Podのリソース余剰を解消した話
この記事は Kubernetes Advent Calendar 2022 の 14 日目の記事です。
概要
こんにちは、 DMM.com の 22 新卒サーバーサイドエンジニアの Tao です。
この記事では、弊社のマイクロサービスプラットフォームにおいて、認証認可サービスの Pod リソース設定を最適化し、最適化前後で 30% 以上の余剰解消を実現した手順について紹介します。
最適化に取り組んだ背景
DMM の各サービスが共通して利用する基盤機能を開発・運用するプラットフォーム事業本部は、マイクロサービスアーキテクチャを採用しており、各チームが開発するアプリケーションがマルチテナント型の k8s クラスタ(マイクロサービスプラットフォーム)上で動いています。
このクラスタ全体のコスト最適化のためには、それぞれのマイクロサービスに割り当てるリソース設定の調節が不可欠です。とはいえ、 k8s クラスタを管理するチーム(マイクロサービスアーキテクトチーム)が各マイクロサービス一つ一つについて最適なリソース割り当て値を探し出すのは困難です。
そこで、まずは私が所属する認証認可チームがリソース設定の最適化に取り組み、各マイクロサービスを開発するチームが再現できるような、負荷試験手順やリソース設計方針の検証を行いました。
認証認可サービスのリソース設定と余剰
認証認可チームが開発・運用している認証認可サービスは Go 製アプリケーションであり、 k8s の各リソース設定は以下の通りでした。
Pod
| 項目 | 値 |
|---|---|
| CPU requests | 350m |
| CPU limits | 1000m |
| Memory requests | 128Mi |
| Memory limits | 512Mi |
HPA
| 項目 | 値 |
|---|---|
| minReplicas | 12 |
| maxReplicas | 100 |
| スケール閾値 | 平均 CPU 使用率 60% |
下図は、この設定で稼働するアプリケーション Pod の 1 日における CPU requests に対する CPU 使用率の推移(%)です。

1日の CPU requests に対する CPU 使用率の推移 (%)
これを見ると、平時 (9:00-17:00) の CPU 使用率は 30% 〜 40% の間に収まっていることがわかります。また、ピーク帯でも CPU 使用率は 60% 前後にとどまっており、1 Pod あたりのリソースを余らせてしまっていました。
このリソース余剰は、CPU requests と minReplicas の設定が大きいこと、そして HPA のスケール閾値 (平均 CPU 使用率 60%) が低いことに起因します。
そこで、安全稼働を意識しつつリソース効率を向上できるように、設定値の見直しを行いました。
各リソースの設計方針
各リソースについての設計方針と見直した設定値は以下の通りです。
CPU / Memory requests
