Beautiful Soupで店舗情報を取得してGoogleマップに表示する
ブランドサイト等に掲載されている「取扱店舗」の情報をWEBスクレイピングで取得して、Googleマイマップで可視化したお話です。
はじめに
ネット通販の普及により、何かお決まりのモノが必要なときは通販で購入することが多くなってきました。しかし、商品の実物を見たい時や、商品をネットで販売していない場合もありますよね。そんな時はメーカーのWEBサイトから「取扱店舗」とか「販売特約店」の一覧を探したりします。
ただ、店舗の位置が地図上にマッピングされていると便利なのですが、店名や住所の情報がずらっと並んでいるだけのことも多いですよね。この場合は住所を見て自宅近くのお店を探す必要があるので、けっこう面倒です。
そこで今回は、ブランドサイト等に掲載されている「取扱店舗」の情報をWEBスクレイピングツールのBeautiful Soupで取得してみました。その情報をGoogleマイマップに表示することで、近所の店舗を見つけやすくします。
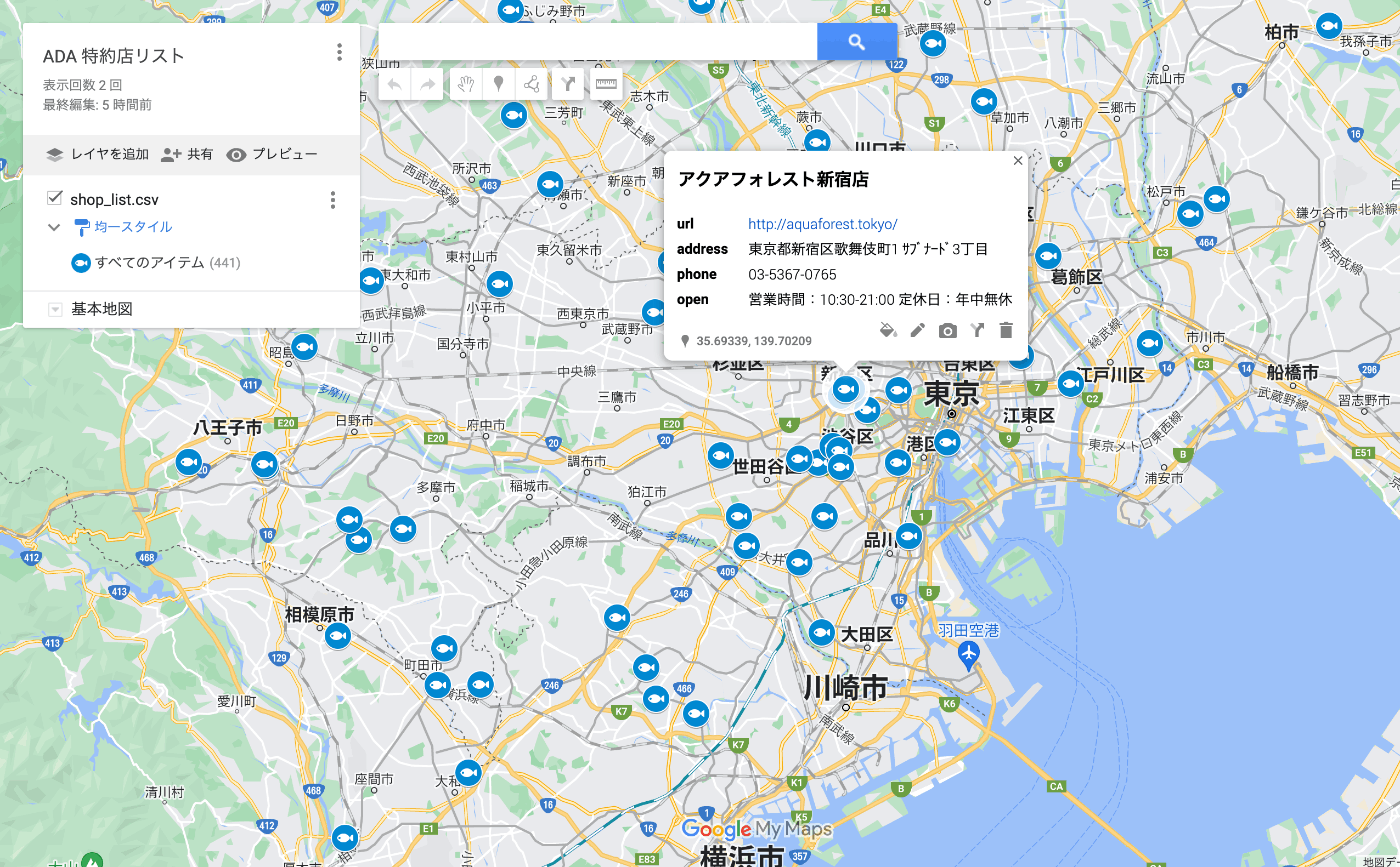
完成イメージ
今回はWEBスクレイピングをはじめて実施しました。この記事では、学習記録として実装の手順を紹介します。
作成したソースコードは以下のリポジトリで公開しています。
店舗情報を取得する
まずはGoogleマイマップで可視化するための店舗情報を取得します。
今回はアクアリウム用品ブランドの「ADA」の販売特約店の情報を取得してみました。ADAの商品はネット販売していないので実店舗に行く必要があります。しかしWEBページの特約店情報には地図表示の機能がないため、今回のようなケースにはピッタリです。
