テキスト読み上げソフトウェアのVOICEVOXをLinuxで使ってみて思ったこと
RSSになんか面白そうなものが流れてきたので触ってみました
この記事執筆時点ではWindowsのみ対応みたいです
とりあえずzipファイル解凍して中のVOICEVOX.exeを実行すれば動くらしいのでwineで起動してみましたが起動しませんでした
中身を軽く見てみた所
このelectron製のフロントエンドアプリがVOICEVOX.exeでこいつがバックグラウンドで
これを起動するみたい
これは音声合成エンジン部分で実態はHTTPサーバーなので、リクエストを送信すればテキスト音声合成がこれ単体で出来るそうです
GUIを持たないHTTPサーバならwineでの起動も敷居が低いのでdocker内で起動してみました
$ docker run -it --rm --name engine -v /home/dev/Downloads/VOICEVOX:/VOICEVOX ubuntu:20.04 bash
# apt update && DEBIAN_FRONTEND=noninteractive apt install -y wine
# cd /VOICEVOX
# wine run.exe --host 00.0.0.0 --port 80
〜略〜
INFO: Uvicorn running on http://0.0.0.0:80 (Press CTRL+C to quit)
Googleドライブからzip落として解凍したディレクトリをマウントしてます
i386のアーキテクチャ追加しろとかwineに言われますが動くので無視して良いです
この状態で
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" engine
172.17.0.4
で表示されるIPに対してブラウザからアクセスします
http://<コンテナのIP>/docs
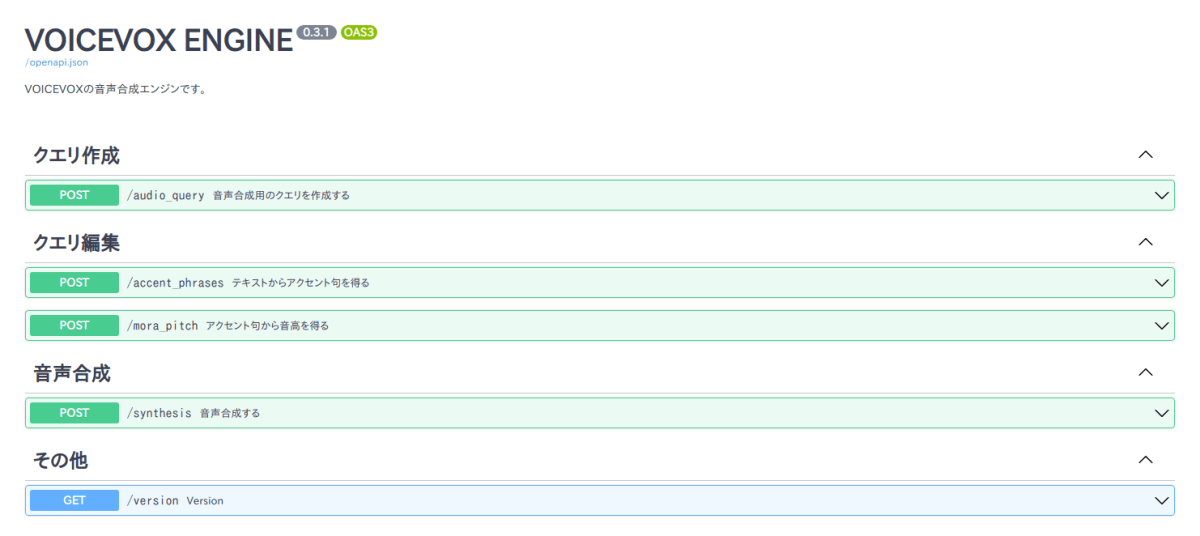
するとこんな画面が出れば動いてます
この画面でクエリ編集でjsonデータ作って音声合成のところのBODY部分にコピペしたら音声出せるのですが折角なのでgitに書いてあるcurlコマンドを参考にやってみたいと思います
まずは音声合成するための文章をURLエンコードします
$ text=$(echo これはテスト音声です | nkf -WwMQ | sed 's/=$//g' | tr = % | tr -d '\n')
エンコードしたものをサーバに投げつけて音声合成に使うためのJSONに変換してます
body="$(curl -X 'POST' -d '' -H 'accept: application/json' "http://172.17.0.4/audio_query?text=$text&speaker=1")"
取得したJSONをサーバに投げつけて音声合成の結果を再生します
$ play <(curl -s -X 'POST' 'http://172.17.0.4/synthesis?speaker=1' -H 'accept: audio/wav' -H 'Content-Type: application/json' -d "$body")
play WARN alsa: can't encode 0-bit Unknown or not applicable
/dev/fd/63:
File Size: 0 Bit Rate: 0
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 24000Hz
Replaygain: off
Duration: 00:00:02.09
In:100% 00:00:02.09 [00:00:00.00] Out:50.2k [ | ] Clip:0
Done.
