Looker Studio で Zenn のアクセス解析ダッシュボードを作ってみた
やったこと
Zenn に Google Analytics (GA4) を連携して取得したアクセスデータをもとに、Looker Studio でお手製ダッシュボードを作った。
なぜやったか?
Zenn の管理画面上で見られる統計ダッシュボードで日別・投稿別の表示数は見られるものの、ページ別の表示数推移や流入元別の集計値など、より詳細な情報を見たかった。
一応 GA4 のコンソール上でも見られるが、インタラクティブにフィルターを切り替えるなどしてより柔軟かつ手軽にデータを見たかったため、自分で作ってしまうことにした。
やり方
1. Google Analytics に Zenn を紐づけてトラッキングする
「Zenn Google Analytics」などで調べればいくらでも情報が出てくるので割愛。
2. Google Analytics のデータを BigQuery に転送する設定を有効にする
これも調べればすぐ出てくるはず
3. 集計クエリの作成
分析軸:
- 日付
- 投稿名 or ページ名
- 流入元(direct, google, 旧twitter などの単位で)
集計指標:
- ページ表示回数
- ユニークユーザー数(日毎)
- 初回ユーザー数
ページに関連する情報:
- scrap, article の区別
- 投稿日
- 今回は、初回にアクセスのあった日で代用。
- 原稿プレビュー段階での表示もログが残るため、実際の投稿日とは一致しない。
WITH import_events AS (
SELECT
*,
(SELECT p.value.string_value FROM e.event_params AS p WHERE p.key="page_title") AS page_title,
(SELECT p.value.string_value FROM e.event_params AS p WHERE p.key="page_path") AS page_path,
FROM
`<project_id>.analytics_<GA4_ID>.events_*` AS e
),
-- page_path を整形し、ページ内リンクやクエリパラメータ付きの path をまとめた。
-- なお、トップページだけはタブ別(記事一覧、scrap 一覧、コメント一覧)に見られるようにクエリパラメータを残した。
-- ついでに、scrap か article かそれ以外(トップページなど)の区別も取得した。
normalize_page_path AS (
SELECT
*,
COALESCE(REGEXP_EXTRACT(page_path, r"^.*\/tatamiya\/([a-z]+)\/*"), "others") AS page_type,
REGEXP_EXTRACT(page_path, r"^.*(\/tatamiya\/[a-z]+\/[^#?\/]+|\/tatamiya$|\/tatamiya\?.*)") AS page_path_normalized
FROM
import_events
),
-- ページ名の名寄せ。標準化した page_path に対して、ページ名を一意に紐づける。
-- 記事タイトルを変えたりすると、同じ path でも別の記事名になってしまうことがあるため。
