PlanetScale を AWS Lambda から使ってみた
※本記事は2022/03/14に書いたので、現在では使えない情報があるかもしれません。
PlanetScale[1]とは、『MySQLと互換性のあるサーバーレスデータベースプラットフォーム』です。
AWSで相当するサービスは、Amazon RDS for MySQL や Amazon Aurora MySQL になります。
PlanetScaleの特徴として、『ブランチ』があります。
gitの運用のように、developブランチには開発環境のデータを投入、masterブランチには本番環境のデータを投入、といった使い方ができます。
また、アカウントを作成すればすぐに無料枠の範囲内でRDBが使えるため、検証用の環境としても優れています。
注意点として、「外部キーに対応していない」という点があります。外部キーを利用したい場合、アプリケーション側で外部キーに相当する実装が必要になるようです。
素晴らしいサービスで、これだけで数記事書けてるものだと思いますが、私が詳しくないこともあり、この辺にしておきます。
PlanetScaleの個人記事は現在そこまで多くないのですが、より深く知りたい場合は以下のような記事を読むと良いかと思います。
今回の試したソースはgithubに上げました。
この記事の対象範囲
- PlanetScaleをLambdaから接続する
- DBの接続情報をAWS Secrets Managerに保存して使う
- SAMを利用したLambdaのデプロイ
この記事の対象外
- PlanetScale環境の作成は公式ドキュメント[2]を参考にすること
- SAMの説明
- Pythonコードの説明
- コネクションや速度の検証
AWS Lambda から PlanetScale を使いたい理由
AWSでLambda, APIGatewayといったサーバーレスな構成を使う場合、DBにはDynamoDBを使うことを最初に検討するかと思います。
特に個人や小規模な開発では、値段や構成が楽という観点から、DynamoDBを使おうか、という話になります。
RDSとLambdaを使おうとすると、LambdaをVPC内に入れたり、RDS Proxyを使ったり、RDSのそこそこな料金を気にする必要が出てくるためです。
ところが、DynamoDBを単純にRDBの代わりとして利用することには問題があります。
従来のRDBの考えでDynamoDBを使うと痛い目を見るからです。joinが無いとか、特定のカラムでしか検索が出来ない等です。
DynamoDB特有のデータ設計手法に慣れていない場合、安易にDynamoDBを導入できません。
DynamoDBのデータ設計についてはこの辺りを参考。
ここまでのDynamoDBの懸念点を考えると、Amazon RDSを使いたくなってきます。
特に、NoSQLへの知見があるメンバーがいない場合、RDSを使いたくなります。
ところが、RDSはDynamoDBに比べるとそこそこ値が張ります
例えば、バックアップ無し、シングルAZ、性能の低いdb.t4g.microインスタンスでRDSを構成しても、一か月間で以下くらいの値段になります。
AWS Pricing Calculator[3]にて算出
