論文紹介 : DeepSeek-VL
概要
DeepSeek-VL: Towards Real-World Vision-Language Understandingという論文を読んだので面白かったところに絞って紹介します。
著者らはDeepSeek-VLというモデルを開発しました。こちらは言語と画像のマルチモーダルモデルです。DeepSeek-VLモデルは論理図、ウェブページ、数式認識、科学文献、自然画像などを処理できます。
近年、オープンソースのマルチモーダルモデルが相次いで発表されています。これらの先行研究には解像度の点や言語能力の点で課題があります。内部で扱う画像の解像度が336x336や448x448程度と比較的低い解像度なので、OCRや小さい物体の検出の面でうまくいきません。またマルチモーダル学習を長期間行うと、しばしば言語能力の劣化が見られることが知られています。著者らは言語と画像の両面で強力な能力を持つジェネラリストのモデルを目指すため、言語能力を十分に保持した学習戦略を発見しました。
こちらの論文ではDeepSeek-AI社のDeepSeek言語モデルシリーズをベースにしたオープンソースの大型マルチモーダルモデルのDeepSeek-VLを発表しました。著者らは実世界のシナリオにおいて、事前学習、ユースケース分類法に基づく慎重なデータキュレーション、高解像度処理のためのモデルアーキテクチャ設計、マルチモダリティのバランスを取る学習戦略などを追求してモデルを開発しました。
データ構築
ここではDeepSeek-VLの学習データで使用されたデータセットについて説明されています。データセットはほとんどが英語です。OCR用のデータとして英語と中国語のドキュメントOCRデータセットを構築しています。arXivの論文、電子書籍と教材を使って、テキストと画像のペアを構築しました。データセットを見る限り、日本語は入っていないようです。
アプローチ
提案手法のモデルはハイブリッドビジョンエンコーダ、ビジョンアダプタ、言語モデルの3つのモジュールから構築されています。
ハイブリッドビジョンエンコーダ
