論文紹介 : APISR: Anime Production Inspired Real-World Anime Super-Reso...

概要
APISR: Anime Production Inspired Real-World Anime Super-Resolution という論文を読んだので紹介します。
こちらはアニメ映像の超解像に特化した研究です。コントリビューションは以下の通りです。
- ビデオソースから最も圧縮されていない、最も情報量の多いフレームの画像を取得するアニメデータセットキュレーションパイプラインを提案する
- 手書きのラインの動画圧縮のゆがみに対処するために、画像劣化モデルを提案した
- 知覚的損失の領域の不整合によって引き起こされるGANベースのSRネットワーク学習における「不要な色のアーティファクト」を実現して対応した
- 既存のアニメSRデータセットで提案手法を評価し、先行研究と比べてわずか13.3%の学習サンプルで、既存研究を上回ることを示す
提案手法
アニメ画像SRデータセット
提案手法では新しいSR用のデータセットを作成しています。
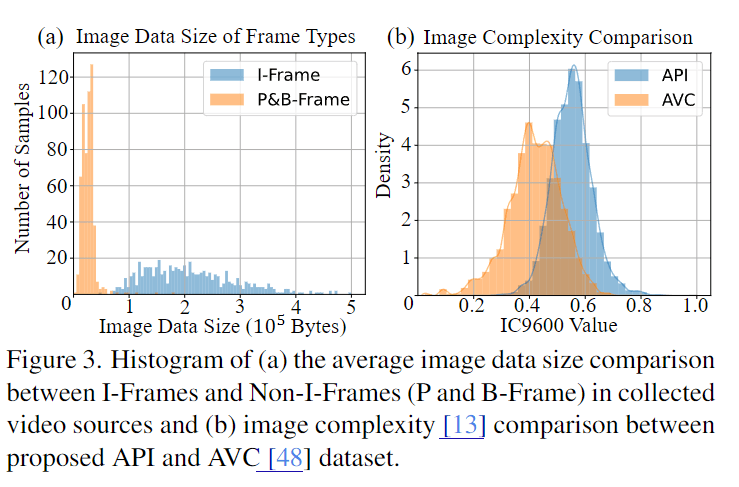
一般的なビデオ圧縮はI-Frameと呼ばれるいくつかのキーフレームを圧縮のための単位として指定します。経験的にI-Frameはシーンが変化する最初のフレームとなります。これらのI-Frameは高いデータサイズのバジェットが割り当てられています。提案手法ではffmpegを利用してI-Frameの切り出しを行っています。下のグラフの左はI-Frameとそれ以外のフレームのデータサイズ(横軸)とサンプル数(縦軸)です。I-Frameのほうがデータサイズが大きく、数は少ないことがわかります。
I-Frameを取り出した後に、複雑な画像だけを選び出してデータセットとして利用します。このために画像品質評価(IQA)を使うとよい結果が出ません。IQAをアニメ画像に使うと図4の左側をランキングの上位に持ってきてしまいます。提案手法では画像複雑度評価(ICA)を代わりに使います。図4の右側の画像はIQAは扱いが苦手ですが、ICAはうまく扱えます。

以上の手法でキュレーションしたデータセットの例が下の画像です。提案手法では562本の高品質なアニメ動画を入手し、まずすべてのI-Frameを取得します。そこから画像複雑度評価を用いて最高得点の上位10フレームを選択しました。不適切な画像を除いて、3740枚の画像をデータセットとして選びました。図3bは既存SRデータセットのAVC-Trainと比べて、提案手法のデータセットのほうがフレームの密度が高いことを示しています。

アニメの劣化モデル
超解像のデータセットを作る場合、GTから劣化画像を作る必要があります。従来の手法では劣化画像を作るためにJPEG圧縮を使っていました。JPEG圧縮はビデオ圧縮とは特性が違うため、今回の用途には適切ではありません。提案手法では予測志向の圧縮アルゴリズム(例えばWebPやH.264)と組み合わせることで、単一の画像から実際のビデオ圧縮アーティファクトを合成することができると主張しています。下の画像は左からGT、マルチフレーム圧縮誤差、シングルフレーム圧縮誤差です。一枚の画像からビデオ圧縮と同じような劣化画像を生成できていることがわかります。

アニメの手書き線の強化
提案手法ではGTから手書き線を抽出して、それをGTと融合して疑似GTを形成しました。この疑似GTをSR学習に導入することで、シャープな手書き線を生成することができるようになりました。提案手法ではピクセル単位のガウシアンカーネルに基づくスケッチ抽出アルゴリズムのXDoGを利用して、先鋭化したGTからエッジマップを抽出します。詳細は省略しますが、さらに工夫がされているようです。
アニメに対するバランスの取れた双子の知覚的損失
ここはややこしかったので省略します。Danbooruデータセットで分類タスクを学習したResNet50を利用して、低レベルのピクセル特徴を補完しています。
学習
学習の詳細は付録に記載されているようです。学習にはRTX4090を1台使っています。
結果比較
既存手法との比較画像の一部が下の画像です。一番右端が提案手法です。既存手法と比べて手書きの線がくっきりしているのが特徴だと思います。

アブレーションスタディ
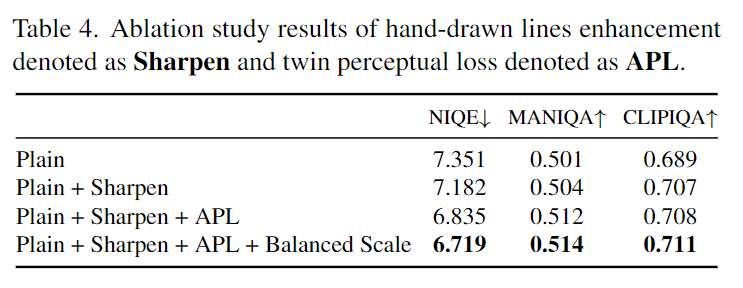
アブレーションスタディとして、手書き線の強調の有無による結果の違いを見ることができます。下の表のSharpenが手書き線を強調したものです。こちらの数値からも手書き線の強調が有効だったことがわかります。
実装
githubで公開されています。スターの数がすごい!
ライセンスはGPL 3.0ですが、以下の注意書きがありました(英語から翻訳)。商用アニメの映像を利用しているので、そうなってしまいますよね。映像の利用元の記載は無いようです。
このプロジェクトは学術目的でのみ公開されます。データセットの配布に関する責任は放棄する.利用者は自分の行動に対してのみ責任を負う.このプロジェクトの貢献者は,利用者の行動と法的には無関係であり,責任を負うこともない.
Discussion