BigQuery の Tips メモ
MAX_BY, MIN_BY の利用例
集計関数 MAX_BY, MIN_BY が、2023年8月8日にGAとなった。
どのようなことができる?
「ある月で売り上げが最大(最小)だった日はいつか?」のような集計が簡単にできる。
従来では Window 関数を利用して With 句を用いて集計する必要があり手間だったが、
MAX_BY, MIN_BY の登場により手軽に行えるようになった。
利用例
以下では実際に MAX_BY を使った例を紹介するが、 MIN_BY についても同様である。
例題
以下のような日毎の売り上げデータがあったとき、月ごとに売り上げ最大値とともに「売り上げが最大になった日付」を知りたい。
WITH
sample_sales_data AS (
SELECT
DATE("2022-07-03") AS sales_date,
10 AS amount
UNION ALL
SELECT
DATE("2022-07-10") AS sales_date,
30 AS amount
UNION ALL
SELECT
DATE("2022-07-21") AS sales_date,
20 AS amount
UNION ALL
SELECT
DATE("2022-08-01") AS sales_date,
15 AS amount
UNION ALL
SELECT
DATE("2022-08-25") AS sales_date,
50 AS amount )
SELECT
*
FROM
sample_sales_data
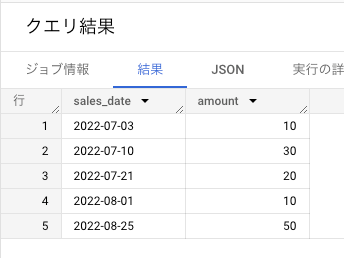
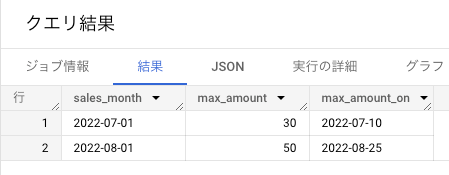
MAX_BY を使った集計方法
(sales_month でグループ化された中で)amount が最大になる sales_date を取得するので、
MAX_BY(sales_date, amount)
という書き方をする。
-- sample_sales_data の定義は省略
SELECT
DATE_TRUNC(sales_date, MONTH) AS sales_month,
MAX(amount) AS max_amount,
MAX_BY(sales_date, amount) AS max_amount_on
FROM
sample_sales_data
GROUP BY
DATE_TRUNC(sales_date, MONTH)
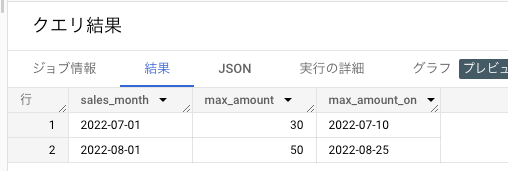
補足: MAX_BY を使わない方法
これまでは MAX_BY がなかったので、以下のように Window 関数を使ったやや複雑な処理が必要だった:
-- sample_sales_data の定義は省略
WITH find_max_amount_date AS (
SELECT
*,
FIRST_VALUE(sales_date) OVER (PARTITION BY DATE_TRUNC(sales_date, MONTH) ORDER BY amount DESC) AS max_amount_on
FROM
sample_sales_data )
SELECT
DATE_TRUNC(sales_date, MONTH) AS sales_month,
MAX(amount) AS max_amount,
MAX(max_amount_on) AS max_amount_on
FROM
find_max_amount_date
GROUP BY
DATE_TRUNC(sales_date, MONTH)
追記
これまでだと ARRAY_AGG を使う方法もあったらしい。
TIMESTAMP と DATETIME の比較と変換時の注意
ダイジェスト
- TIMESTAMP 型は常に time_zone が UTC だが、 DATETIME は time_zone を持たない。
- オプション引数で time_zone を指定してデータを作成するときの挙動が異なることに注意が必要
- TIMESTAMP: 入力値を指定した time_zone のものとして解釈し、UTC に変換する。
- DATETIME: 入力値を UTC のものとして解釈し、指定した time_zone の日時に変換する。
- 基本的には time_zone が明記されている TIMESTAMP でデータを持ち、別 time_zone の日時で表示or操作したいときだけ DATETIME 型ないし DATE 型に変換するのが良いだろう。
基本的な挙動
TIMESTAMP
- 何も指定がなければ、"UTC" として認識される。
- UI 上では
YYYY-mm-dd HH:MM:SS UTCのようなフォーマットで表示される。- "UTC" 以外の time_zone で表示されることはない
- time_zone の指定方法には、いくつかパターンがある
- 入力文字列内で明記する(
+9:00,Asia/Tokyoなど。JSTはダメ。) - オプション引数で指定する
- 入力文字列内で明記する(
- オプション引数で time_zone を指定すると、読み取った日時を指定した time_zone のものとして判断し、UTC に変換して表示する。
- 下記の JST を指定した例では、9H 差し引かれる。
- すでに入力文字列で time_zone が明記されていた場合、オプション引数による time_zone 指定はできない