視覚エンコーダとしてSigLIPを採用しています。こちらは高次の意味的特徴を抽出します。SigLIPのようなCLIPファミリーは主に意味的な視覚表現のために設計されています。比較的低解像度の入力(たとえば224x224、336x336、384x384、512x512)による制限があるため、細かいOCRや視覚に基づくタスクのような、より詳細な低レベルの特徴を必要とするタスクの能力が妨げられています。
この問題に対処するため、最近の研究では視覚のみの自己教師付きエンコーダーを追加で統合することを提案しています。著者らは低レベルの特徴を処理するためにViTDet画像エンコーダーであるSAM-Bに基づく、視覚のみのエンコーダーを利用し、1024x1024の画像入力を受け付けるようにしました。
2つのエンコーダーを組み合わせることで、意味情報と詳細情報を保持しながら、高解像度を効率的に符号化することが可能になりました。
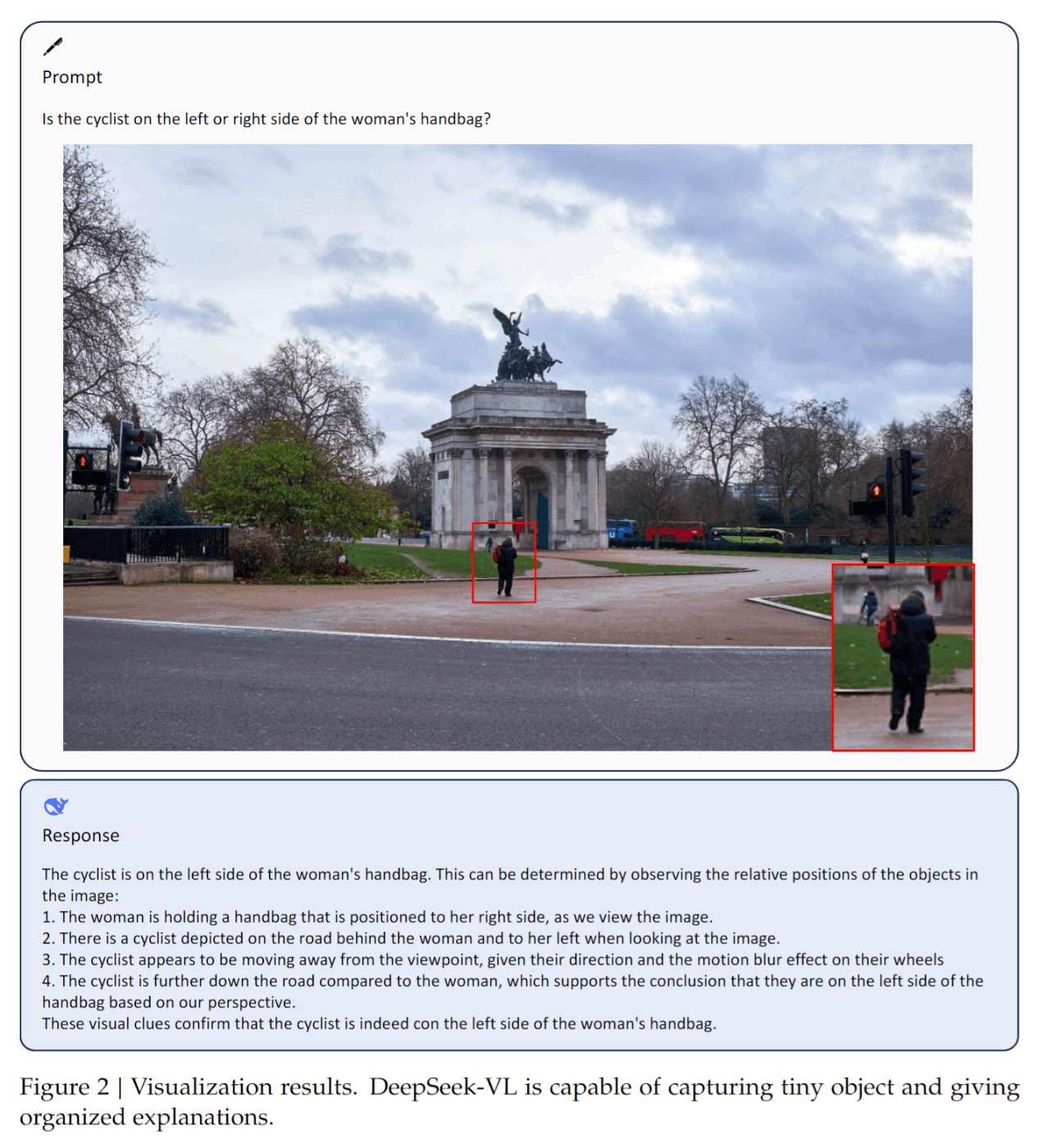
下の画像は高解像度が扱えることを示しています。画像の中の小さい人物の隣にサイクリストがいることを認識できています。
視覚-言語アダプタ
ビジョンエンコーダとLLMの橋渡しとして、2層のハイブリッドMLPを採用します。
言語モデル
提案手法の言語モデルはミクロ設計がLLaMAの設計にほぼ準拠したDeepSeek LLMを使用しています。DeepSeekの事前学習済みモデルから中間チェックポイントを選択して、事前学習を継続します。
具体的にはDeepSeek-VL-1Bモデルは約500億トークンのコーパスで学習されたDeepSeek-LLM-1Bモデルに基づいて構築されています。またDeepSeek-VL-7Bモデルは、約2兆語のテキストトークンで学習したDeepSeek-LM-7Bモデルを活用して開発されています。
学習パイプライン
学習パイプラインは図3に示すように3つの連続したステージで学習を行います。(左)視覚言語アダプタのウォームアップ、(中)視覚言語の共同事前学習、(右)教師ありの微調整を行います。画像の赤い部分が学習対象で、水色の部分はフリーズされています。