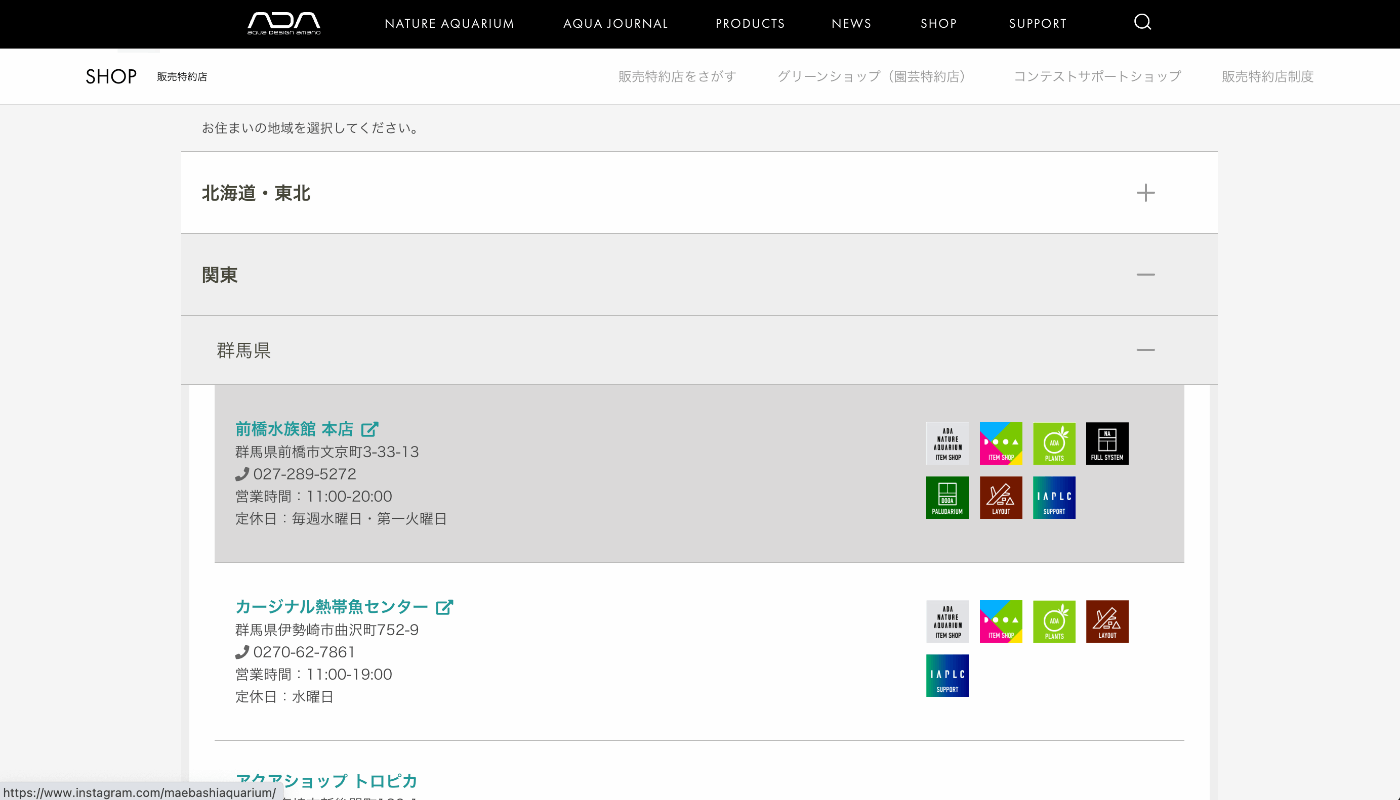
特約店情報のページ
環境
今回は以下のライブラリを利用しました。お好みの方法でインストールしてください。Pythonは3.11を利用しています。Jupyter Notebookは必須じゃないですが、取得したデータを整形する際に試行錯誤しやすくなるので利用しました。
beautifulsoup4 = "^4.11.1"
requests = "^2.28.2"
notebook = "^6.5.2"
lxml = "^4.9.2"
.ipynbのファイルを作成して、以下のようにインポートしておきます。
import csv
import requests
from bs4 import BeautifulSoup
データの取得
まずはrequestsを利用してWebページ上のデータを取得します。今回はADAの販売特約店のページにアクセスし、店舗情報を取得します。文字コードをうまく取得できずに文字化けしたので、apparent_encodingで文字コードを設定しています。(参考ページ)
PAGE_URL = "https://www.adana.co.jp/jp/contents/retailer/shop.html"
r = requests.get(PAGE_URL)
r.encoding = r.apparent_encoding # エンコーディングをUTF-8に設定
soup = BeautifulSoup(r.text, "lxml")
soup.title
なお、Beautiful Soupの公式ドキュメントでは、パーサーとしてlxmlの利用が推奨されているため、BeautifulSoup(r.text, "lxml")としてlxmlを指定しました。
