Snowflakeに移行したらロック待機でパフォーマンス出なかった話
Snowflakeへの移行で遭遇したロック待機とその対策
🎯 この記事のターゲット
- データベース移行プロジェクトに関わっているエンジニアの方々
- Snowflakeへの移行を検討している組織の方々
- システム移行時の想定外の問題に関心がある方々
本記事では、実際の移行プロジェクトで遭遇した問題と、その解決までのプロセスを共有させていただきます。
📖 背景
これは以前投稿したTポイント分析基盤のSnowflake移行プロジェクトで発生した画面検索遅延問題の詳細な技術解説です。現在は完全に解決し、安定稼働していますが、移行時に直面した唯一の重大な問題でした。
さて、トラブルと解決の話を淡々と話をしても面白くないので、今回は物語風に(余計なことを・・)
😱 発生した問題
本番リリース後の週明けに異変が起きました。
😱「えっ、そんなわけないでしょ!?」
ユーザーから「システムが遅い」「移行前の2倍近く時間がかかる」といった報告が相次ぎ、事業部門からも何かトラブルが起きていないか?という深刻な指摘が上がってきたのです。
エンジニアチームでの最初の確認:
🤨「集計処理は正常に見えるけど、画面が遅いとはどういうことだろう??」
😰「画面の反応や画面遷移が固まるというような事を言われました。。」
🤨「ウエアハウスは画面と集計で分離しているし、リソースも余裕があるように見えるけど」
😰「でも明らかに遅くなったって言われてます」
🤨「なるほど、まずは再現テストをしよう。そのユーザーさんの実際のクエリとかを確認して再現してみよう」
そのユーザーからの問い合わせを元にsnowflakeで別面作ってクエリを再現しましたが、全く問題ない状態。
😰「うちの社内では全く再現しないっすね・・本番でもちょっと試しましたが特に問題ない感じでした」
🤨「うーん、了解。ひとまず止血優先と切り分けのためにウェアハウスを上げてみて。画面系ウエアハウスのリソースは問題ないの分かってるけど、ウエアハウス上げて解消するなら、リソース絡みかの判断要素になるでしょ」
🥺「了解です!」
😖「サイズ上げたら、ユーザーさんに申し訳ないけど挙動を見てもらうようにお願いしてください」
😃「分かりました!」
・・・
🥺「上げた後に確認してもらいましたけど、やっぱり遅いみたいです」
🤔「了解。単純なリソース問題ではないって事だね。もう一度考えられる原因を考えよう」