SELECT
TIMESTAMP("2023-08-01 06:00:00") AS timestamp,
TIMESTAMP("2023-08-01 06:00:00 Asia/Tokyo") AS timestamp_with_tz_1,
TIMESTAMP("2023-08-01 06:00:00+9:00") AS timestamp_with_tz_2,
--TIMESTAMP("2023-08-01 06:00:00 JST") ← 実行不可能
TIMESTAMP("2023-08-01 06:00:00", "Asia/Tokyo") AS timestamp_with_tz_3,
--TIMESTAMP("2023-08-01 06:00:00 Asia/Tokyo", "Asia/Tokyo") ← 実行不可能
| timestamp | timestamp_with_tz_1 | timestamp_with_tz_2 | timestamp_with_tz_3 |
|---|---|---|---|
| 2023-08-01 06:00:00 UTC | 2023-07-31 21:00:00 UTC | 2023-07-31 21:00:00 UTC | 2023-07-31 21:00:00 UTC |
DATETIME
- UI 上では、
YYYY-mm-ddTHH:MM:SSのようなフォーマットで表示される(time_zone はない)。 - time_zone に指定方法は、オプション引数のみ(入力文字列内では明記不可能)。
- オプション引数で time_zone を指定すると、読み取った日時を UTC として判断し、指定された time_zone に変換して表示する。
- 下記の JST を指定した例では、9H 足される
SELECT
DATETIME("2023-08-01 06:30:00") AS datetime,
--DATETIME("2023-08-01 06:30:00+9:00"), ← 実行不可能
--DATETIME("2023-08-01 06:30:00 Asia/Tokyo"), ← 実行不可能
DATETIME("2023-08-01 06:30:00", "Asia/Tokyo") AS datetime_with_tz,
| datetime | datetime_with_tz |
|---|---|
| 2023-08-01T06:30:00 | 2023-08-01T15:30:00 |
変換時の挙動
TIMESTAMP → DATETIME への変換
SELECT
TIMESTAMP("2023-08-01 06:30:00") AS original_timestamp,
DATETIME(TIMESTAMP("2023-08-01 06:30:00")) AS datetime_from_timestamp,
DATETIME(TIMESTAMP("2023-08-01 06:30:00"), "Asia/Tokyo") AS datetime_with_tz_from_timestamp
| original_timestamp | datetime_from_timestamp | datetime_with_tz_from_timestamp |
|---|---|---|
| 2023-08-01 06:30:00 UTC | 2023-08-01T06:30:00 | 2023-08-01T15:30:00 |
DATETIME → TIMESTAMP への変換
SELECT
DATETIME("2023-08-01 06:30:00") AS original_datetime,
TIMESTAMP(DATETIME("2023-08-01 06:30:00")) AS timestamp_from_datetime,
TIMESTAMP(DATETIME("2023-08-01 06:30:00"), "Asia/Tokyo") AS timestamp_with_tz_from_datetime,
| original_datetime | timestamp_from_datetime | timestamp_with_tz_from_datetime |
|---|---|---|
| 2023-08-01T06:30:00 | 2023-08-01 06:30:00 UTC | 2023-07-31 21:30:00 UTC |
補足1: 頭がこんがらがりそうになる例
SELECT
TIMESTAMP(DATETIME("2023-08-01 06:30:00", "Asia/Tokyo"), "Asia/Tokyo") AS timestamp_with_tz_from_datetime_with_tz,
DATETIME(TIMESTAMP("2023-08-01 06:30:00", "Asia/Tokyo"), "Asia/Tokyo") AS datetime_with_tz_from_timestamp_with_tz
| timestamp_with_tz_from_datetime_with_tz | datetime_with_tz_from_timestamp_with_tz |
|---|---|
| 2023-08-01 06:30:00 UTC | 2023-08-01T06:30:00 |
補足2: 日付を取り出すには?