実行すると、以下のようにタイトル部分を取得できます。
<title>販売特約店をさがす | ADA - SHOP</title>
次に、店舗の詳細情報にアクセスします。ページのソースコードを解析すると、basic-trまたはbasic-tr-linkクラスの<a>タグの中に店舗情報が記載されていることがわかります。
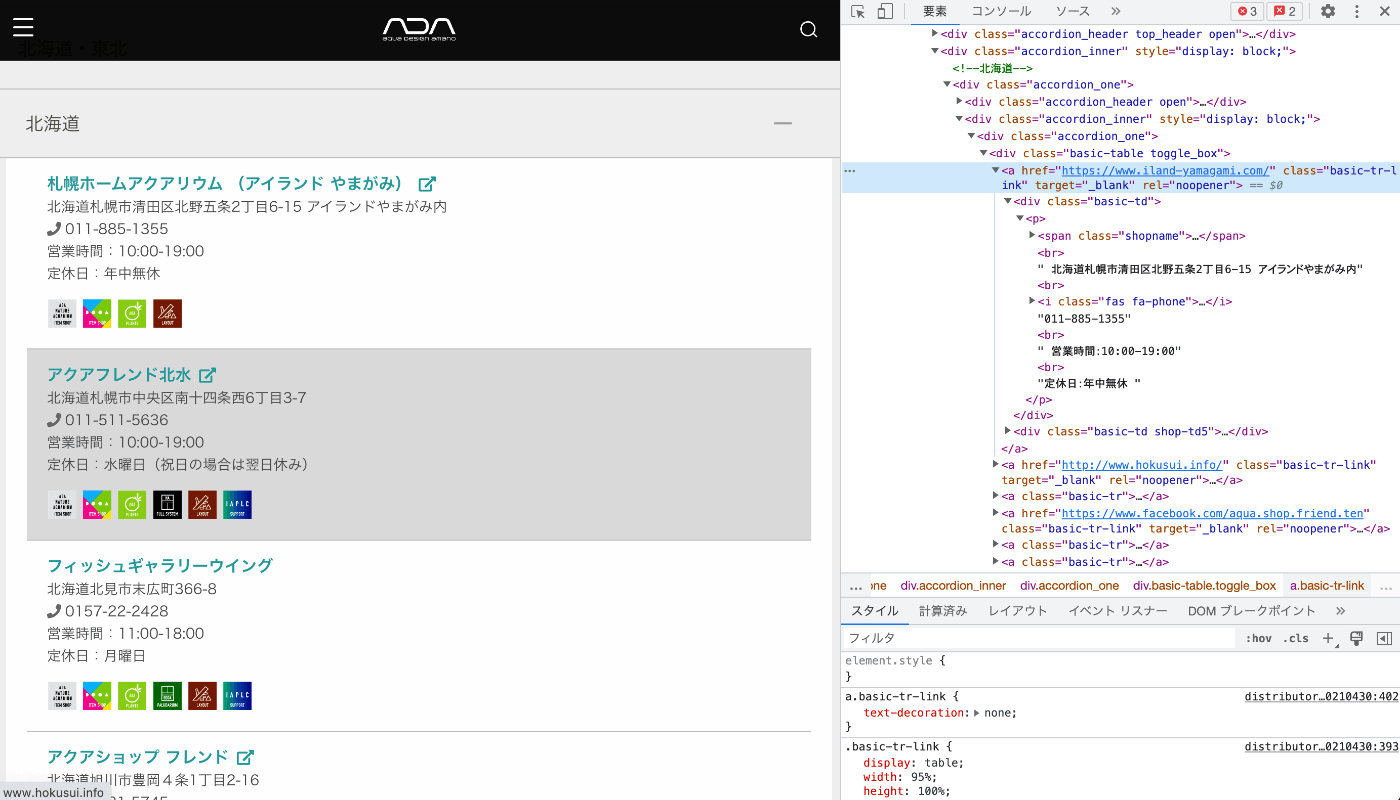
HTMLソース
そこで、find_all()メソッドにタグとクラスを指定して、データにアクセスします。
# 1番目の店舗情報を取得
soup.find_all("a", class_=["basic-tr", "basic-tr-link"])[0]
実行すると、以下のように個別の店舗情報にアクセスできます。店舗の詳細は<p>タグの中に列挙されています。(ダミー情報に書き換えています。)
<a
class="basic-tr-link"
href="https://www.sample.com/"
rel="noopener"
target="_blank"
>
<div class="basic-td">
<p>
<span class="shopname"
>店舗名<i class="fas fa-external-link-alt"></i></span
><br />
住所<br />
<i class="fas fa-phone"></i>111-2222-3333<br />
営業時間:10:00-19:00<br />定休日:年中無休
</p>
</div>
<!-- 省略 -->
</a>
データの整形
CSVファイルに出力できるように、取得した店舗情報のデータを整形します。
<a>タグの中身を分解して、店舗ごとの詳細情報を保存した辞書を作り、リストに追加します。
shop_list = []
for row in soup.find_all("a", class_=["basic-tr", "basic-tr-link"]):
shop_info = {}
shop_detail = row.div.p.get_text(',', strip=True).split(',')
shop_info["name"] = shop_detail[0]
shop_info["url"] = row.get("href")
shop_info["address"] = shop_detail[1]
shop_info["phone"] = shop_detail[2]
shop_info["open"] = " ".join(shop_detail[3:])
shop_list.append(shop_info)
shop_list[0]
データの加工処理について少し補足します。まず、get_text()メソッドで<p>タグのコンテンツのテキスト部分を,区切りで取得します。テキストには空白や改行が含まれていますが、strip=Trueオプションを指定することで除去できます。
このテキストに対して、split(',')を適用し、店舗の詳細情報を配列で取得しています。情報がテキストでベタ書きされている時に、汎用的に使えそうなテクニックですね。
shop_detail = row.div.p.get_text(",", strip=True).split(",")