# インスタンス
1 instance(s) x 0.025 USD hourly x (100 / 100 Utilized/Month) x 730 hours in a month = 18.2500 USD
# ストレージ
30 GB x 0.138 USD x 1 instances = 4.14 USD (EBS Storage Cost)
# 合計
22.39 USD
この値段を毎月、と考えると、個人開発や小規模な開発では手が出ない場合もあると思います。
私も現在、趣味で小規模な開発をしておりますが、RDSのランニングコストを前に手が止まってしまいました。
そこで、ちょうど話題になっていたPlanetScaleを使ってみることにしました。
こういったRDBサービスはAWSのものしか使ったことが無いため、コスト感覚がありませんが、料金表[4]を見てみると無料で使える枠が多いので使ってみようと思いました。
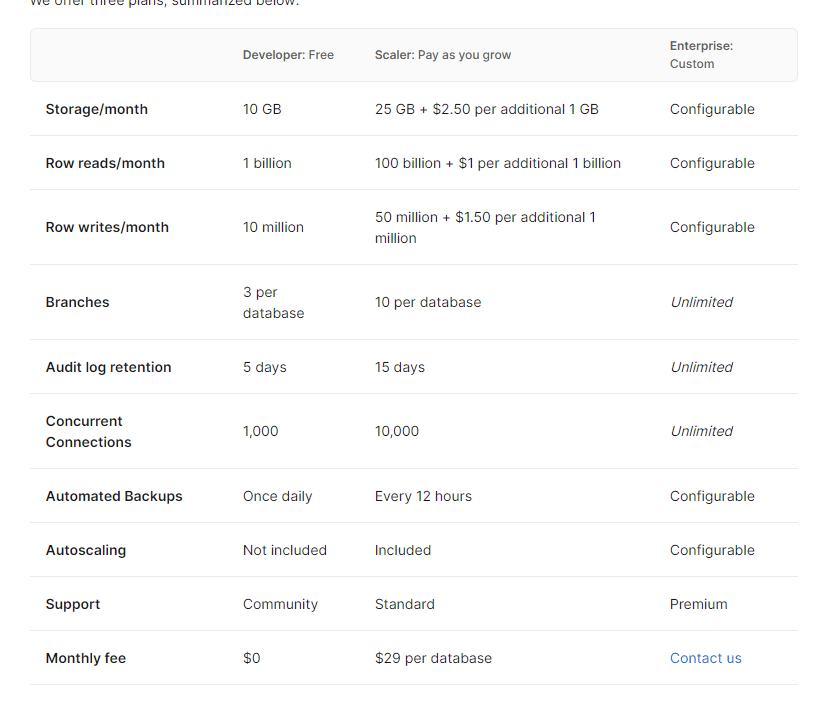
PlanetScaleとLambdaの接続
PlanetScaleの用意
データベースの用意とテストデータの作成まで、PlanetScaleのGUIで行います。
PlanetScale環境の構築
PlanetScale環境の構築は、公式ドキュメント[2:1]を参考に行いました。
ブラウザのGUIでも、PlanetScale CLIでもどちらでも良いと思います。
詰まるところも無かったので、こちらは割愛します。
PlanetScaleのDB接続情報を取得
DBが作成できたら、DBの接続情報を取得します。
HOST, USERNAME, PASSWORD, DATABASEです。
データベースのGUI画面で、Connectボタンを押下すると接続情報が取得できます。
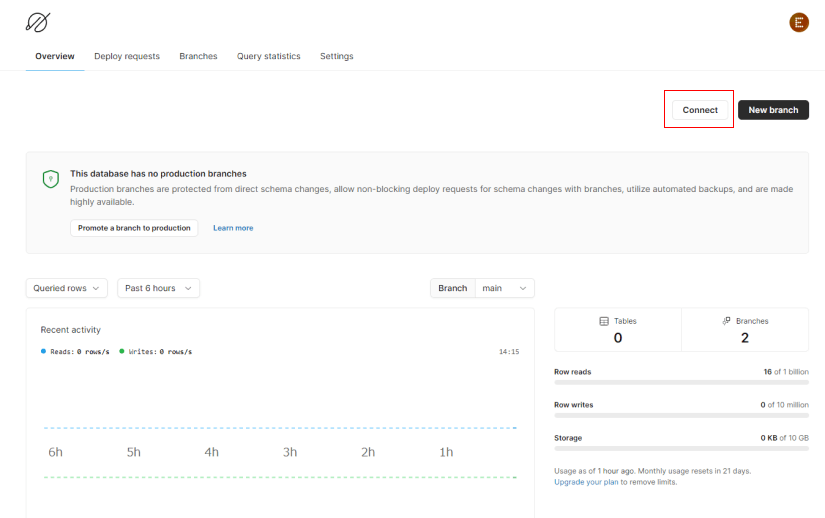
パスワードは最初の1回目しか表示されないので注意が必要です。
もしパスワードを忘れた場合、New Passwordボタンを押下して新しいパスワードを生成します。
今回はLambdaから接続するため、AWS Secrets Manager[5]に接続情報を保存します。
PlanetScaleのコンソールにてテストデータを用意
データベースの画面から、Branchesタブを押下します。
ブランチに入り、Consoleタブに移動するとSQL文が実行できます。
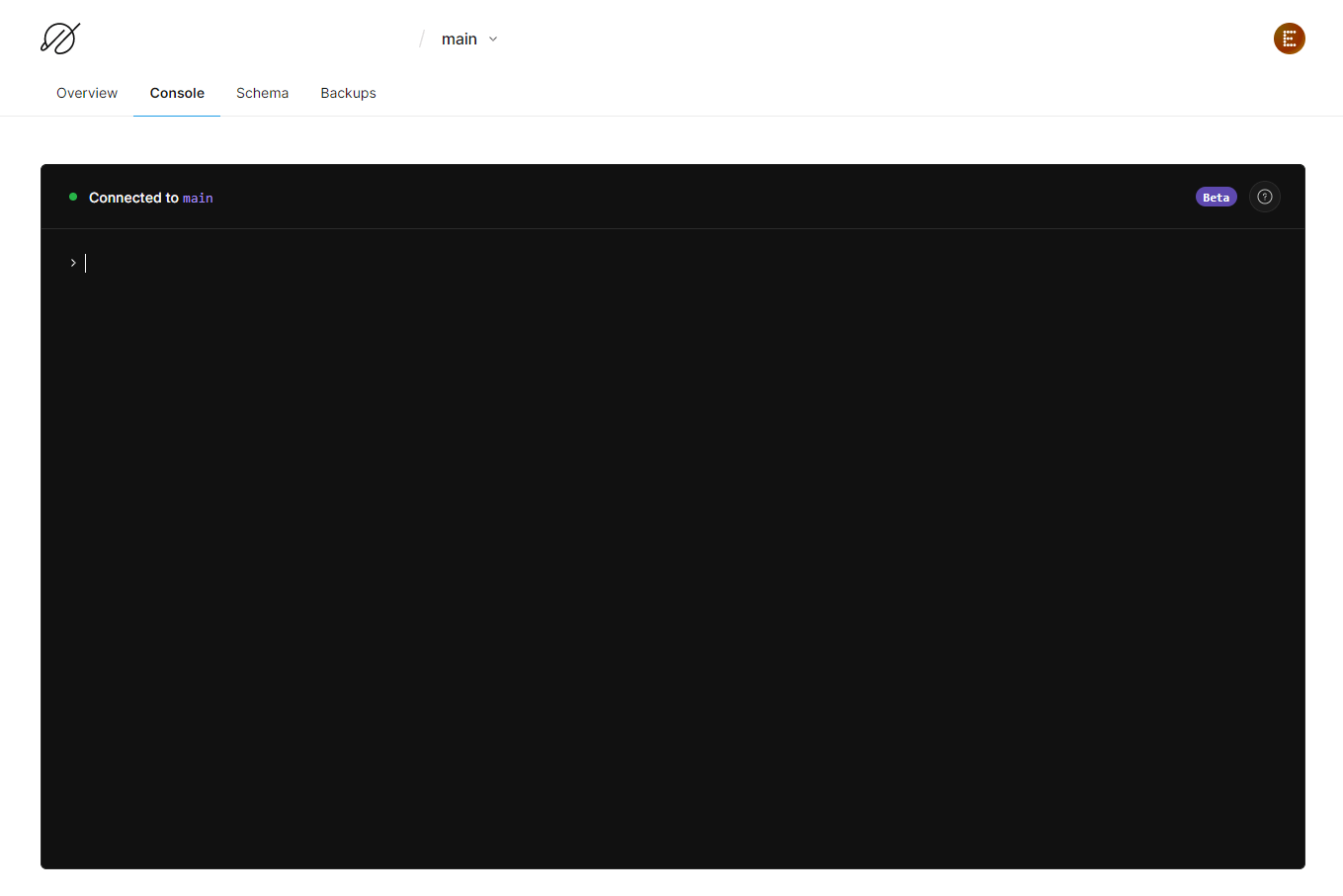
こちらのコンソールにて、公式ドキュメントに記載があるSQLを実行してテストデータを作成します。
CREATE TABLE `users` (
`id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
`email` varchar(255) NOT NULL,
`first_name` varchar(255),
`last_name` varchar(255)
);
INSERT INTO `users` (id, email, first_name, last_name)
VALUES (1, 'hp@test.com', 'Harry', 'Potter');
