SynCLRの論文紹介

概要
GoogleResearchから発表されたSynCLRの論文を読んだので自分なりのメモ書いておきます。
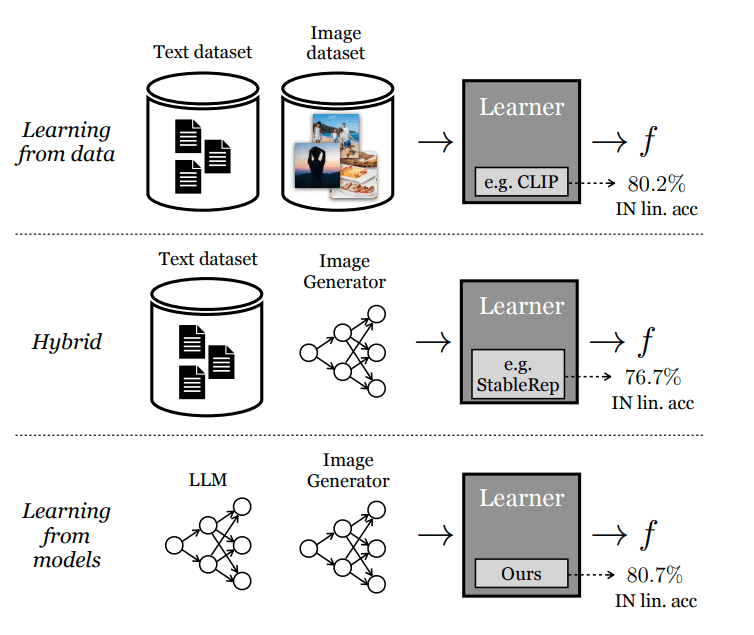
SynCLRは実データを使わずに合成画像と合成キャプションのみから視覚表現を学習する新しいアプローチです。CLIPは実データのテキストと画像を利用します。StableRepは実データとそこから生成された画像を使って学習します。SynCLRはすべてを合成(生成)データから学習します。論文を読むとStableRepが先行研究に相当するようですね。こちらも読んでおいたほうがよさそうです。
クラスの再定義
SynCLRでは視覚クラスの粒度を再定義しているところが新しいです。例として「サングラスとビーチサンダルをかぶったゴールデンレトリバーが自転車で乗り出す」「寿司でできた家のなかにかわいいゴールデンレトリバーが座っている」という2つのプロンプトから画像を生成します。
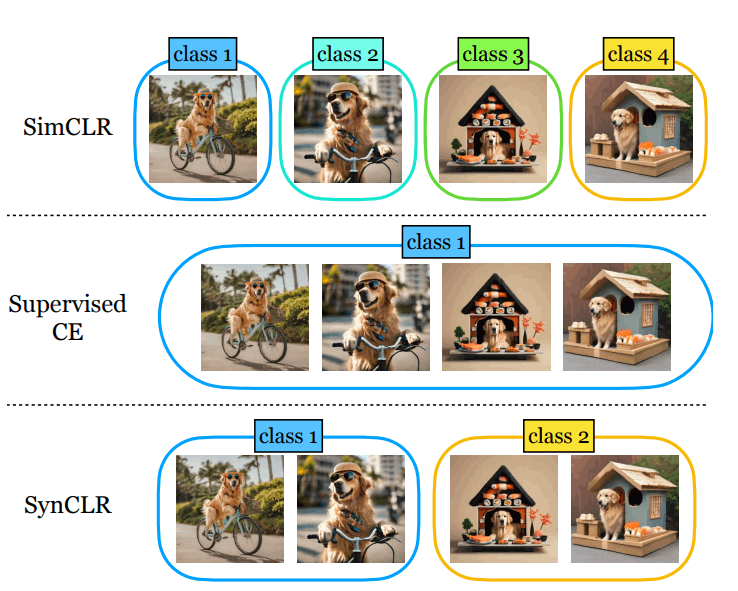
既存のSimCLRという研究ではすべての画像を別々のクラスとして分類します。SupervisedCEという研究では「ゴールデンレトリバー」という単位で1クラスとして扱うので、画像のニュアンスを無視しています。
SynCLRではキャプションをクラスとして扱います。これにより「自転車に乗る」「寿司ハウスに座る」という概念でグループ化することができます。このような粒度を扱うことは実データでは難しいです。キャプションをスケールするのが難しいからです。一方で画像生成AIでは1つのキャプションから複数の画像のバリエーションを出すのが可能です。このキャプションレベルの粒度を扱うことで既存研究の精度を上回ることがわかっています。
手法
手法としては3つのステップに分かれています。まず大規模な画像キャプションを生成します。ここでは単語からLLMを用いてキャプションへ翻訳しています。次に拡散モデルを用いて、テキストから画像を生成します。最終的に600Mの画像を生成しています。最後にmulti-positive対照学習とマスクドイメージモデリングで視覚表現モデルを学習します(この2つは論文を読まないといけないようです)
キャプションの合成
膨大な学習画像のデータセットを構築するために、幅広い視覚的概念を含む多様性のあるキャプション(説明文)が必要になります。
まずImageNet21kやPlaces-365のような既存のデータセットから「概念リスト」を収集します。ここではImageNetなどに含まれているクラス名に相当します。この概念リストからキャプションを合成しますが、今回は以下の3つのアプローチを用意しました。
- シンプルなアプローチとして「概念リスト」から取り出した「概念」から「キャプション」をLllama-2モデルで直接生成します
- 「概念」と「背景」の組み合わせから「キャプション」を生成することもできます。「背景」の単語はPlaces-365のような既存データセットのものが利用できます。ナイーブな実装としてはこの2つをランダムに組み合わせることですが、これでは「サッカーのフィールドでシロナガスクジラ」のような現実の世界であり得ない組み合わせになってしまいます。アブレーション実験の結果、このアプローチはうまくいかないことがわかっています。これは画像生成AIの学習範囲から大きく外れるためです。その代わりにGPT4を利用して、選択した「概念」に適した「背景のリスト」を生成しました。このアプローチなら「森の中の虎」「キッチンの猫」のような妥当な組み合わせの生成頻度を高め、全体の品質を向上させます(この点でOpenAIの利用規約が関係してきますが、これがgithubでのデータセット公開が遅れている理由でしょうか?)
- 「概念」と「位置関係語」から「キャプション」を生成することも考えられます。例えば概念が「猫」、位置関係語が「前方(in front of)」だった場合、「かわいい黄色い猫がソファの前で魚を楽しんでいる」というキャプションを生成できます。多様性を高めるために10種類の位置関係語の中からランダムに選択したものを利用します。
今回はこの3つのアプローチを選んで利用しています。こちらの画像は3つのアプローチによるキャプション生成の例です。