普通に再生されました
面倒なので関数化
$ function vv {
text=$(echo "$1" | nkf -WwMQ | sed 's/=$//g' | tr = % | tr -d '\n')
body="$(curl -s -X 'POST' -d '' -H 'accept: application/json' "http://172.17.0.4/audio_query?text=$text&speaker=${2:-0}")"
play <(curl -s -X 'POST' "http://172.17.0.4/synthesis?speaker=${2:-0}" -H 'accept: audio/wav' -H 'Content-Type: application/json' -d "$body")
}
実行
$ vv 'オッス!!オラ悟空,いっちょやってみっか'
play WARN alsa: can't encode 0-bit Unknown or not applicable
/dev/fd/63:
File Size: 0 Bit Rate: 0
Encoding: Signed PCM
Channels: 1 @ 16-bit
Samplerate: 24000Hz
Replaygain: off
Duration: 00:00:04.17
In:100% 00:00:04.17 [00:00:00.00] Out:100k [ | ] Clip:0
Done.
OK
speakerのパラメータが1か0かで話者が変わるみたいだから第二引数に0,1指定出来るようにした
初期値0にしといたから違う話者にしたければ1を指定するだけでいいね
これならCLIオンリーのサーバでも喋らせられそう
とはいえイントネーションやら抑揚やら弄るのは厳しいからフロントエンドをnpmで起動してみる
.envにバックエンドの通信先書かれてるのでここをdockerで起動してるところに書き換えて起動
$ git clone https://github.com/Hiroshiba/voicevox
$ cd voicevox
$ sed -e 's/127.0.0.1:50021/172.17.0.4:80/g' .env.production > .env
$ npm ci
$ npm run electron:serve
ローカルのnpm古いってエラーになったので更新掛けた
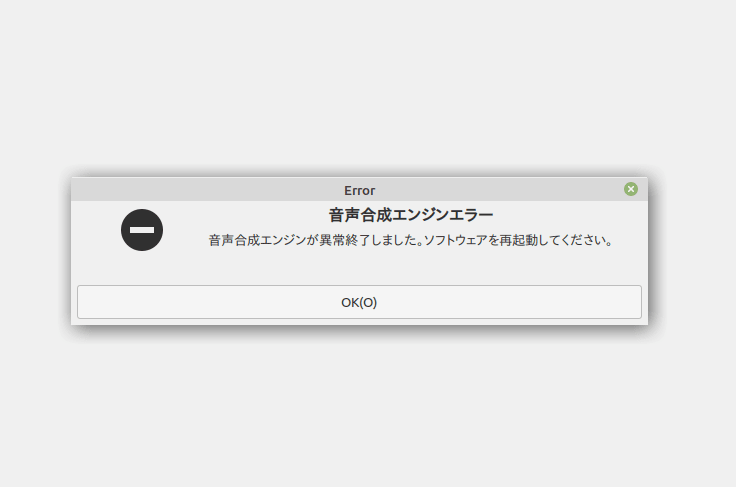
こんなエラーでますがフロントエンドからエンジン起動失敗したと勘違いされてるだけで実際にはdocker上で動いてるのでOK押せば
普通に起動するよ
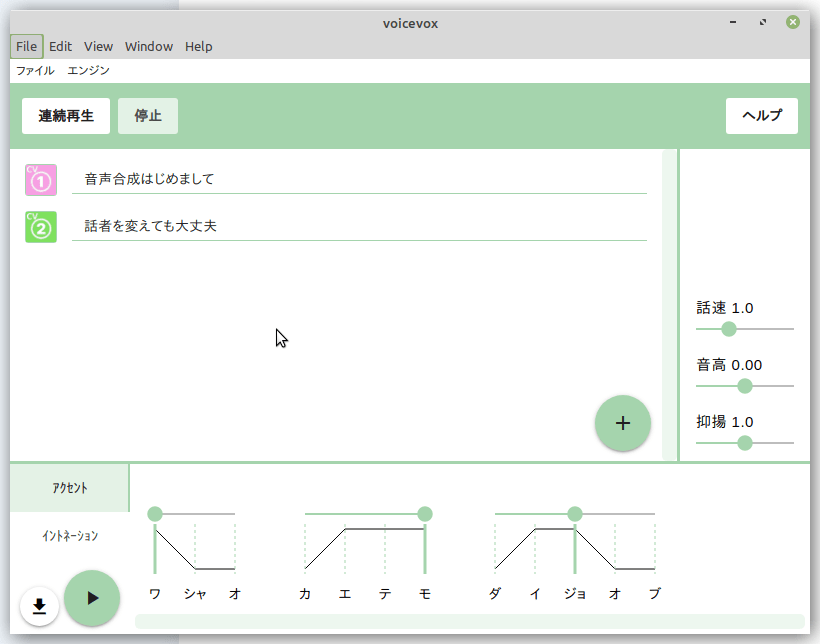
ちゃんと喋ってくれる
というわけで一応Linux上でも動作を確認できました
それではよいLinuxライフをー
とっぴんぱらりのぷう
P.S.
触ってみて思ったけどやっぱりwineで起動するのがコア部分の音声合成エンジンなのがネックだよね
常時起動のサーバとかで警告とかをこれで読み上げたら色々気づきやすいかなとか思ったけどこれ動かすためだけにwine使うのは微妙だと思うからネイティブに各環境で動くようになると嬉しいな
あとフロントエンドがバックエンドを起動する仕組みだと依存しすぎてる気がする
もう一段上にフロントエンドとバックエンドをコントロールする仕組みを作って欲しいな
現行のはどっちも単独起動出来る作りにしといたほうが実行場所を別々のリソースにするのも簡単に出来て便利だと思う
とはいえ無償でこれだけのものを提供してくれるのだから凄いなぁ
Discussion