【ollama / Phi-3】ニュースで話題のLLMをローカルPC上で動かしてみる
この記事では、ローカルLLMの実行ツール「ollama」を活用して、Microsoftが開発した軽量言語モデル「Phi-3」をMac上で実行する手順を紹介します。

実行例
はじめに
2024年4月、スマートフォン単体でも実行できる軽量な言語モデルの「Phi-3」がMicrosoft社より発表されました。
このほかにも、Meta社の「Llama3」など、ローカル環境でも実行可能なLLMの選択肢が増えてきています。
そこで今回は、これらのLLMがどのような性能を発揮するのか、手元のMacBook Airで試してみることにしました。
この記事では、ローカルLLMの基礎知識や、実行までの手順を簡潔にまとめます。
(あくまで体感での性能確認にとどめており、定量的なベンチマークなどは行なっていません。)
環境
今回、ローカルLLMを実行した環境は以下のとおりです。おそらく、現在MacBookをお使いの方は、これと同等以上のスペックをお持ちかと思います。
実行環境
- PC:MacBook Air (M1, 2020)
- OS:Sonoma 14.4.1
- チップ:Apple M1
- メモリ:8 GB
LLM
- LLM実行ツール:ollama 0.1.32
- LLM:Phi-3 (3.8B), Llama3 (8B)
ローカルLLMの知識
ローカルPC上でLLMを実行する「ローカルLLM」では、オンラインでLLMを実行できるChatGPTなどとは異なる、独特の用語やツールが登場します。
今回の実行にあたって調べた内容を簡単にまとめておきます。(ローカルLLMについては初心者なので、もし間違っている内容があればご指摘ください🙏)
| 用語 | 詳細 |
|---|---|
| LLM | 大規模言語モデル(LLM:Large language Models)のこと。具体的なモデル名として、OpenAI社のGPT-4や、Anthropic社のClaude3などがある。 |
| Llama | Meta社が公開したオープンソースのLLM。このため、日本語で追加学習させたり、ローカルPC上で実行させたりできる。2024年4月に最新版のLlama3が発表された |
| Phi-3 | Microsoft社が2024年4月に発表した小規模言語モデル(SLM)。スマートフォン単体でも実行が可能なほど軽量。 |
| パラメーター数 | LLMを構成するニューラルネットワークの状態を表す数値。数値が高いほど高度のデータ処理が可能となるが、モデルの容量も大きくなる。ローカルLLMではパラメーター数の小さなモデルを利用する。 |
| 量子化 | LLMのパラメーターを少ないビット数で表現することで、モデルのデータ量を少なくすること。パラメーター数が小さなモデルをさらに量子化することで、モデルのサイズがローカルPCで実行可能な容量(2~5GB程度)になる。 |
| Hugging Face | AIや機械学習に特化したGitHub的なサービス。LLMの実体はここからDLして利用することが多い。(今回の方法の場合、利用は必須ではない) |
| llama.cpp | LlamaをPC上で実行するための実行環境。実行のためにはソースをDLしてビルドする必要があり、手順がやや面倒。Llama以外のモデルも実行可能 |
| ollama | これもローカルLLMの実行環境。バックエンドでllama.cppを利用している。インストールや実行が簡単なので、今回はこちらを利用。 |
ここでは、目的や性能の異なるモデルが各社から発表されており、そのモデルの中でもパラメーター数や量子化手法によるバリエーションがあることを覚えておくと良いと思います。
今回は、ollamaをローカルPCにインストールして、Llama3やPhi-3などのモデルを実行することになります。
ollamaをインストールする
ここからは、ollamaを用いてローカルLLMを実行する手順をまとめます。
ollamaは以下の公式ページからダウンロードできます。
利用中のOSを選択してダウンロードします。