🙄「もしかして、そのユーザーのインターネットが遅いとか?」
🤨「他のユーザーから問いあわせ来てるし、うちがリリースしたタイミングでインターネットが遅くなるとか都合よすぎる。。うちの帯域も逼迫してないし、ネットワークの線はないんじゃないかな」
🥺「ですよね。。」
🤨「やっぱり、アプリだと思う。ファクトを確認しよう。画面系のクエリの時間を全部集計してみて」
🥺「了解しました!」
・・・
🥺「問題と思われる場所が見つかったと思うので、ちょっと説明の時間もらっていいですか?」
🤔「ありがとう。でもなんかややこしそうな雰囲気ね。メンバー集めてMTGしよ」
😟 原因の特定:思わぬボトルネック
🥺「結論から言うとロック待機です。」
🤔「うん?ウェアハウス分けてるのにそんな事起きるんだっけ?」
🙄「集計処理実行した後に集計状態テーブルの更新と集計条件テーブルの書き込みをやってますよね」
🤔「うん、各分析メニューでやってるよね。」
😰「その更新を同時にやってるんですが、集計条件時にリストを指定しているケースがあるのですが、その集計条件リストのInsertがかなり遅くなってます」
😲「・・そゆことか、それで集計状態テーブルが更新待ちになってるってこと?」
😰「はい、そういう事です。」
🤔「いやでも、そこってVerticaの頃から仕様変えてないよね」
😰「はい、変えていませんが、Insert時間が大幅に悪化してます」
🤔「ロード処理とかPoCしたけど、むしろ良くなってたのに??」
😰「この処理は1件ずつループで書き込みやってました。。でその1件ごとの書き込みがVerticaより遅いです。普段は体感するほどではないですが、件数が多いほどオーバーヘッドが出ます」
😵「おぉぅ、なるほど。。確かにBulkInsertは色々試したけど、1件ずつはやってない気がするな。それで集計状態の更新が道連れになってるのね。。」
😰「はい、件数少ないと体感するほどではないですが、集計条件に商品リストとか指定して、1000件とか超えるとかなり伸長して、それが終わるまで画面更新や次の画面遷移が待たされています」
🔍 処理フロー図
これまでの状況を総括すると、Verticaを使用していた時代には特に問題は発生していませんでした。しかし、Snowflakeへの移行後、集計条件のリスト登録処理がボトルネックとなり、画面遷移時に参照する集計状態テーブルの更新待ちが発生しました。その結果、ユーザーに認識されるほどの画面表示遅延が発生しています。
