Scala3 の Capture Checking / Separation Checking 入門
Scala - Qiita Advent Calendar 2025 - Qiita
大規模なソフトウェアを書くときに厄介なものの一つに、可変なデータの取り扱いが挙げられるでしょう。例えば、意図しない箇所でいつの間にかデータが書き換わっていたり、使うべきではないタイミングでリソースを使ってしまうことなど。
Rustのような言語は所有権(やライフタイム)によりこれらの課題を解決します。が、これをScalaのようなGCを前提とした言語に良い感じ(既存のプログラムに大きな影響を与えずに)に取り込むにはどうすればよいでしょうか? つまり、リソースへのアクセス権限(capability)(Object-capability modelではオブジェクト)のトラッキングはしたいけど、メモリ管理はGCに任せたい。
Scala3 のアンサーが Capture Checking + Separation Checking と呼ばれる実験的機能だという理解でいます。
Capture Checking
Capture って何?
Capture Checking とはどういう機能かという話をするのですが、そもそも Capture とは何なんですかね?
これは Closure の Capture (日本語だと「捕捉」?)のことで、例えば以下のプログラムでは increment というクロージャの内部で、クロージャの外で定義された c を参照しています。このとき、クロージャ increment は c を capture しているということになる。
class Counter:
def inc: Counter = ???
@main def main():
val c = new Counter
val increment = () => {
c.inc()
}
increment()
Capturing Type
Capture Checking では、この変数のcaptureを型レベルでトラッキングできるようにする機能で、そのために "Capturing Types" という型が導入されます。
T^{x_1, ..., x_n}
-
T: Shape Type。この型の値が、次のCapture Setに含まれる値をキャプチャしているということになる -
{x_1, ... x_n}: この型の値がキャプチャできる値の集合
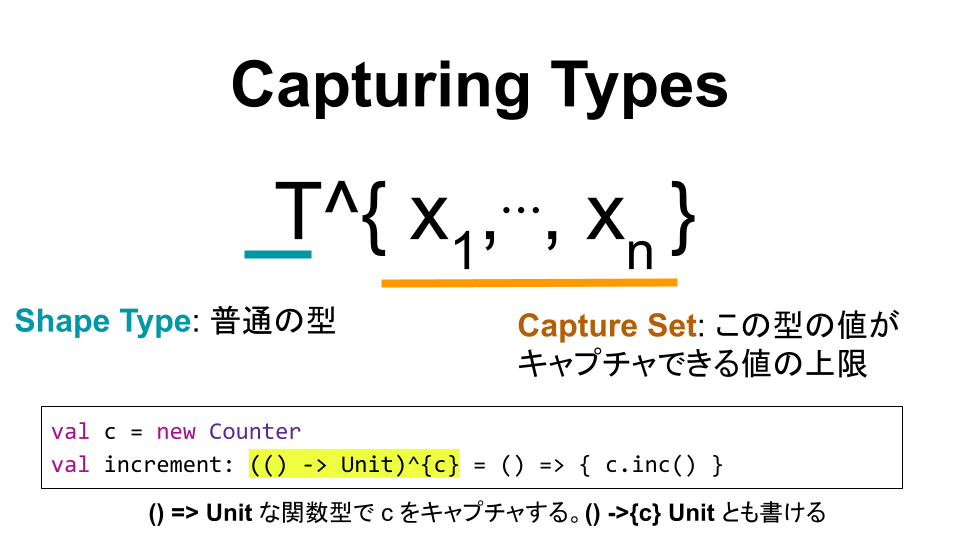
例えば先の例では、increment は以下のような capturing type をもつことになる。[1]
//> using scala 3.8.0-RC3
import language.experimental.captureChecking
val c: Counter^ = new Counter
val increment: (() -> Unit)^{c} = () => {
c.inc()
}
ここでおもむろに Counter^ という記法が出てきましたが、これはざっくり c: Counter^ は capture checking によってトラッキングされる値ですよということくらいに考えてください。[2]
Capture Checking
それでは、Capture Checking は何をチェックするのでしょうか? 例えば以下のようなプログラムはエラーになります。
なぜなら increment がキャプチャ可能な値の集合は ^{c1} のみなのですが、そこで指定されていない c2 がキャプチャされてしまっているからです。[3]
//> using scala 3.8.0-RC3
import language.experimental.captureChecking
val c1: Counter^ = new Counter
val c2: Counter^ = new Counter
val increment: (() -> Unit)^{c1} = () => {
c1.inc()
c2.inc() // (c2: Counter^) cannot be referenced here
}
つまり、incrementが操作できるのはc1のみという制約を型で表現することができるようになりました。
こうしてみると、Capture Set(^{c1}の部分)は、その値(クロージャ)がアクセス可能なcapabilitiesという捉え方ができそうですね。
例: 参照透過なクロージャ
ここで一つ簡単な利用例として、参照透過なmapの実装をやってみます。mapが受け取った関数がなにか破壊的な変更を加えてたりしないってことを確認したいですよね!?