ダウンロード画面
macOSの場合、インストールしたアプリを「アプリケーション」フォルダに移動してから起動し、画面の指示にしたがって「ollama」コマンドを実行可能にしてください。
ターミナルを開き、以下のようにollamaのバージョンが確認できたら準備完了です。
$ ollama --version
ollama version is 0.1.32
なお、Homebrewを利用している場合は、以下のコマンドでインストールすることも可能です。
$ brew install ollama
ollamaでローカルLLMを実行する
次に、モデルをダウンロードしてチャット画面を起動します。以下のコマンドを実行すれば、すべて自動で行なってくれます。ここではモデルにPhi-3を指定しています。
$ ollama run phi3
初回のみ、モデルのダウンロードが行われます。数分程度で完了し、チャット入力を受け付ける画面に切り替わります。
「Hello!」と入力すると応答が表示されました。
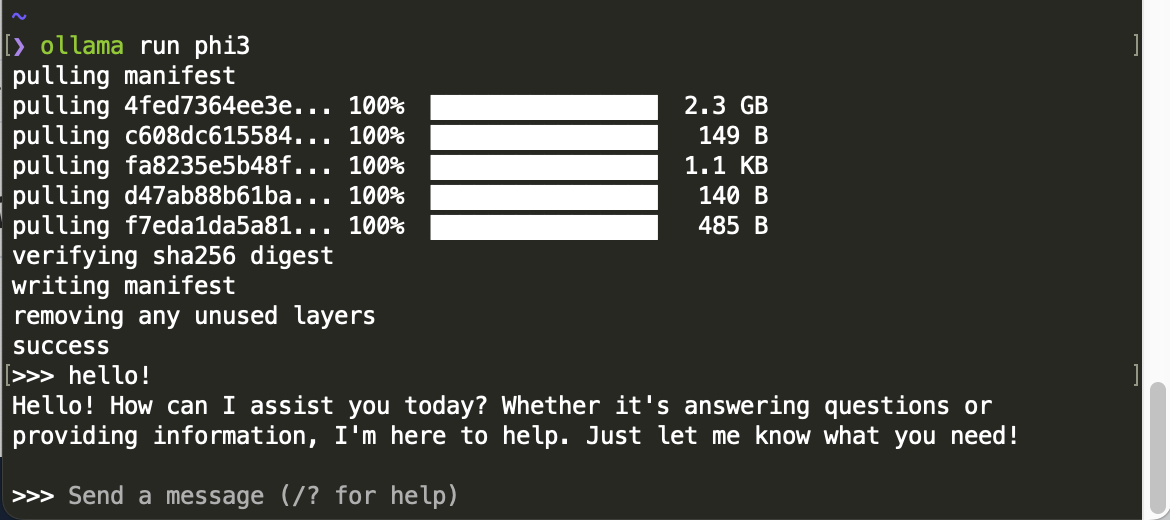
モデルをダウンロードして実行した様子
ちなみに、Phi-3のサイズはたったの2.3GBです。この中に人類の叡智が保存されていると思うとロマンがありますね。
ダウンロード可能なモデルの一覧
デフォルトでダウンロード可能なモデルは、以下のページにまとめられています。
比較用に、ollama run llama3でLlama3の8Bモデルをダウンロードしておきます。
モデルの削除方法
モデルをダウンロードしすぎるとPCのストレージを圧迫する可能性があるので、モデルの削除方法もメモしておきます。
以下のように、listオプションでダウンロードしたモデルを確認し、rmオプションで削除します。
$ ollama list
NAME ID SIZE MODIFIED
llama3:latest a6990ed6be41 4.7 GB 4 days ago
phi3:latest a2c89ceaed85 2.3 GB 7 minutes ago
$ ollama rm phi3
deleted 'phi3'
GUIでチャットできるようにする
ここまで紹介した方法で、ターミナル上でチャットを行うことができます。しかしChatGPTのようなGUIでチャットできた方が検証しやすいです。
ollamaと他のGUIツールを組み合わせることで、GUIを簡単に用意できます。
今回は、もっともシンプルに利用できる「ollama-ui」を利用しました。
上記のページからソースをダウンロードして実行するか、Chromeの拡張機能をインストールしてください。拡張機能の方がお手軽に実行できるのでオススメです。
拡張機能を起動すると、以下のようなチャットUIからLLMを実行できます。(事前にollamaを起動しておく必要があります)

ollama-uiを実行した様子
試しに、プログラムを書かせるタスクをPhi-3に依頼したところ、実用的なスピードで出力されました。内容もとくに問題なさそうです。
動作の様子は以下のポストを参照してください。
モデルの実用性を検証する
Phi-3とLlama3でいくつかのプロンプトを試してみた結果をメモしておきます。
Llama3の実行
Llama3を実行した場合、1回の回答を生成するために数分程度の時間がかかってしまいました。また、PCの画面描画もカクツキ始めました。
Llama3も高速な動作をウリにしているようですが、CPU性能やメモリ容量などの影響により、さすがに自分の環境では実行が難しかったようです。
このことからも、Phi-3の軽量さを実感できました。
日本語での応答
Phi-3で日本語での応答ができるか試してみました。

日本語のプロンプトを入力した様子
上記のように、日本語のプロンプトを理解して回答することは一応可能なようです。しかし、ところどころ日本語がおかしかったり、途中で英語に切り替わったりしてしまいました。
現状のモデルを日本語で実用することは難しそうです。ただ、そう遠くないうちに日本語対応のバージョンも公開されると思います。
おわりに
今回は、ollamaを用いてローカルLLMの実行を試してみました。思った以上に簡単な手順で実行でき、また実行速度や精度も実用的なことに驚きました。
最近では生成AI搭載のスマホも発表され始めており、今後もLLMをローカルで実行する機会は今後も増えていきそうです。
Phi-3を試してみて、文章の要約やプログラムの生成など、シンプルなタスクなら軽量なモデルをローカルで実行すれば十分な精度を得られると感じました。
今後は、シンプルなタスクはローカルで実行し、より複雑な思考を必要とするタスクは高精度なLLMを利用するといった、ハイブリッドな使い方に移行していくのではないでしょうか。
参考資料
Discussion