DB設計・クライアント・マイグレーション・自動生成ツール「N-DEV」にSQLファイル読み込み機能を追加した話
N-DEV
まだまだ開発中ですが、、、
以下(Vercel)で公開中です。現在無料!!
N-DEV
基本的なSQLは同じと思いますが、MySQLを対象にしてます。
他の機能については以下の記事を参照してください。
また、バグや機能追加のアイデア等は是非コメントでお知らせください。
記事等も是非に
はじめに
閲覧ありがとうございます。株式会社NEXSの「たぬき教祖」です。
この度「N-DEV」に「SQLファイル読み込み機能」が追加されました。
特にMySQLのダンプファイルから(mysqldump 等)DB構造をロード可能になりました。
これまで「ホストに接続してDB構造を取得」する機能はありましたが、それとどう異なるのか、実際にはどのようなライブラリを使用しているのか、どのような処理をしているのか等について解説したいと思います。
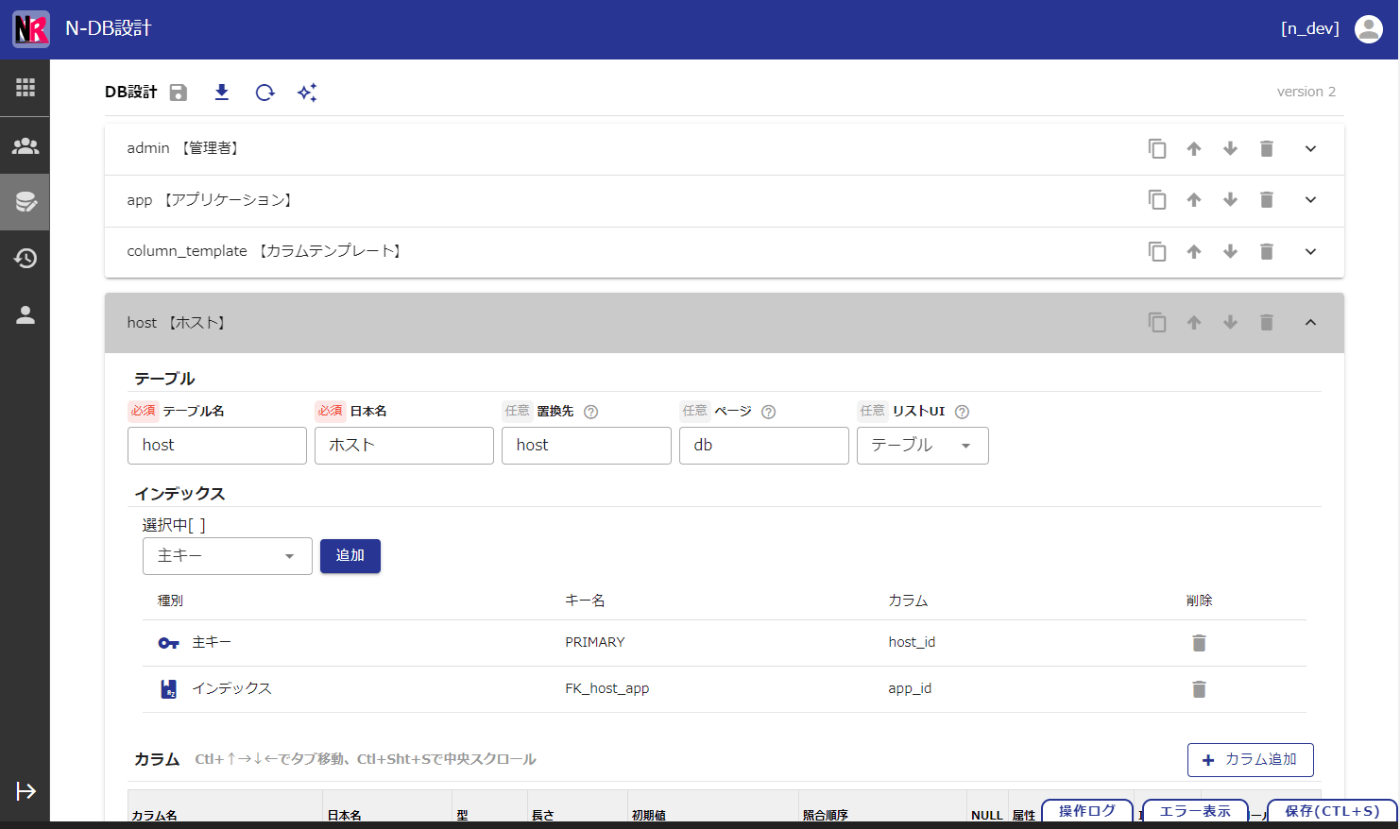
なお本機能はDB設計ページの以下のボタンから使用します。

DB構造(ダンプファイル)の取得方法
SQL(今回は特にMySQL)の構造を取得する方法はさまざまにあるかと思いますが、ここでは「N-DEV」の想定する3つの方法と特徴について列挙します。
mysqldump コマンドを使用する
DBのバックアップとして最も一般的に用いられるのは「mysqldump」かと思います。
もっとも、実際は自動化・cron化されていて意識することはあまりないとは思いますが。
例えばMySQLをインストールしているWindowsでroot権限で特定のDBの構造を出力する場合、以下のようなコマンドをたたくことになります。
mysqldump -uroot -p -d DB_NAME > OUTPUT_FILE
このようにして出力したファイルは例えば以下のような内容の並んだファイルを出力します。
CREATE TABLE `log` (
`log_id` bigint unsigned NOT NULL AUTO_INCREMENT,
`log_type` int unsigned NOT NULL,
`error_number` int unsigned NOT NULL DEFAULT '0',
`log_time` datetime NOT NULL,
PRIMARY KEY (`log_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
特徴としては、出力の方法によって構造のみであったり、データを含んでいたりするため、不要な情報を削除する手順が必要です。
DBに接続して構造を取得する場合(SHOW CREATE TABLE)
N-DEVで採用している方法ですが、遠隔のDBに接続して「SHOW CREATE TABLE」文でDB構造を取得する方法です。
DBに接続する場合、SQLは実行できますが、「mysqldump」などのコマンドは実行できません(多分)ので、「SHOW CREATE TABLE テーブル名」文で、対象のテーブルを作成するSQL文を取得する方法を取っています。
この方法では一気にDB内の全てのテーブルの構造を取得することはできません。
まず「SHOW TABLES」でDB内のテーブル一覧を取得したうえで、それぞれのテーブル名で「SHOW CREATE TABLE テーブル名」を実行します。
一見すると手間のようですが、それぞれのテーブルとCREATE文が一致しますし、余計なデータが入らないことから、処理としてはかなりありがたいです。
取得されるデータは例えば以下のようなデータで、「mysqldump」より少し詳細な気がしますが、ほとんど変わらないと思われます。
CREATE TABLE `maps` (
`map_id` bigint unsigned NOT NULL AUTO_INCREMENT,
`group_id` bigint unsigned NOT NULL,
`map_title` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
