評価し、性能評価の結果を報告します。さらにベンチマークとなるオープンソースのVLMを用いて、現代最大のマルチモーダルモデルであるBardとの比較評価も行いました。
この研究のコントリビューションは以下の3点です。
- VLMの能力を徹底的に評価するために、3つの異なるレベルの能力を統合する体系的なフレームワークを綿密に作り上げました。著者らは合計2,974のデータセットを慎重にキュレーションしました。
- ロバストな評価を行うために、新しい評価戦略「CircularEval」を導入しました。ChatGPTを用いてモデルの予測値と与えられた選択肢をマッチングさせ、命令追従能力の低いVLMの予測値からでも、うまく選択肢を抽出することができます。
- MMBenchを用いて、よく知られた14の視覚言語モデルの総合評価を行い、その結果を様々な能力次元で報告します。
評価戦略
新しい評価戦略のCircularEvalが面白かったので、この部分を紹介します。VLMに4択問題を解かせる場合、ランダムな推論でも25%の精度を持たらし、VLM間の性能差を減少させる可能性があります。CircularEvalでは選択肢の数Nに対して、各問題はVLMへN回供給されます。このときに選択肢と答えに円形のシフトが毎回適用されます。
下の画像がCircularEvalの例です。こちらの画像に対して「リンゴは何個ありますか?」という質問をします。このときに選択肢を1回目は「A:4, B:3, C:2, D:1」2回目は「A:3, B:2, C:1, D:4」と内容をシフトさせていきます。これを選択肢の数だけ繰り返して、すべてパスしたときのみ正解とします。これにより、1回だけの回答で評価を行うよりもロバストな評価が行えます。なお、途中で間違えた場合はそこで終了するので、推論コストは問題数x選択肢の数よりは少なくなります。

評価結果
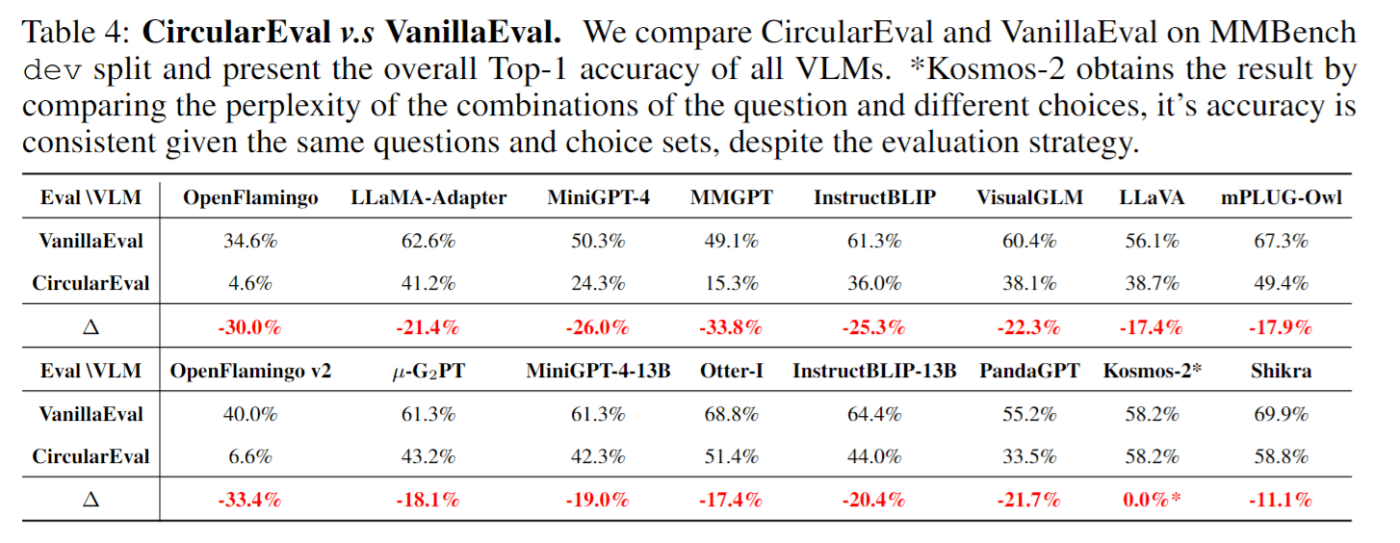
CircularEval(選択肢の数だけ推論)とVanillaEval(一回だけ推論)の比較を行いました。下の表がその結果です。こちらが示すように、ほとんどのVLMにおいて、CircularEvalへ切り替えると、モデルの精度は大幅に低下します。また2つの評価結果から異なる結論を得ることができます。例えば、InstructBLIPはVanillaEvalではLLaVAを上回りますが、CircularEvalでは逆の結論になります。
CircularEvalへの切り替えで大幅に精度が低下することから、ランダムな選択でも正解となっていたことがわかります。
結論
従来のベンチマークや主観的ベンチマークなどの問題に対処するために、著者らは20の能力次元をカバーする2,974の多肢選択問題の客観的評価パイプラインを提案するマルチモーダルベンチマークのMMBenchを提案しました。ロバストで信頼性の高い評価結果を得るためにCircularEvalと呼ばれる新しい評価戦略を導入しました。この評価戦略はかなり厳しく、手ごろな価格で信頼性の高い評価結果を得ることができます。さらにChatGPTを活用して、モデルの予測結果とターゲットの選択肢を比較することで、異なるレベルの命令追従能力を持つVLM間の公正な比較を可能にしています。
Discussion