この値が大きすぎると、 k8s クラスタのノードに Pod を立ち上げることができなくなったり、ノードのスケールが必要になることで Pod の立ち上げが遅くなる可能性があるため、可能な限り小さい値を指定することにします。
また、CPU, Memory が両方とも同じ消費割合になるように調整します。具体的には、 CPU 使用率が 80% のときに Memory 使用率も 80% になるのが理想です。
CPU / Memory limits
limits で指定したリソースは requests のように " Pod が確実に確保できるリソース" ではないため、ノードに余剰リソースがない場合は limits で指定した値まで消費できません。また値が大きすぎるとノードのリソースが食いつぶされてしまいます。
とりあえず今回は、想定以上の負荷が来た際に Pod がスケールするまでの時間を稼ぐことができそうな、 requests の2倍の値を指定することとします。
minReplicas
日中の平均 RPS を CPU 使用率 80% 弱で捌ける Pod 数を指定します。
maxReplicas
起こりうる最大 RPS を捌ける台数を指定します。それ以上の負荷がきた場合でも、 CPU/Memory limits の値を requests の2倍に設定しているので対応できる想定。
スケール閾値 (CPU averageUtilization)
下図はピーク時間帯の、各 Pod における CPU requests に対する CPU 使用率の推移です。
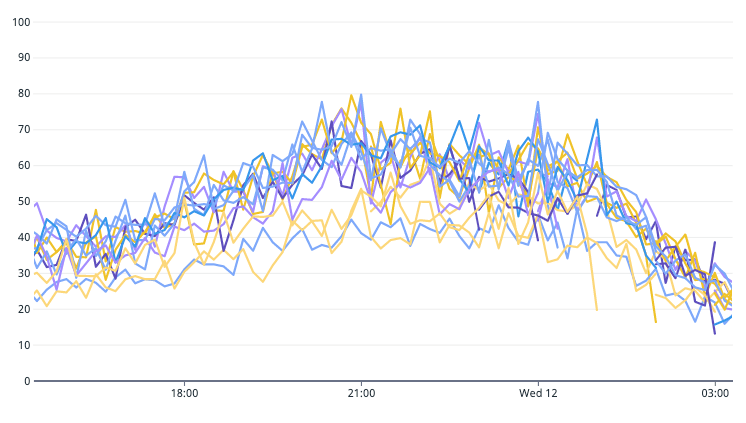
各Podにおける CPU requests に対する CPU 使用率の推移 (%)
HPA のスケール閾値は CPU 使用率 60% で運用していますが、一部の Pod は 80% まで CPU 使用率が増加していることが分かります。
この運用実績から、ピーク時間帯にかけて CPU リソースに 2 割は余裕がある状態が望ましいと判断しました。よってスケール閾値は CPU 使用率 80% とします。
(本来は 80% の閾値でオートスケールが正しく機能するかについて負荷試験を行って確認する方が良いですが、今回は省略しました。)
負荷試験の必要性
以上のリソース値のうち、CPU / Memory requestsにどれだけ小さい値を指定できるか?については検証する必要がありました。値が小さすぎるとアプリケーションが立ち上がらなくなったり、レイテンシが悪化する恐れがあるためです。
また minReplicas を求めるためにも CPU 使用率 80% 前後でのアプリケーション Pod の性能 (何 RPS 捌けるか?) を測定する必要があり、負荷試験を行って確かめることにしました。
負荷試験の実施
DMM のマイクロサービスプラットフォームには分散負荷試験ができる社内基盤が存在します。この負荷試験基盤について詳しく知りたい方は、先日の CloudNative Days の発表スライドが公開されていますのでご参照ください。