`map_dateTime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`map_id`),
KEY `map_rand` (`map_rand`),
KEY `maps_ibfk_1` (`group_id`),
CONSTRAINT `maps_ibfk_1` FOREIGN KEY (`group_id`) REFERENCES `at_groups` (`group_id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
phpMyAdmin から出力する場合
公式的な出力方法は上の2つと思いますが、私がよく使用しているのは「phpMyAdmin」の「エクスポート」機能を使用してSQLファイルを出力する方法です。開発環境では「phpMyAdmin」や他のSQLクライアントツールからエクスポートすることはかなり多いと思います。
「phpMyAdmin」から出力されるデータは上の2つとはかなり異なったものになっていて、今回その対応をすることになりました。
まずは取得されるSQLファイルですが、以下のような内容になっています。
CREATE TABLE `table1` (
`column_id` bigint UNSIGNED NOT NULL COMMENT '',
`sample_text` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL DEFAULT 'this is sample default' COMMENT 'サンプルのID',
`geo1` geometry NOT NULL,
`unique1` int UNSIGNED NOT NULL,
`unique2` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`fulltext1` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`foreign1` bigint UNSIGNED NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
ALTER TABLE `table1`
ADD PRIMARY KEY (`column_id`),
ADD UNIQUE KEY `unique_key_name` (`unique1`,`unique2`),
ADD SPATIAL KEY `geo1` (`geo1`);
ALTER TABLE `table1` ADD FULLTEXT KEY `fulltext1` (`fulltext1`);
ALTER TABLE `table1`
MODIFY `column_id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '';
ALTER TABLE `table1`
ADD CONSTRAINT `table1_ibfk_1` FOREIGN KEY (`column_id`) REFERENCES `table3` (`table3_id`) ON DELETE CASCADE ON UPDATE CASCADE;
どのような構造になっているかというと、まずテーブル、カラムを作成するCREATE文があって、後から「AUTO_INCREMENT」や各種キー、制約を付け加えるALTER文がある、という構成になっています。
なぜこのような構成になっているかは不明ですが(調べてないので)、外部キー制約を加える際、その対象が存在していないのは不自然ですので、全てのテーブルが作成されてから外部キー制約を加える、という手順になっているのは納得のいくところではあります。
特徴として、これまでは無かったALTER文についても解析の対象とする必要があります。
この部分で、他の方法より僅かに手間が増えます。
SQL文のパース方法
ステートメントへのパース