画像の合成
合成されたキャプションを使って画像の合成を行います。ここで重要になるのが分類器フリーガイダンス(CFG)スケールです。CFGスケールが高いほどサンプルの品質とテキストと画像のアライメントが向上します。スケールが低いほどサンプルの多様性が増し、与えられたテキストに基づく画像の元の条件付き分布にうまく準拠するようになります(ここはよくわかってないです)
今回は先行研究のStableRepに従って2.5をCFGスケールとして使うことにしました。同様に1キャプションあたりの生成画像は4枚にしています。
表現学習
表現学習は先行研究のStableRepをベースにしているので、そちらを読まないといけないようです。単なる対照学習ではないようです。
実装
概念リストとして既存の複数のデータセットのクラス名を連結して使います。概念が「場所」もしくは「テクスチャ」の場合は「概念」から「キャプション」を生成するアプローチを使用します。
(この辺は省略)
実験
アブレーションスタディを実行しています。一つのキャプションに対して何枚の画像を生成すればよいかという点に関しては「4枚」で十分ということがわかりました。「4枚」で既存研究のStableRepの「10枚」のケースを上回ることがわかったからです。
(ここも長いので省略)
こちらはキャプションから生成された4枚の画像の例です。

ソースコードについて
githubは公開されているのですが、READMEが不十分なため、どこまで入っているのかわかっていません。論文で言及されているSynCaps-150Mというデータセットを公開する予定のようですが、まだ社内の承認プロセス中のようです。
学習済みモデルは2つ公開されています。
学習はJaxで行っているようですが、Pytorchのリファレンスコードも付属しているようです。
Discussion