AWS側の実装
Secrets Managerの設定と、SAMによるLambdaのデプロイを行います。
githubにソースも上げているので、簡単に試したい方はこちらのソースをcloneして試してください。
※Secrets Managerは手作業で設定する必要があります。
AWS Secrets Managerに接続情報を保持
先ほど取得した接続情報をAWS Secrets Managerに保存します。
この後AWS SAMを利用してLambdaをデプロイしますが、Secrets Managerは今回手動で作りました。
マネジメントコンソールからSecrets Managerを開きます。
作成を行います。
データベース用のテンプレートが用意されているので、ありがたく使わせてもらいましょう。
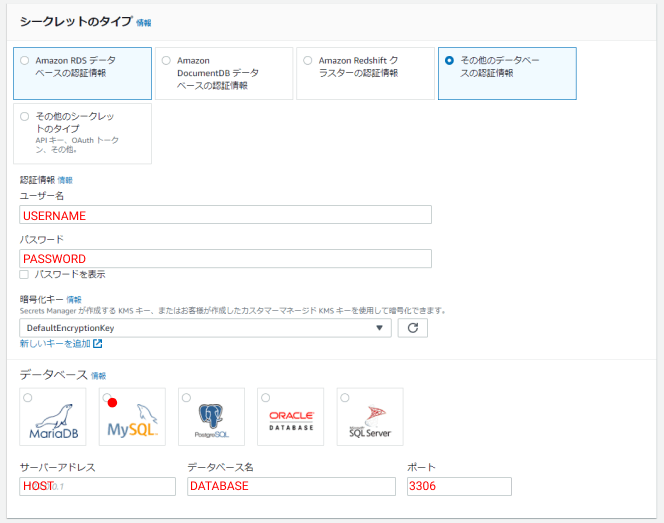
シークレットの名前は「dev/planetScale」にしました。
後でLambdaの環境変数に設定して、使います。同じコードを試す場合は、シークレット名も同じにして下さい。

AWS LambdaのSAMテンプレートを作成
デプロイには、AWS SAM[6]を利用します。
私が慣れている、というだけの理由なので、手動で別の慣れた方法でデプロイされる方はそちらで大丈夫です。
AWS SAMを始めて使う方は、こちらで環境だけ構築してください。
まず、以下のようなフォルダ構造を作成します。
とりあえず、空のファイルで大丈夫です。
PlanetScaleLambda
├─ template.yaml
└─connect-test
__init__.py
app.py
requirements.txt
次に、template.yamlを用意します。SAMでは以下のリソースを作成します。
- Lambda
- IAM Role
IAM RoleはLambdaの基本のIAMポリシーに加えて、Secrets Managerを利用するためのポリシーを付与しています。
Lambdaの環境変数には、先ほどのSecrets Managerのパラメータ名を設定しています。
Transform: AWS::Serverless-2016-10-31
Globals:
Function:
Runtime: python3.9
Timeout: 30
Handler: app.lambda_handler
MemorySize: 128
Environment:
Variables:
TABLE_NAME: data-table
Description: >
PlanetScale Test develop
Parameters:
Env:
Type: String
Default: dev
Resources:
connectTestFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: connectTest
CodeUri: connect-test/
Environment:
Variables:
ENV: !Ref Env
Role: !GetAtt LambdaExecutionRole.Arn
LambdaExecutionRole:
Type: "AWS::IAM::Role"