-- 標準化した page_path ごとに最も新しいページ名を取ってくることにした
page_title_table AS (
SELECT
page_path_normalized,
MAX_BY(page_title, event_timestamp) AS page_title,
MIN(event_date) AS publish_date
FROM normalize_page_path
GROUP BY page_path_normalized
)
-- metrics の集計
SELECT
event_date,
pt.page_title,
e.page_path_normalized,
e.page_type,
publish_date,
traffic_source.source AS traffic_source,
COUNTIF(event_name="page_view") AS count_pv,
COUNTIF(event_name="first_visit") AS count_first_visit,
COUNT(DISTINCT user_pseudo_id) AS count_uu
FROM
normalize_page_path AS e
JOIN page_title_table AS pt ON e.page_path_normalized=pt.page_path_normalized
GROUP BY event_date, pt.page_title, e.page_path_normalized, e.page_type, publish_date, traffic_source
↑ 上記をテーブル化し、毎日洗い替えするようスケジュールクエリを設定[1]
Looker Studio でダッシュボードの作成
こんな感じ
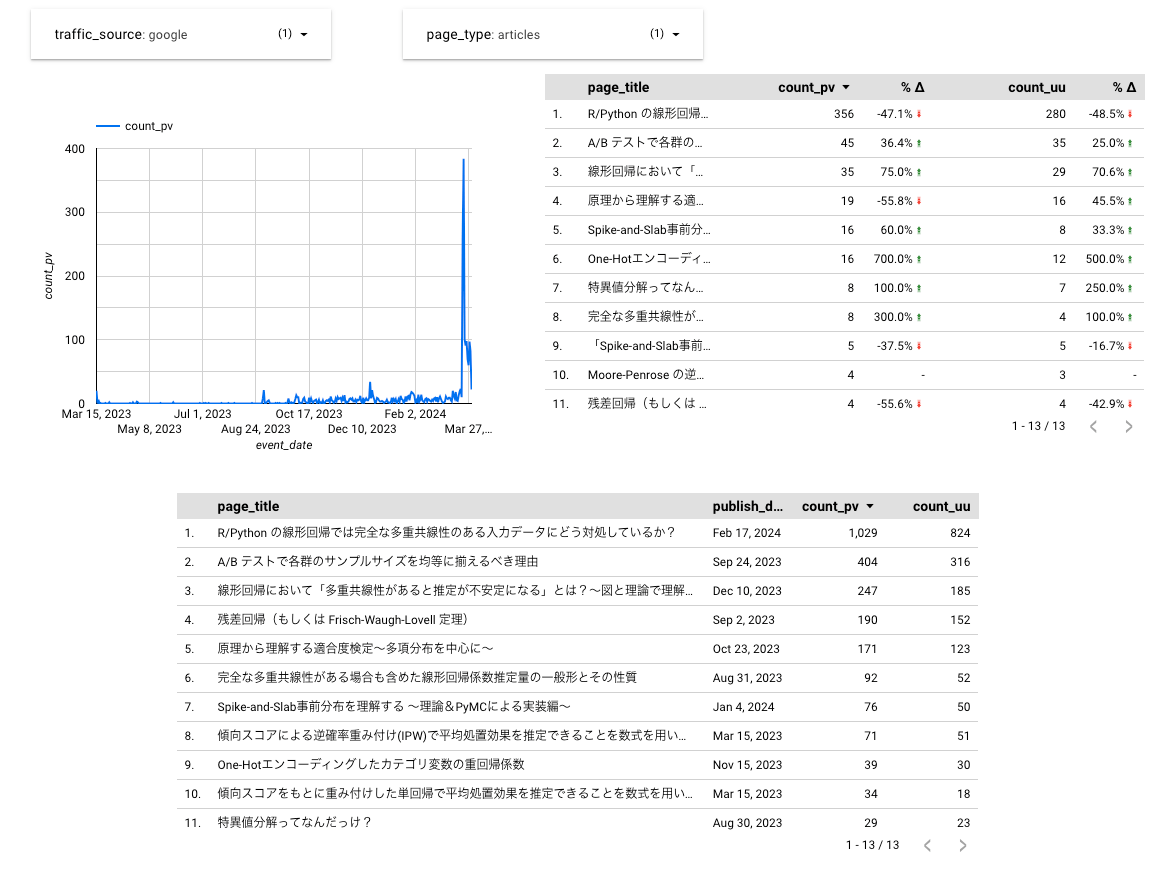
加えて、流入元、ページ種類でフィルタリング
Zenn 管理画面の統計ダッシュボードと数字が一致しないものの、傾向だけ分かればよいのでまーこれで十分だ。
ダッシュボードにかかる BigQuery コストの調査
Zenn アクセス解析ダッシュボードを作って1,2ヶ月程度経ったので、かかっているコストを調べてみることにした。
というのも、現状ダッシュボード用のテーブルは毎日 Google Analytics のログを全スキャンして洗い替えをおこなっており、差分更新の方が安く済むのではないかという懸念があったからである。
結論
まだ差分更新にしなくて良い。
なぜなら、テーブル更新にかかるコストは月に1円にも満たないからである。
一方で、テーブル洗い替えによるコストよりダッシュボード閲覧時に Looker Studio から発行されるクエリのコストの方が10倍以上高く、仮にコストを下げるにしてもこちらから先に対策を検討した方がよい。
前提
筆者の BigQuery 利用は、Zenn アクセス解析ダッシュボードによるものがメインである。
それ以外の用途でも使っているが微々たるものであるので、今回の分析では無視する。
計測内容
クエリ
以下のように、INFORMATION_SCHEMA を用いて課金データ量を取得し、集計を行った:
WITH
import_bytes_billed AS (
SELECT
DATE(creation_time, "Asia/Tokyo") AS creation_date,