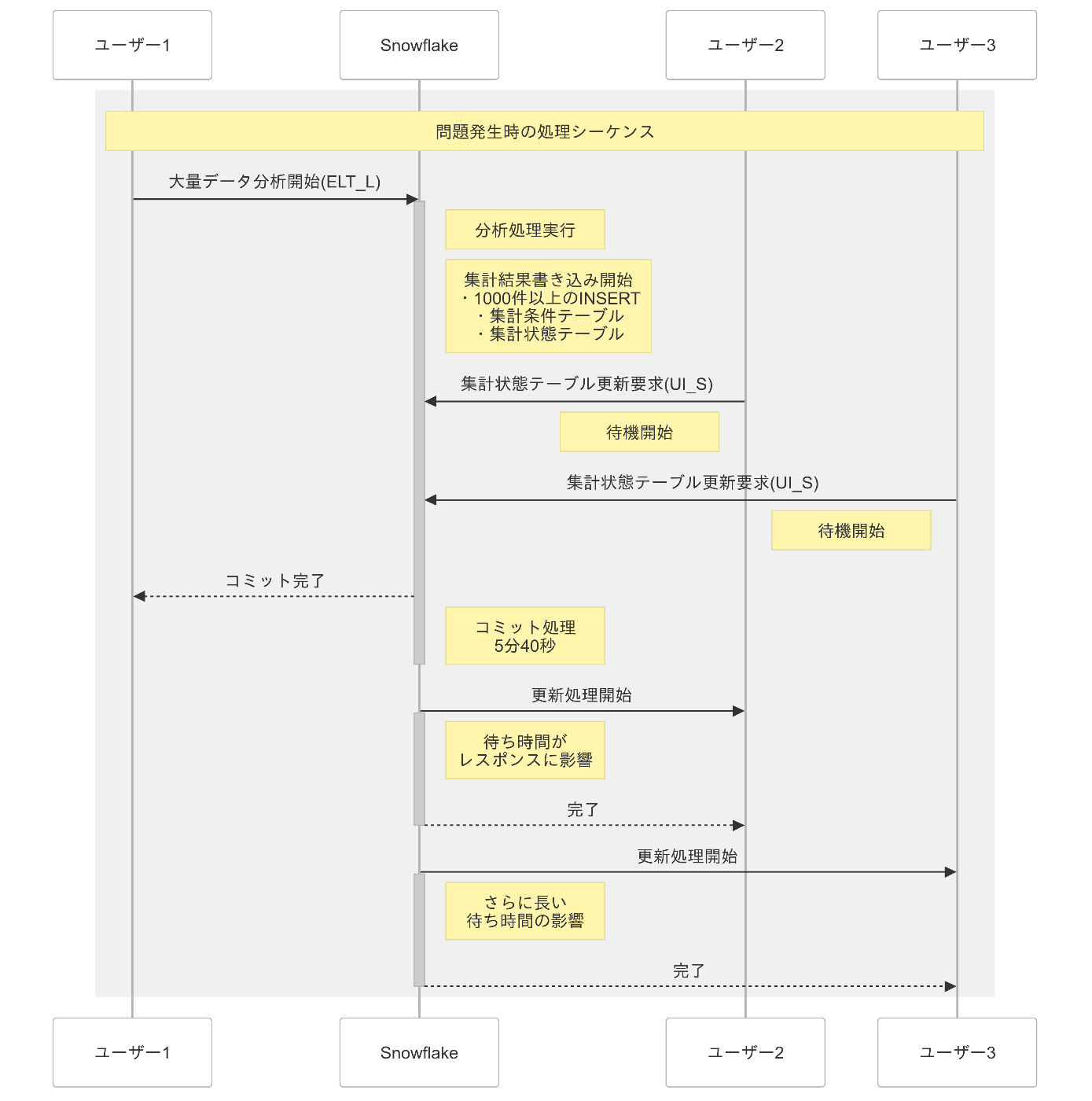
これは完全にプログラムの構造的な課題でした。
💡 解決への道のり
🤔「状況は理解したけど、これアプリ直すしかないよね?」
😰「はい、各処理全部直す必要あります」
🤔「改修内容は集計ステータと集計条件の更新トランザクションの分離だよね?」
🥺「はい、それを直す改修になります」
🤔「遅い!というクレームが常にある訳じゃないから、同時に大量書き込みする処理って限られてない?」
😲「あ、そうですね。こういう大量出力が起きやすいのは、〇〇処理と△△処理です」
🤔「了解。これ、集計条件はメニューごとに書き込みテーブルで異なるから、それぞれテストしないといけないよね」
😰「はい、そうなります。後そもそも1件ずつ更新からBulkInsertへ変更したいと考えています」
🤔「あ、確かに。そこも手を付けた方がいいね。それなりに改修コストかかりそうだな。ちなみに一番発生頻度が多いのは〇〇かな?それをまずはリリースして全体影響を減らしたい」
🥺「はい。一番多いのは〇〇です。全体の改修となるとかなり時間かかりますが、〇〇だけを先にリリースは可能です。段階リリースすると全体の改修期間は増えますが。。
🤔「いや、先に少しでも改善するのが大事。緩和する事で少しでも分析が利用できるようにして、クレームを多少でも減らしたい。事業サイドも困っているし、1ヵ月後にまとめて改善よりも毎週でもだんだん改善される方が対策を進めているとユーザーにも言いやすい。」
😲「了解です。確かに優先順位付けてやった方が良いですね」
🤔「それと並行して△△のリリースも準備して。その2つが片付けば後は発生頻度低いし、そもそも書き込み件数も頻度も多くない」
😲「了解です。取り急ぎ〇〇処理の改修進めて、改善効果見ながらそれぞれ進めます」
😩「不具合を早く解消したいが、焦っての二次災害は避けよう。事業側に対応計画を報告するので、丁寧に進めて」
🥺「了解です!」
その後、最速の日数で〇〇処理のリリースを先行で行い、その日の画面系のクエリ実行時間を確認し、大幅に解消している事を確認しました。
トランザクション分離を行ったことでロック待機は大幅に削減され、BulkInsertにより10秒~数分かかっていた処理も1秒~数秒レベルまで改善されました。