Properties:
RoleName: !Sub lambda-execution-role-${Env}
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
Policies:
- PolicyName: "lambda-secretmanager-policy"
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Action:
- "logs:CreateLogGroup"
- "logs:CreateLogStream"
- "logs:PutLogEvents"
Resource: "*"
- Effect: "Allow"
Action:
- "secretsmanager:GetResourcePolicy"
- "secretsmanager:GetSecretValue"
- "secretsmanager:DescribeSecret"
- "secretsmanager:ListSecretVersionIds"
Resource: "*"
Pythonの実装
app.pyでは以下を行います。
- SecretsManagerから接続情報を取得
- PlanetScaleとコネクションを確立
- SQLを実行
PlanetScaleはSSL接続が必要なため、certifiというライブラリを使用しました。
import sys
import os
import base64
import json
import boto3
import pymysql
import certifi
from botocore.exceptions import ClientError
connection = None
def get_secret():
env = os.environ["ENV"]
secret_name = f"{env}/planetScale"
region_name = "ap-northeast-1"
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
except ClientError as e:
raise e
else:
# Decrypts secret using the associated KMS key.
# Depending on whether the secret is a string or binary, one of these fields will be populated.
if 'SecretString' in get_secret_value_response:
secret = json.loads(get_secret_value_response['SecretString'])
else:
secret = json.loads(
base64.b64decode(get_secret_value_response['SecretBinary']))
return secret
def initial_setting():
global connection
try:
secret = get_secret()