CPU/Memory requests および minReplicas の値は、この社内基盤で以下の2試験を行い決定しました。
- CPU 使用率 80% 前後でのレイテンシ悪化がない最小の CPU requests を求める
- CPU 使用率 80% のとき、Memory 使用率も同様に 80% となる Memory requests を求める
1. CPU 使用率 80% 前後でのレイテンシ悪化がない最小の CPU requests を求める
手順
CPU requests/limits の値を同じ値 (100m, 200m, 300m, 400m) に設定したアプリケーション Pod を用意し、負荷を 10rps, 25rps, 50rps, ..., と増やしながら CPU 使用率とレイテンシを計測する。
結果
CPU requests ごとの CPU 使用率と99パーセンタイルレイテンシの関係は以下の通りとなりました。
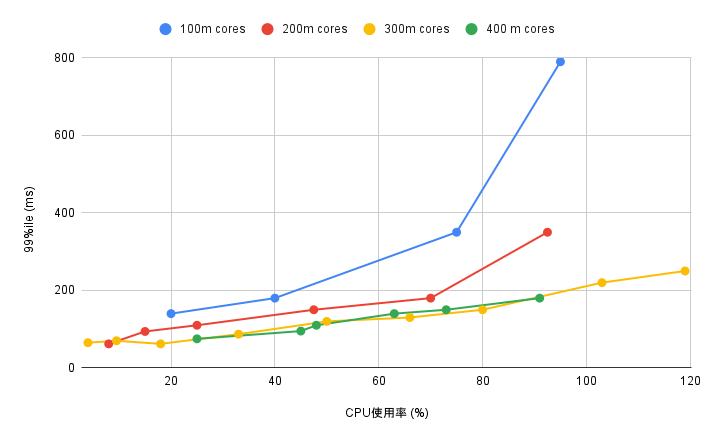
CPU 使用率 (%) と99パーセンタイルレイテンシ (ms) の関係
この結果から、CPU requests が 300m cores 未満の場合について以下のことが分かります。
- CPU 使用率に関わらずレイテンシが悪化すること
- CPU 使用率 80% 前後でのレイテンシ悪化が著しいこと
よってレイテンシ悪化がない最小の CPU requests 値として、 300m cores を採用することにしました。
2. CPU 使用率 80% のとき、Memory 使用率も同様に 80% となる Memory requestsを求める
手順
CPU requests を 300m cores に設定し、 Memory requests の値を変更しながら、 CPU 使用率 80% 弱で捌ける RPS* の負荷をかけ、 Memory 使用率を計測する。
*この値は1.の試験結果から得られたもの
結果
78Mi というかなり小さい requests 値で Memory 使用率が 80% 弱となりましたが(下図)、現行の 128Mi からの減少幅が大きいため、 Memory requests 値には 100Mi を採用しました。
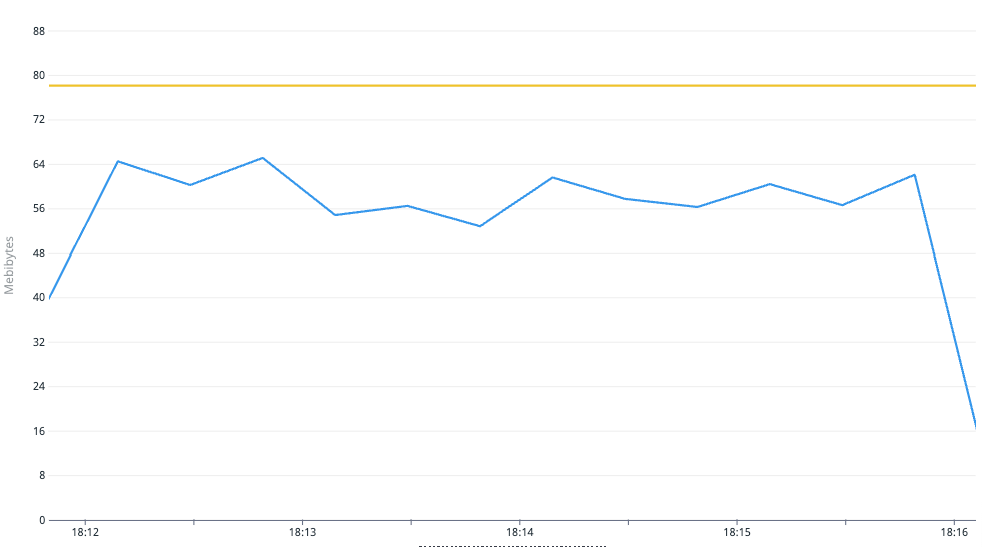
負荷試験実施中の Memory 使用量 (青色,単位:MiB) と Memory requests 値 (黄色,78MiB)
新しいリソース設定値とその適用結果
以上の設計方針および負荷試験結果を踏まえ、最適化した新しいリソース値は以下の通りとなりました。
| 項目 | 既存の値 | 新しい値 | 方針・根拠 |
|---|---|---|---|
| CPU requests | 350m | 300m | 負荷試験の結果から |
| CPU limits | 1000m | 600m | requests の2倍 |
| Memory requests | 128Mi | 100Mi | 負荷試験の結果から |
| Memory limits | 512Mi | 200Mi | requests の2倍 |