その後、△△処理、その他処理と順次リリースし、最終的に問題は解消し、安定稼働に回復しました。
教訓と反省
📓 見落としの背景
- 移行コスト削減のため、非互換箇所以外は極力既存踏襲
- PoCで性能向上を確認できたため、個別の最適化よりも性能試験での最終確認を重視
🖊 主な反省点
-
評価方法の不備
- 個別機能の性能評価は実施
- 実際のユーザー操作を想定した複合的な評価が不足
-
トランザクション設計の見落とし
- 複数ウェアハウス間での処理干渉を想定せず
- 1件更新処理の劣化による影響を過小評価
🔍 改善後の処理フロー
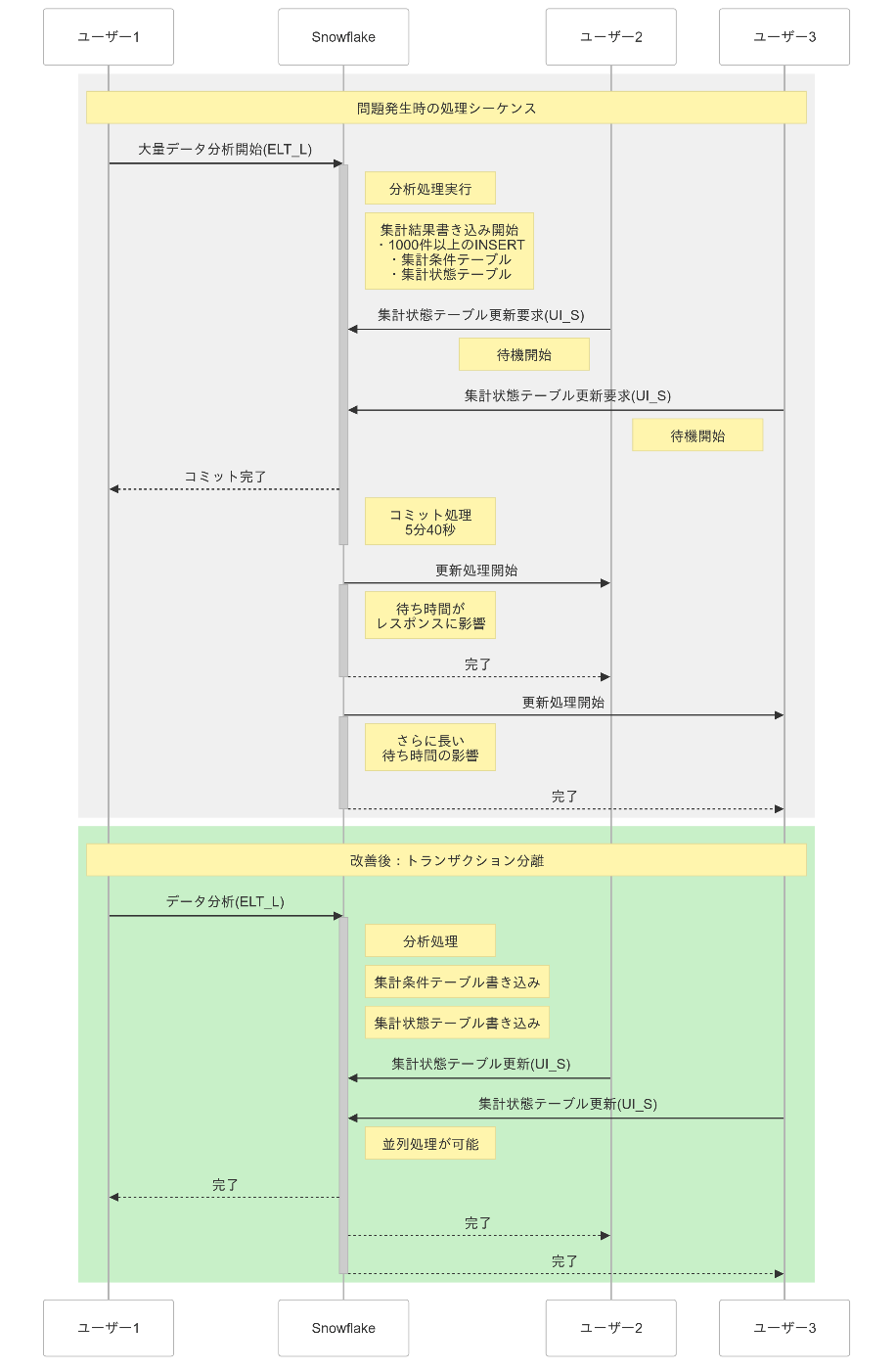
・トランザクションの分離
・BulkInsertへの変更
・集計状態テーブルの更新待ちを解消
🎓 学んだ教訓
-
移行元DBの特性に最適化された処理をそのまま移行しない
- 各DBには得意・不得意がある
- 移行先DBの特性を理解することが重要
-
パフォーマンステストの観点
- 単純な動作確認だけでなく、複数ユーザーでの同時実行テストが重要
- 実際の利用パターンを想定したテストを(可能な限り)
- 更新頻度の高い処理や複合トランザクションの充分な評価
-
トランザクション設計の重要性
- 「動けばいい」は危険
- DBの特性に応じた適切な設計が必要
- トランザクションの分離を意識した非同期化
🌟 おわりに
システム移行では「動作確認」だけでなく「適切な動作」の確認が重要となります。この経験は、私たちに以下の重要な教訓を残しました:
1.DBの特性に応じた適切な設計の重要性
2.実環境を想定した総合的なテストの必要性
またトラブルにおいて、顧客目線で最もよい対応方法を考える視点も大事だと考えています。
今回においては効率良く対応するために一気に直すよりも、ユーザーの不満を早期に緩和するために、時間・コストがかかっても段階的なリリースを選択しました。
現在進行中のOracle移行では、この経験を活かし、より慎重な検証を行っています。
これから移行プロジェクト進めようしている方々の参考になれば幸いです。皆様の経験やご意見もぜひコメントでお聞かせください。
参考情報
最後に、Snowflakeのユーザーコミュニティには、より豊富な知見や経験をお持ちの方々が多くいらっしゃいます。
導入をご検討の際は、ぜひコミュニティへの参加もご検討ください。
Discussion