connection = pymysql.connect(
host=secret['HOST'],
user=secret['USERNAME'],
passwd=secret['PASSWORD'],
db=secret['DATABASE'],
connect_timeout=5,
ssl={
'ca': certifi.where(),
# caファイルを配置する場合
# 'ca': f"{os.environ['LAMBDA_TASK_ROOT']}/ca-bundle.pem",
},
)
except pymysql.MySQLError as e:
print(e)
sys.exit()
# Lambdaハンドラー外で実行することでコネクションを使いまわせる
initial_setting()
def lambda_handler(event, context):
global connection
if not connection:
connection = initial_setting()
with connection.cursor() as cursor:
# Read a single record
sql = "SELECT `id`, `first_name`, `last_name` \
FROM `users` \
WHERE `email`=%s"
cursor.execute(sql, ('hp@test.com',))
result = cursor.fetchone()
print(result)
requirements.txtでライブラリを指定することで、sam build, sam deploy時にライブラリを適用した状態でデプロイできます。
pymysql
certifi
ここまで出来たら、SAMでデプロイします。
SAMでデプロイ
PlanetScaleLamdaをカレントディレクトリになっている状態で、samコマンドを実行します。
PlanetScaleLambda <- カレントディレクトリ
├─ template.yaml
└─connect-test
__init__.py
app.py
requirements.txt
sam build --use-container
sam deploy --guided --capabilities CAPABILITY_NAMED_IAM
ここまで出来たら、Lambdaを実行してみましょう!
Lambdaのテスト実行
AWSマネジメントコンソールにて、該当Lambdaの画面に移動します。
テスト実行してみましょう。
SELECTした結果が取得できていればオッケーです!
感想
とりあえず、PlanetScaleとLambdaの接続が出来てよかったです。
速度やコネクションプールの検証は必要かと思いますが、ひとまずお金を掛けたくないテスト環境や個人開発で利用する際に、使っていけるサービスかとおもいます。
また実際に利用していく上で問題や情報があれば更新していきます!
Discussion
GCP Appengine からも使ってみました。
問題なしでした。
外部キー制約なしの項目はさらえてなかったので助かりました。
まぁ、DBにおんぶに抱っこにならずにアプリ側でがんばれよ。ってことですね。