# こういう配列ができる ["店舗名", "住所", "電話番号", "営業時間", ...]
<a>タグのhref=要素のURLは、get()メソッドで取得できます。
shop_info["url"] = row.get("href")
データの末尾には営業時間などの情報が記載されています。これは店舗ごとに行数が異なるため、join()で結合しました。
shop_info["open"] = " ".join(shop_detail[3:])
実行すると、以下のような辞書に店舗の詳細情報を保存できます。
{'name': '店舗名',
'url': 'https://www.sample.com/',
'address': '住所',
'phone': '111-2222-4444',
'open': '営業時間:10:00-19:00 定休日:年中無休'}
CSV出力
最後に、DictWriterを利用して、店舗情報のリストをCSVに出力します。
with open("shop_list.csv", "w") as f:
writer = csv.DictWriter(f, fieldnames = shop_list[0].keys())
writer.writeheader()
writer.writerows(shop_list)
店舗情報を一覧化したCSVを作成できました!
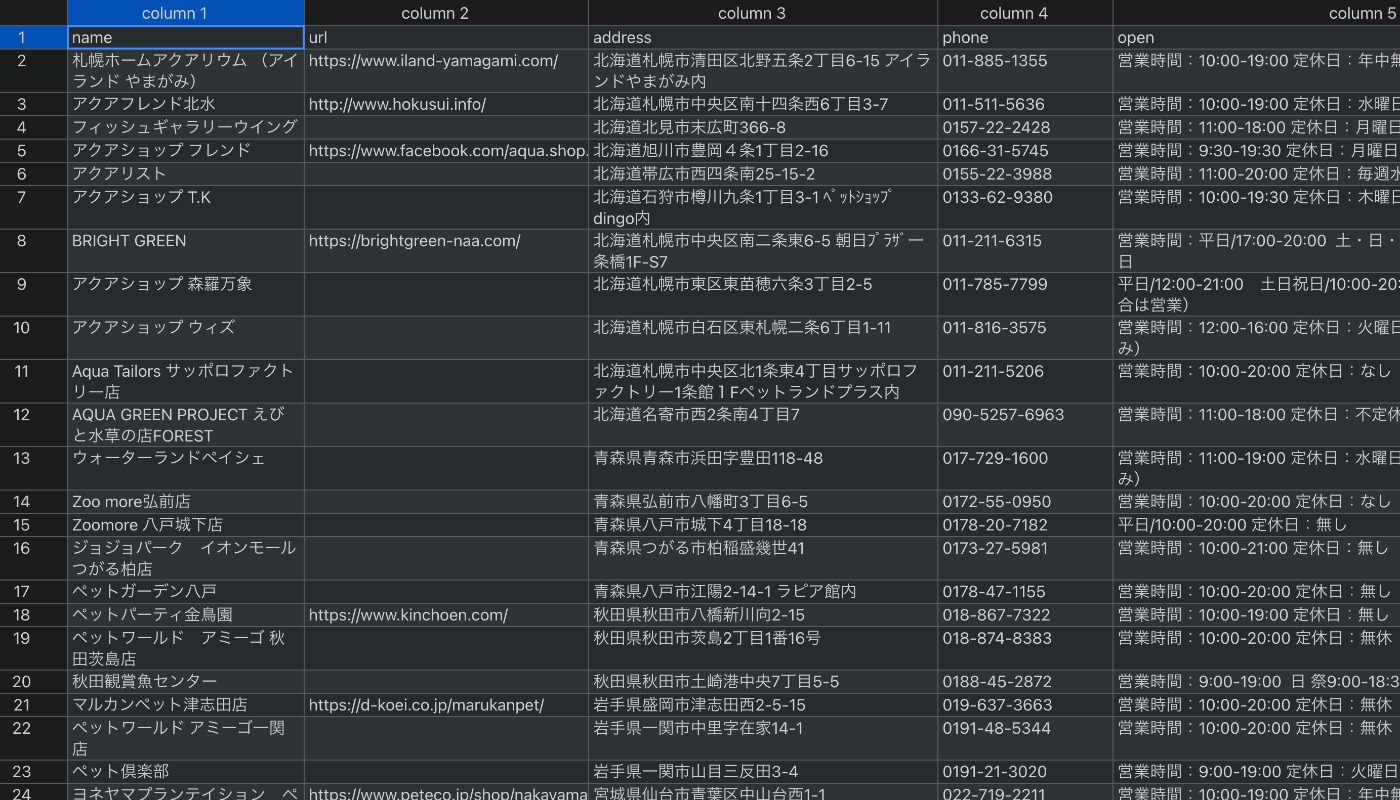
作成したCSVデータ
Googleマップに表示する