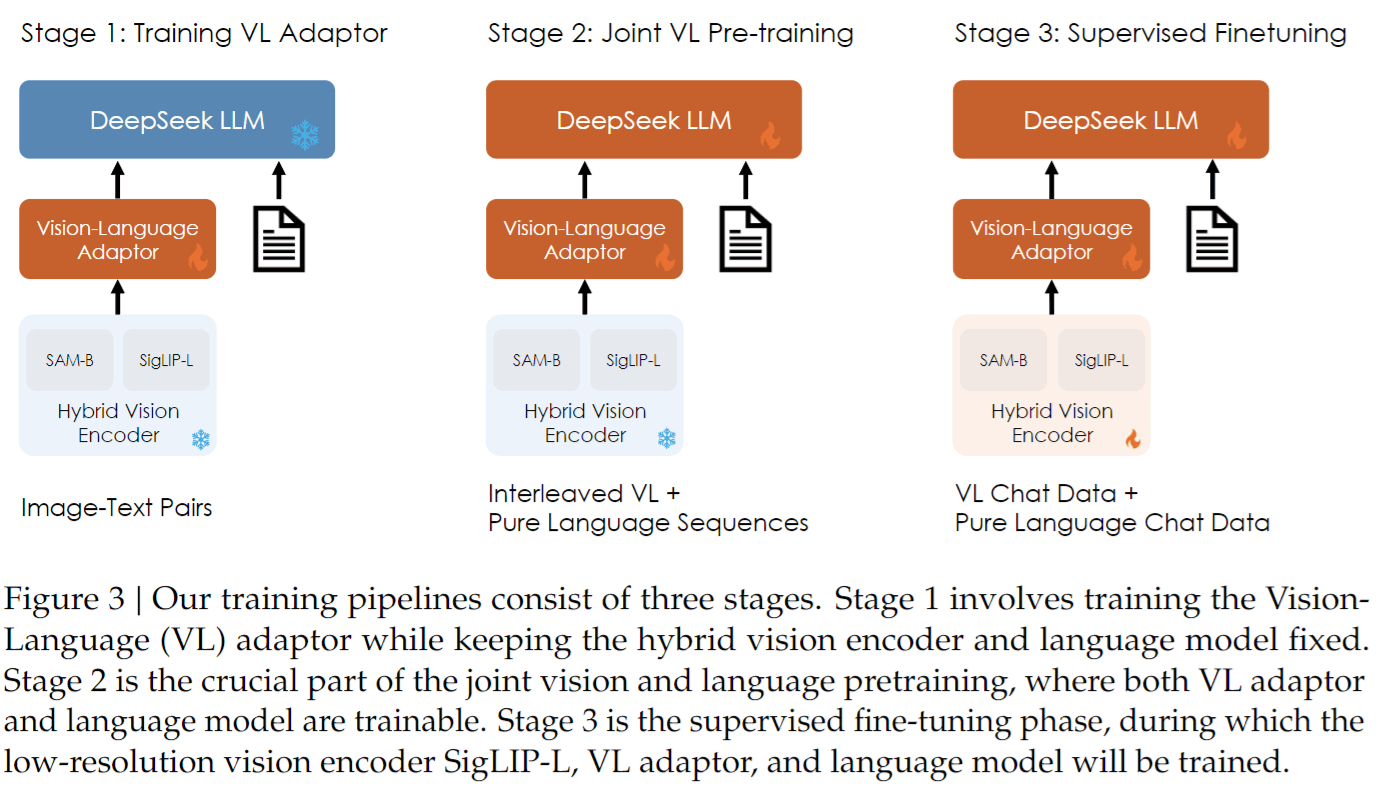
視覚言語アダプタの学習
先行研究のLLaVAとInstruct-BLIPに従い、ビジョンエンコーダとLLMの両方を凍結して、視覚言語アダプタの学習を行います。この部分は埋め込み空間内の視覚的要素と言語的要素の間の概念的なリンクを確立します。
視覚言語合同の事前学習
ここでは視覚エンコーダを凍結したまま、言語モデルと視覚言語アダプタを最適化します。マルチモーダルデータを用いて学習をすると、マルチモーダル性能は改善される一方で、言語指標は著しく低下していることがわかります。このことはマルチモーダル能力の向上と、言語能力の維持の間に重要なトレードオフを明らかにするものです。
この原因として、第一にマルチモーダルコーパスの大部分は過度に単純で、言語データの複雑さや分布から大きく乖離している点が考えられます。第二に、マルチモーダリティと言語モダリティの間には競争力のあるダイナミズムがあり、LLM内の言語能力を壊滅的に忘れてしまうという現象に繋がるようです。
この問題を解決するため、簡単かつ効果的な言語とマルチモーダルの共同学習戦略を考案しました。学習時にはマルチモーダルなデータ学習をおこなうだけでなく、言語データを学習に取り込みます。このアプローチは先ほどの副作用を軽減し、トレーニングのバランスをとることを目的としています。提案手法ではDeepSeek-VL-1Bモデルで実験を行い、モダリティ混合比を変化させた場合の影響を調査しています。
この実験の結果から以下の3つの結論が得られました。(1)言語データを統合することで、言語能力の低下を大幅に緩和し、モデルの言語性能の大幅な向上を実証しました。(2)言語データを含めても、マルチモーダル性能の大きな低下は見られず、モデルがマルチモーダル能力を保持していることがわかります。(3)異なるモダリティの性能は、学習データセットにおける比率と強い相関があります。最終的には言語とマルチモーダルデータの学習比率をおよそ7:3にしました。
教師ありの微調整