DATE() 関数を使う。
- time_zone を指定しなければ、読み取った日時の日付部分を返す(入力が TIMESTAMP, DATETIME ともに)
- TIMESTAMP の入力に対して time_zone を指定した場合、入力を UTC として解釈して、指定された time_zone に変換して日付を取得する。
- DATETIME の入力に対しては time_zone を指定できない。
入力が TIMESTAMP の場合
SELECT
TIMESTAMP("2023-08-01 06:00:00", "Asia/Tokyo") AS original_timestamp,
DATE(TIMESTAMP("2023-08-01 06:00:00", "Asia/Tokyo")) AS date_from_timestamp,
DATE(TIMESTAMP("2023-08-01 06:00:00", "Asia/Tokyo"), "Asia/Tokyo") AS date_with_tz_from_timestamp
| original_timestamp | date_from_timestamp | date_with_tz_from_timestamp |
|---|---|---|
| 2023-07-31 21:00:00 UTC | 2023-07-31 | 2023-08-01 |
入力が DATETIME の場合
SELECT
DATETIME("2023-08-01 06:30:00", "Asia/Tokyo") AS original_datetime,
DATE(DATETIME("2023-08-01 06:30:00", "Asia/Tokyo")) AS date_from_datetime,
--DATE(DATETIME("2023-08-01 06:30:00", "Asia/Tokyo"), "Asia/Tokyo") ← 実行不可能
| original_datetime | date_from_datetime |
|---|---|
| 2023-08-01T15:30:00 | 2023-08-01 |
総論
基本的には常に UTC で表示される TIMESTAMP で扱って、特定の time_zone での日時で表示したい・日付を取り出したいといった場合だけオプション引数で time_zone を指定して DATETIME() ないし DATE() 関数を使うのが良いだろう。
現時点での BQ の課金対象データスキャン量を確認する方法
INFORMATION_SCHEMA の Jobs を見る。
特に、自分の発行したクエリについて調べたい場合、以下のように INFORMATION_SCHEMA.JOBS_BY_USER にクエリを打つ。
SELECT
creation_time,
project_id,
project_number,
user_email,
job_id,
job_type,
statement_type,
start_time,
end_time,
query,
state,
total_bytes_processed,
total_slot_ms,
cache_hit,
total_bytes_billed, -- 課金対象データ量
FROM
`<対象 region(例: region-us)>`.INFORMATION_SCHEMA.JOBS_BY_USER
WHERE
creation_time>="<日付や時刻の指定>" -- partition key になっているので、必ず指定する
total_bytes_billed に課金対象となったデータ量が Byte 単位で入っているので、これを見れば良い。
なお、このクエリ自身も課金の対象になることに注意が必要。
何も絞り込み指定をせずに打つと全スキャンし課金対象の確認に大規模課金が走るという本末転倒なことが起こりかねない。
幸い creation_time で Partition が切られているので、これを利用して絞り込みを行うことを推奨する。
あとは不要なカラムも極力 SELECT から除外するのが良いだろう。
Google Colaboratory から Python で BigQuery に繋ぐ方法
いくつか方法があるものの、以下では pydata_google_auth を用いた方法について記述する。
import pandas as pd
import pydata_google_auth
# project の指定
project_id = "<project_id>"