作成したCSVファイルのデータをGoogleマップに表示します。GoogleマイマップにCSVをアップロードするだけです。(操作方法に関する詳細な説明は省略します。)
addressの列を住所に指定すると、ジオコーディングして地図上に表示してくれます。
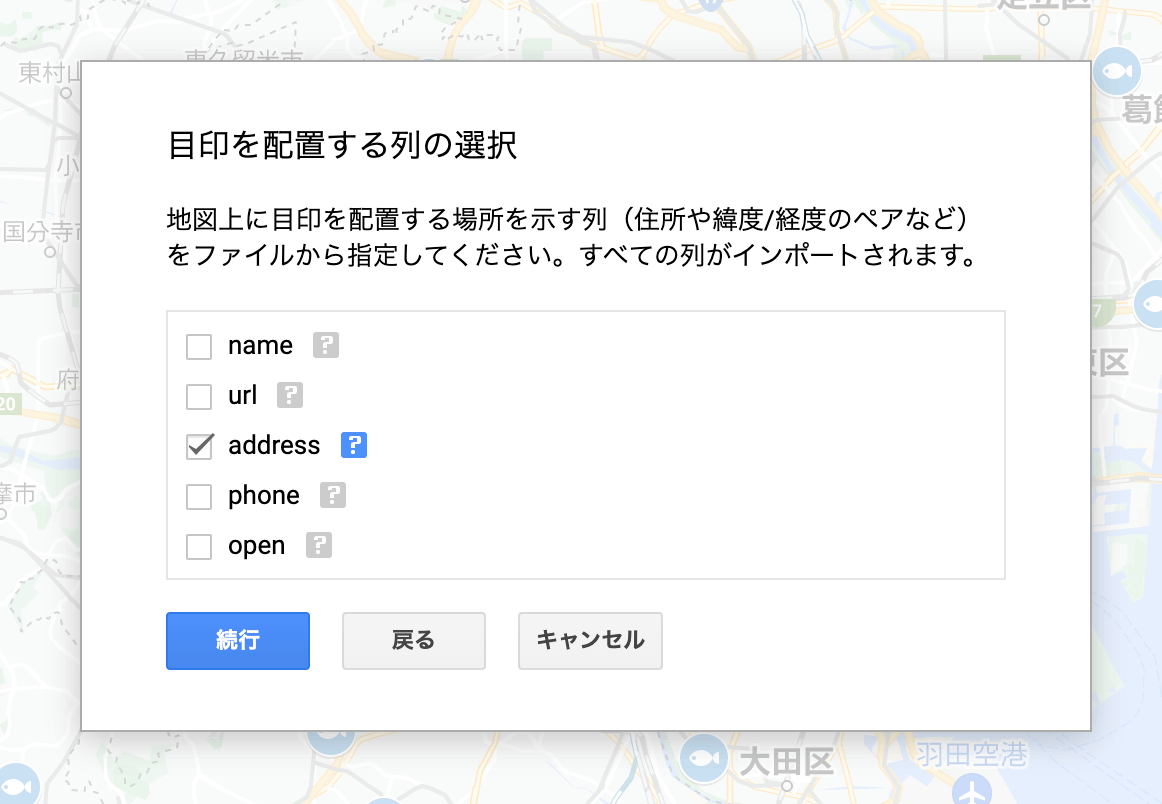
住所の指定ダイアログ
これで、地図上に店舗情報の一覧を表示することができました🎉
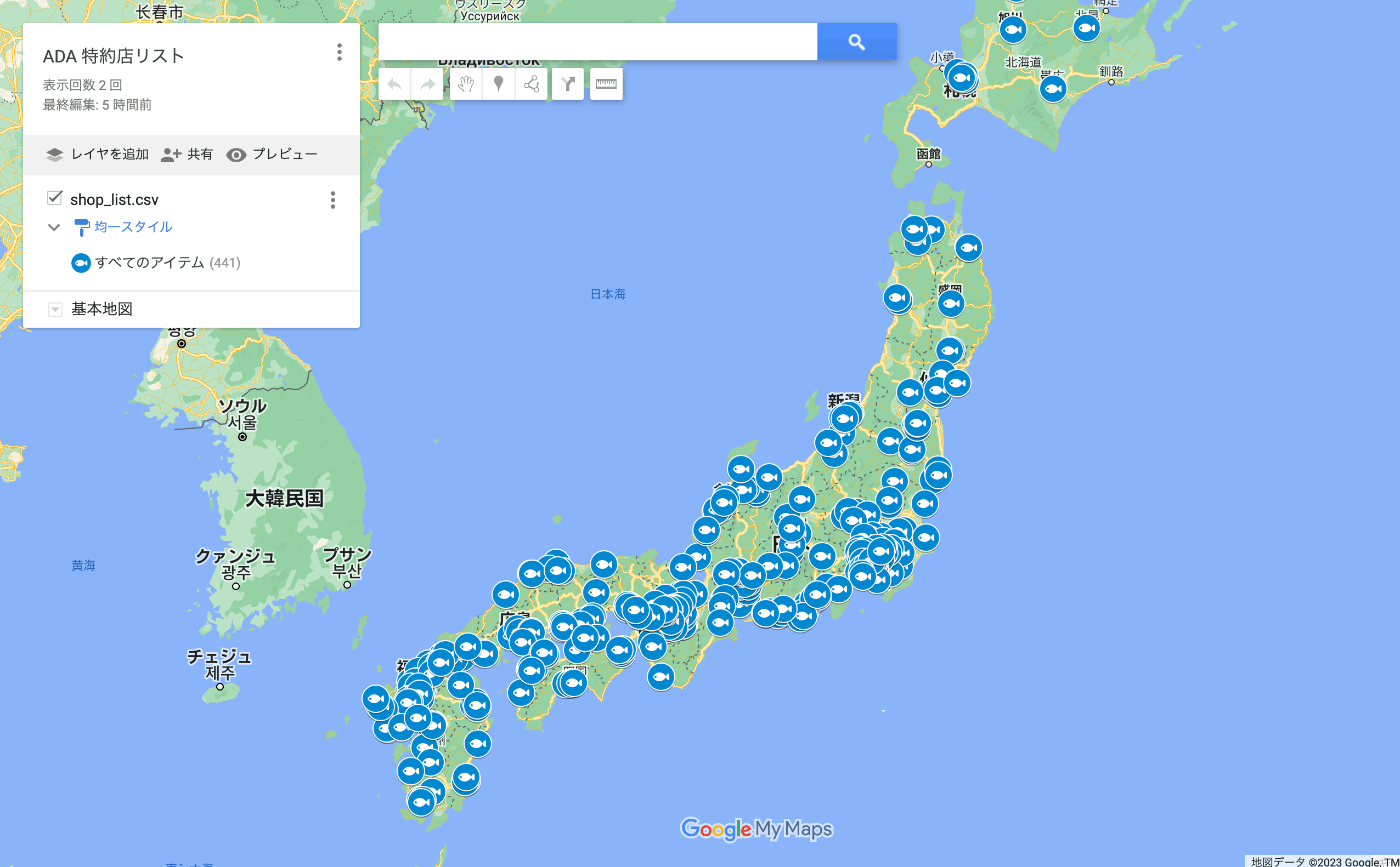
作成した地図
おわりに
今回はWEBスクレイピングをはじめて実施してみましたが、意外と簡単に目当ての情報を取得することができました。これを応用して、他のサイトの店舗情報も同じように取得できそうです。
参考文献
Discussion