project_id,
job_id,
CASE
WHEN STARTS_WITH(job_id, "scheduled_query") THEN "scheduled_query"
WHEN STARTS_WITH(job_id, "job") THEN "job"
WHEN STARTS_WITH(job_id, "bquxjob") THEN "bq_ux_job"
ELSE
"others"
END
AS job_id_prefix,
job_type,
total_bytes_billed -- 課金対象データ量
FROM
`region-us.INFORMATION_SCHEMA.JOBS_BY_USER` AS isch
WHERE
DATE(creation_time)>="2024-04-01" -- partition key になっているので、必ず指定する
)
SELECT
creation_date,
job_id_prefix,
job_type,
SUM(total_bytes_billed) AS total_bytes_billed,
SUM(total_bytes_billed) * POW(1024,-4) * 6.25 * 155 AS total_billing_estimated_yen, -- 円換算の課金額。為替レートはとりあえず1ドル155円に設定。
COUNT(DISTINCT job_id) AS count_query
FROM
import_bytes_billed
GROUP BY
creation_date,
job_id_prefix,
job_type
ORDER BY
creation_date,
job_id_prefix,
job_type
計測結果
以下は、上記のクエリによる月別の合計課金額(仮に1ドル155円として算出)を job 種別ごとに可視化したものである:

scheduled_query が日次のテーブル更新にかかる費用であるが、4月分で1円未満であった。
それに対して、job はダッシュボード閲覧時に Looker Studio から発行するクエリによりかかる費用であり、こちらの方が圧倒的に支配的であった。
おまけ
以下は日ごとに課金額とクエリ発行回数を見てみたものである:
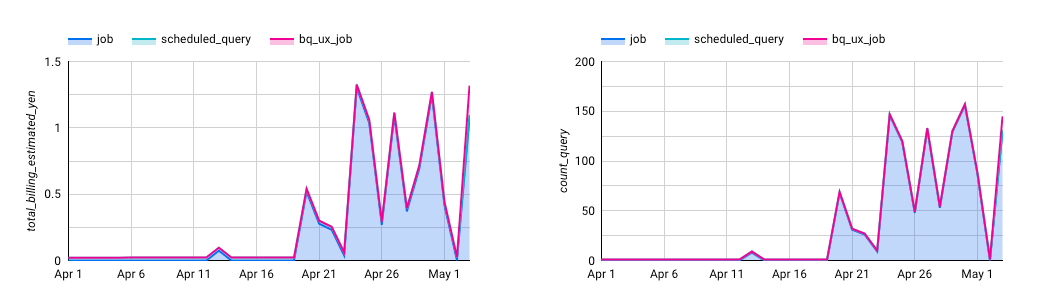
これを見ると、明らかに課金額がダッシュボード閲覧に伴うクエリ回数と連動していることがわかる。
一方で、以下はクエリ1回あたりのデータスキャン量の推移である:
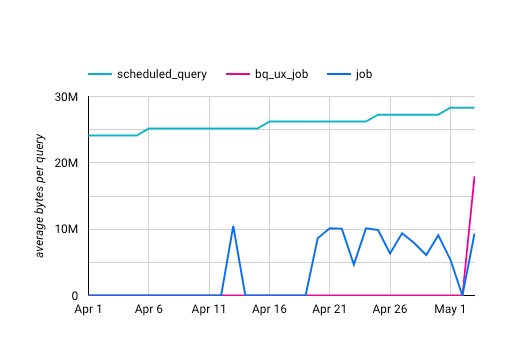
ダッシュボード閲覧時のクエリ単位のデータスキャン量は日により大きく変わらず最大でも 10MB 程度であった(10MBを下回るケースは、キャッシュにヒットしたためと考えられる)。
したがって、ダッシュボード用テーブル自体が大きくなりすぎてコストがかかるようになっているわけではなさそうである。
つまり、単純にダッシュボードをいじりすぎてクエリ発行回数が増えた際に、課金額もそれにつられて増大しているものと考えられる。
もしダッシュボードにかかるコストを減らしたい場合は、ダッシュボード用テーブルの更新方法以前に、ダッシュボードの閲覧をほどほどに控えるか、もしくは(可能であれば)閲覧時のデータ取得方法を工夫する方が先決であろう。
(けど、7円くらいならまだいいや。)