# credential の取得
## 別ウィンドウで google アカウントによる認証画面が立ち上がる。
## 許可すると認証キーが表示されるので、コピーしてノートブック上の所定箇所に貼り付ける。
## こうすることで、変数 `credentials` に値が入るので、これを後段のクエリ発行時に引数として渡す。
credentials = pydata_google_auth.get_user_credentials(
['https://www.googleapis.com/auth/bigquery'],
use_local_webserver=False
)
# クエリの記述
query = """
SELECT
column1,
column2,
column3
FROM
`<project>.<dataset>.<table>`
"""
# BigQuery にクエリを発行し、結果を Pandas の DataFrame に格納する。
## 先ほどの credentials はここで引数として渡す。
df = pd.read_gbq(query=query, project_id=project, credentials=credentials)
df.head()
補足
BigQuery の UI 上から「Python ノートブックで探索」を選択すると自動で google.colab.auth を用いた認証・接続テンプレートが立ち上がるが、権限不足で動かせないことがあったので上記の方法を採った。
中央値の集計方法
BigQuery で中央値を求める方法について。
-
APPROX_QUANTILESを使う方法 -
PERCENTILE_DISC/PERCENTILE_CONTを使う方法
の2通りがあるが、集約関数として使えることから前者の APPROX_QUANTILES を推奨。
以下、サンプルデータとして下記の1~5の連番データ (sample_data) を用いて解説:
WITH
sample_data1_5 AS (
SELECT
1 AS x
UNION ALL
SELECT
2 AS x
UNION ALL
SELECT
3 AS x
UNION ALL
SELECT
4 AS x
UNION ALL
SELECT
5 AS x )
SELECT
*
FROM
sample_data1_5

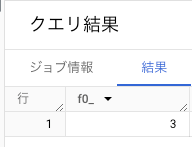
方法1: APPROX_QUANTILES を使う
APPROX_QUANTILES(x,2)[OFFSET(1)] のように集計する。
SELECT
APPROX_QUANTILES(x,2)[OFFSET(1)]
FROM
sample_data1_5
方法2: PERCENTILE_DISC / PERCENTILE_CONT を使う
集約関数ではないため、Window 関数のように OVER() を記述したうえで DISTINCT する必要がある。
SELECT
DISTINCT PERCENTILE_DISC(x,0.5) OVER()
FROM
sample_data1_5
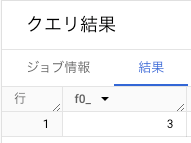
なお、PERCENTILE_DISC と PERCENTILE_CONT の違いは、線形補完を行うかどうか(後述)。
補足: 中央値が一通りに定まらない場合の扱い
データが以下のような 1~6 までの連番だったとする。
この場合、中央値として3,4のどちらを採るべきか判断に困る。
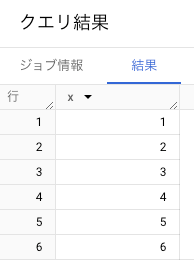
このようなケースでは、PERCENTILE_CONT を使うと線形補間した値を返す。
(APPROX_QUANTILES, PERCENTILE_DISC では、おそらく小さい方の値を返す。)
- PERCENTILE_CONT / PERCENTILE_DISC
SELECT
DISTINCT
PERCENTILE_DISC(x,0.5) OVER() AS median_disc,
PERCENTILE_CONT(x,0.5) OVER() AS median_cont
FROM
sample_data1_6
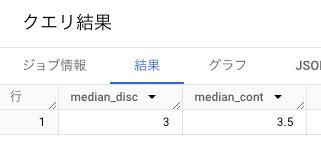
- APPROX_QUANTILES
SELECT
APPROX_QUANTILES(x,2)[OFFSET(1)]
FROM
sample_data1_6