| minReplicas | 12 | 7 | 平時のリクエストを CPU 使用率 80% 弱で捌ける台数 |
| maxReplicas | 100 | 150 | 起こりうる最大 RPS を捌ける台数 |
| スケール閾値(平均 CPU 使用率) | 60 | 80 | 安定稼働とリソース効率を意識 |
レイテンシの悪化が起こらない範囲で CPU requests には小さな値を指定し、 minReplicas やスケール閾値についてもリソース効率を重視して切り詰めました。
この新しいリソース設定値を適用した結果を以前と比較すると、 Pod の平均 CPU 使用率は以下のようになりました。
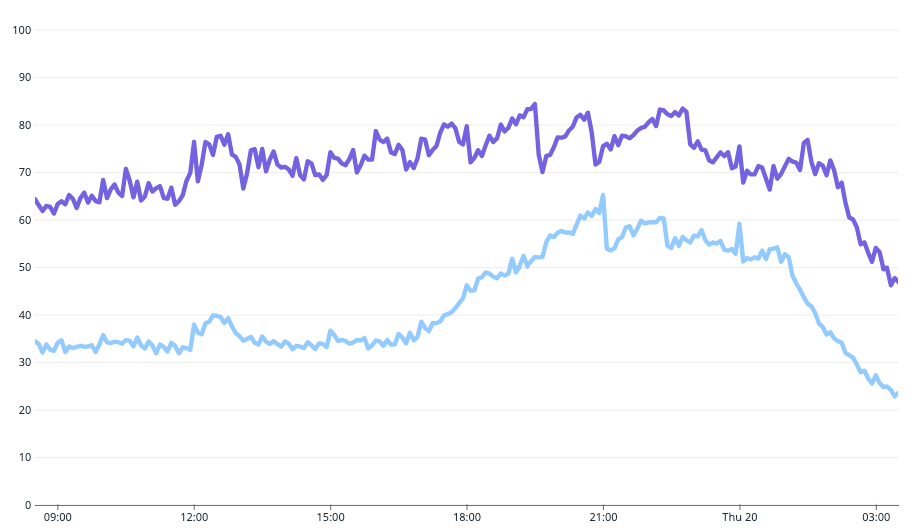
Pod の平均 CPU 使用率の推移 (水色: 最適化前 / 紫色: 最適化後)
最適化前は 30 - 60% を推移していた値 (水色) が、最適化後は 60 - 80% で推移するようになり (紫色)、リソース効率が大幅に向上したことが分かります。
また以下の図は1日の Pod 数の推移を比較した図ですが、余剰 Pod が削減され、さらに、リクエスト増加に応じた柔軟なスケールも可能になったことが分かります。
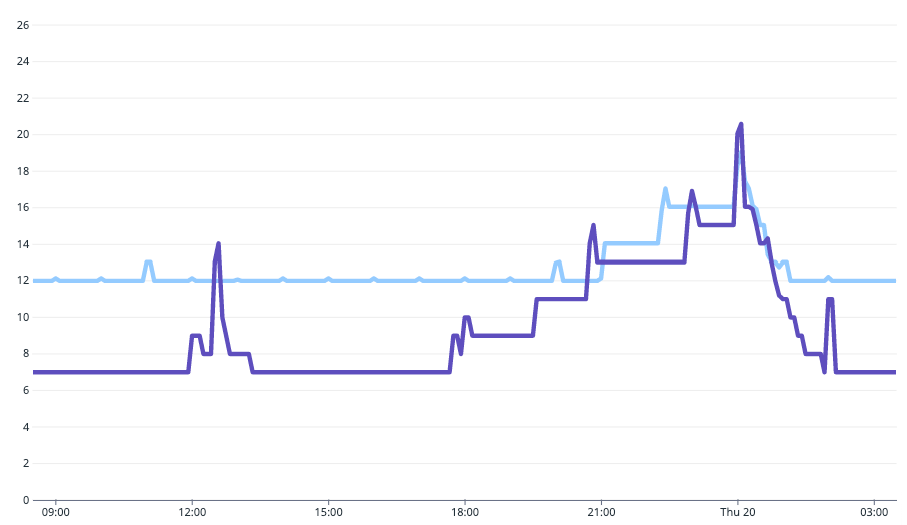
Pod 数の推移 (水色: 最適化前, 紫色: 最適化後)
具体的には、
- 平時 (9:00-17:00) の Pod 数が大幅に削減された
- 昼の時間帯 (12:00-13:00) の一時的なリクエスト増加にも対応するようになった
- 夕方 (18時頃) からピーク時間帯にかけて、徐々に Pod 数が増加するようになった
などの変化が見られます。
まとめ
この記事では、Pod のリソース設計の方針とその最適な値を求めるための負荷試験手順を紹介しました。
結果的に、リソース設定最適化前後の一ヶ月を比較すると、 CPU requests を 31.7 %、 Memory requests を 37.9 % 削減することができていました。
CPU / Memory limits をとりあえず requests の2倍にしてみたり、 HPA 閾値を変更してオートスケールがうまくいくかの確認も省略したりと、雑な部分もありましたが、想像以上にうまくいったので驚いています。
正常に動いているアプリケーションのリソース値を切り詰めることは、リスクもあり、なかなか取り組みづらいことですが、最適値を求める負荷試験手順や設計方針の検証ができてよかったです。
余談
記事内でも紹介しましたが、 DMM のマイクロサービスプラットフォームやその運用をするマイクロサービスアーキテクトチーム、負荷試験基盤について興味のある方は以下の記事・スライドをご覧ください。
- Microservices Architect in DMM Platform
- DMMプラットフォームを支える負荷試験基盤
- k8s 上の負荷試験基盤でロードテストを効率化するために新機能を追加した話
Discussion