SQL文のパースというと、SELECT文やCREATE文(ステートメント)のパースが想像されますし、実際そのようなライブラリは色々出てきますが、ファイル読み込み時に意外と苦労するのは、ステートメントの集合であるファイルをステートメントにパースする作業です。
ファイルには様々なステートメントが存在しますし、改行もまちまちです。
このようなパースをするライブラリとしてまず使用したのが「node-sql-reader」です。
こちらはクライアントでも動作し、一般的なSQL文の集合をステートメントにパースすることができます。ただ、MySQLのダンプファイルには以下のような、一般的なSQL文とは異なる処理(コメント)部分が入ります。
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
「node-sql-reader」はこのような処理部分でうまく動作せず、正しくパースできませんでした。
現在使用しているのは「@verycrazydog/mysql-parser」で、こちらは上記処理部分を含めて正しくパースできます。
ただ、こちらはクライアント側で使用するとエラーが発生しましたので、APIとして運用してます(詳細不明)。
また、このような手順でパースした各ステートメントについて、「CREATE TABLE」と「ALTER TABLE」で始まるものだけを残して処理しています。
ステートメントのパース
技術としてはこちらのほうが難しいとは思いますが、こちらの方が標準的なライブラリがありましたのでパース自体はすんなりいきます。
使用したライブラリは「node-sql-parser」になります。
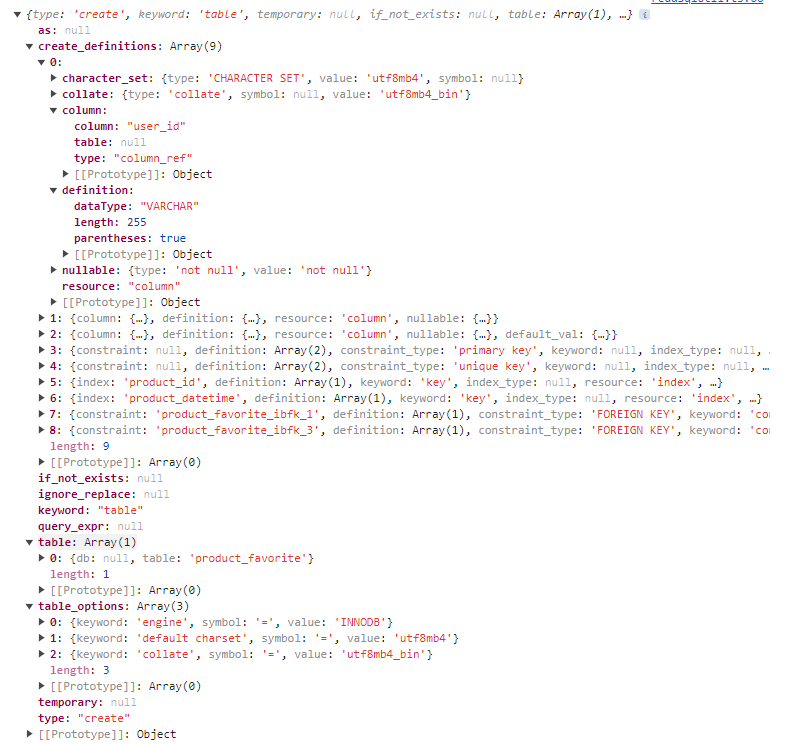
上記方法でパースした各ステートメントをさらにASTという形式にパースします。
パースしたデータは以下のような形式になっています。恐らく一般的な構造だとは思いますが、結構複雑ではあります。
ASTとは
さて、恐らくほとんどのSQLパースライブラリがそうと思いますが、「node-sql-parser」はステートメントをASTという形式にパースします。
ASTと調べると「アスパラギン酸アミノトランスフェラーゼ」が大量に出てきてしまいますが、ここでは「abstract syntax tree」、「抽象構文木」のことです。まあ詳しい説明はGoogleさんにお任せすることとして、意味のある部分のみを抽出した木構造です。
この構造を使用すれば、改行やクォートの違いなどに関わらず、同じ動作をするSQL文は同じ構造になり、扱いやすくなります。
逆に、この木構造を作ってやればSQL文に直すことも可能です。
なお、本来は「N-DEV」においてもこのAST構造のまま取り扱うのが良いかとは思いますが、かなり複雑であるのと、冗長な部分もあると感じているので、内部的には独自形式に直しています。
わかりにくすぎてSQLを作成する部分についてはASTを使用せずに実装している部分もあります。
ちなみに、ASTの対称にCSTがあるようで。こちらは抽象的ではなく具体的、というか普通の木構造になるのか?わかりませんが、
兎も角、コメントや空白、大文字小文字などを含めて厳密に再現できるのがCSTだそうです。
参考:https://github.com/nene/sql-parser-cst
おわりに
というわけで、SQLをDB以外で扱いたい方の参考になりましたら幸いです。
今回、自分で公開(WEB)版のこのシステムを使おうとして驚いたのが、「localhost」のDB構造を取得しようとしてもできない!!!(当たり前ですが)
更に、じゃあ運用しているサーバにアクセスしてもらってこよう,,, 外部からアクセスできない!!!(普通ですが)
SQLファイル読み込み機能がないと中途利用がほとんどできないことに気付きました。
逆にずっと開発環境で使ってきましたので気付かなかったんですね。
怖いことです。
直接ホストにアクセスさせるのが怖いという方も、これで安心して使えるようになったかと思います。
まだ実装したばかりで不具合等もありそうな気がしますが、
是非ご活用ください。
Discussion