このステージでは命令ベースのデータセットでファインチューニングを行います。命令に従う能力と対話能力を強化し、最終的に対話型DeepSeek-VL-Chatモデルを作成します。このステージでは3つの部分のすべてを学習します。
評価
マルチモーダルのベンチマークで既存モデルとの比較を行いました。DeepSeek-VLはMMB、MMC、SEEDbenchなどのベンチマークにおいて、同規模のオープンソースモデルを凌駕し、GPT-4Vに匹敵する能力を実証しました(DeepSeek-VL vs GPT-4V = 70.4 vs 71.6 on seedbench)
一方、DeepSeek-VL-1.3Bは同程度の大きさのモデルを大幅に上回る性能を示しました。MMBベンチマークテストでは、オープンソースモデルより優れた性能を示し、パラメータは半分近くしか使用していません。

アブレーション研究
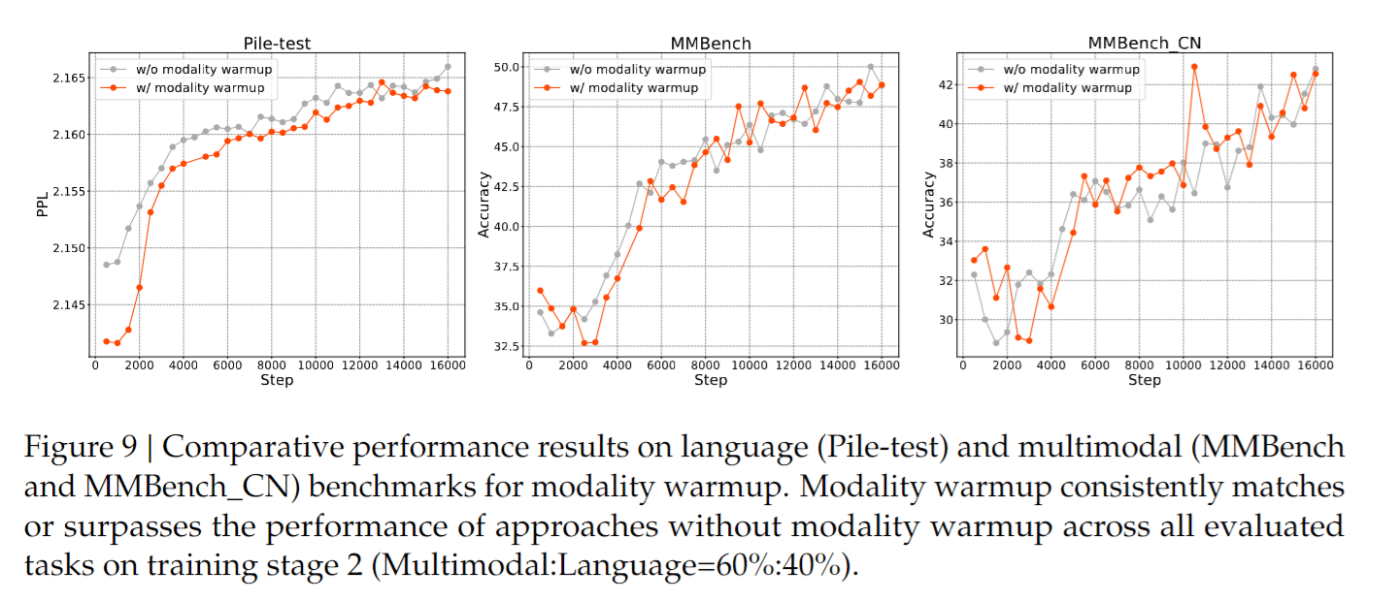
ここではモダリティウォームアップというテクニックが説明されています。マルチモーダル学習においては、最初から一定の割合でマルチモーダルデータを混合すると、モデルが不安定になる可能性があります。この問題に対処するため、著者らはシンプルかつ効果的なモダリティウォームアップ戦略を提案しました。最初に言語データ比率を1に設定し、それを徐々に目標比率に下げて最終的なモデル学習を行います。実験によって、この戦略が効果的に学習開始時の言語能力の大幅な低下を防ぐと同時に、言語とマルチモーダル領域の両方において最終段階で比較的優れた結果をもたらすことを確認しました。
今後の課題
Mixture of Experts(MoE)技術を取り入れ、DeepSeek-VLをより大きなサイズに拡大することを計画しているようです。
読んだ感想など
マルチモーダル学習におけるトレーニング戦略の部分が大変勉強になりました。マルチモーダルデータのキャプションが過度に簡単であるため、言語能力が損なわれるという点はかなりの説得力があります。また、モダリティウォームアップの部分も他で聞いたことがなかったので参考になりました。
Discussion