💨
MU-LLaMAをRTX4090で動かせるようにした

概要
MU-LLaMA:Music Understanding Large Language Model というモデルを動かしてみました。楽曲に対してテキストで問い合わせができるモデルです。
こちらのモデルを動かすにはVRAM32GB以上のGPUが必要だったのですが、パラメータの変更でRTX4090(24GB)で動かすことができました。
環境構築
リポジトリのrequirements.txtのモジュールをインストールします。
モデルのリポジトリをcloneしてckptsフォルダを作ります。
git clone https://github.com/crypto-code/MU-LLaMA
cd MU-LLaMA/MU-LLaMA
mkdir ckpts
学習済みモデルはこちらからダウンロードして、公式ドキュメントのように配置します。
.
├── ...
├── MU-LLaMA
│ ├── ckpts
│ │ │── LLaMA
│ │ │ │── 7B
│ │ │ │ │── checklist.chk
│ │ │ │ │── consolidated.00.pth
│ │ │ │ │── params.json
│ │ │ │── llama.sh
│ │ │ │── tokenizer.model
│ │ │ │── tokenizer_checklist.chk
│ │ │── 7B.pth
│ │ ├── checkpoint.pth
└── ...
VRAMの消費量を減らすための修正
以下の部分のmax_seq_len=8192を2048に減らします。
MU-LLaMA/llama/llama_adapter.py
# 3. llama
with open(os.path.join(llama_ckpt_dir, "params.json"), "r") as f:
params = json.loads(f.read())
bias_lora = phase == "finetune"
model_args: ModelArgs = ModelArgs(
max_seq_len=2048, max_batch_size=1, w_bias=bias_lora, w_lora=bias_lora,
**params) # max_batch_size only affects inference
print(f"model args: {model_args}")
model_args.vocab_size = self.tokenizer.n_words
if torch.cuda.is_available():
torch.set_default_tensor_type(torch.cuda.HalfTensor)
self.llama = Transformer(model_args)
torch.set_default_tensor_type(torch.FloatTensor)
デモを実行
gradio_app.pyのあるフォルダで以下を実行します
python gradio_app.py --model ckpts/checkpoint.pth --llama_dir ckpts/LLaMA
うまく実行できていれば以下の表示になり、24000ポートでデモが実行できます。dockerで動かしている場合はこちらのポートを開けておくか、gradio_app.pyの最後の行のserver_portを開いているポートに修正します。
Running on local URL: http://0.0.0.0:24000
「アイドル」の冒頭の10秒をwavファイルにして入力して、質問してみます。ボーカルが男性となっているのでここは間違っていますね。
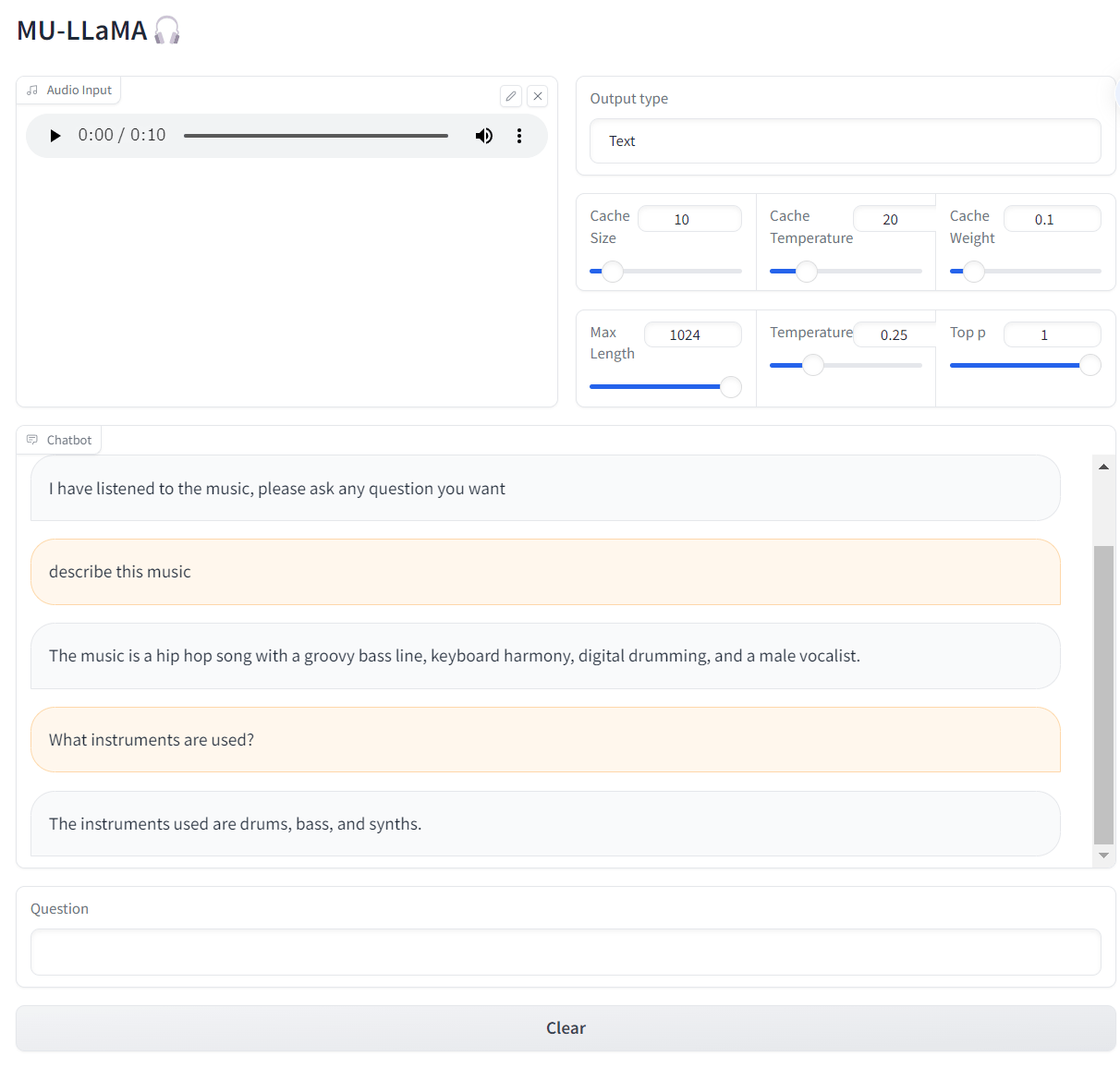
VRAMは20GB使っていました。
Sun Dec 3 23:31:07 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 0% 43C P8 34W / 450W| 19417MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1081 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1217 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 6513 C ...rsions/anaconda3-2021.05/bin/python 19392MiB |
+---------------------------------------------------------------------------------------+
Discussion