enum MyList[+A]:
// A->{}B は (A->B)^{} の省略形。何もキャプチャしない関数型
def map(f: A ->{} B): MyList[B] = ???
var foo: Integer^ = 0 // 現状Int^は出来ないけどできると良さそう?
(ls: MyList[Int]).map { x =>
foo += x // foo は f: A->{}B の capture set に含まれないのでエラー
x
}
このようにmapに与えた関数が値にアクセスすることを防いでくれます。良かったですね。
他の例
他にもリファレンスにいくつかの活用例が載っているので見てみてね。僕はあまり活用例思い浮かばなかったけど、capture checkingによってトラッキングされる値をcapabilityとみなすことで、エフェクトトラッキングみたいなことができそうな気もするけどどんな感じになるんですかね???
Alias Tracking
ちなみにエイリアスがあるとcapture checkingが混乱しそうな感じがしますが、エイリアスも追跡される。
val c: Counter^ = new Counter
val a: Counter^{c} = c // a は c へのアクセスをもつことが型レベルで分かる
val increment: (() -> Unit)^{c} = () => {
a.inc()
}
Separation Checking
Capture Checking は Scala3 のコレクションライブラリにも導入されて完成が近づいてきている機能。一方、ここから解説する Separation Checking は Capture Checkingを拡張した開発途上の実験的機能。
Capture Checking ではある値にアクセスできるかどうかしか管理していませんでしたが、Separation Checking では SharedCapability (readonly)と、ExclusiveCapability (writable) を導入し、プログラムのどの部分がデータの変更をできるのかということをトラッキングできるようにします。これにより、並列処理におけるデータ競合などを回避しやすくしたり、readonlyとwritableなエフェクトを分けてトラッキングできて便利になりそう。
Mutable extends ExclusiveCapability
Separation Checking では、caps.Mutable が提供され、これを継承したクラスの中では update 修飾子を使ったメソッドを実装することができる。この update def で定義された関数は文字通りこのクラスの状態を更新する(実際はクラスの状態を更新しなくても外部リソースを更新するのでも良いのだが)ことを表し、これらのメソッドにはreadonlyな環境ではアクセスすることが出来ない。
//> using scala 3.8.0-RC3
import scala.language.experimental.captureChecking
import scala.language.experimental.separationChecking
class Ref(init: Int) extends caps.Mutable:
private var current = init
def get: Int = current
update def set(x: Int): Unit = {
current = x
}
これらに対するreadonlyなメソッドと、書き込み可能なメソッドは以下のように定義できる。
// Ref は Ref^{cap.rd} の省略形。
// すべての値のnon-updateメソッドにアクセスできるということを表すが
// 実質的に`r`本体のnon-updateメソッドにアクセスできるだけ
def read(r: Ref): Int =
r.get
// Ref^ は任意の capability (Refへの書き込みも含む) を持つ
def update(r: Ref^, value: Int): Unit =
r.set(value)
val r = Ref(0)
update(r, 4)
println(read(r)) // 4
ここで、read内でupdateメソッドを呼び出すことは出来ない。
def read(r: Ref^{cap.rd}): Int =
// ❌ Cannot call update method set of r since its capture set {r} is read-only
r.set(0)
r.get
Separation Check (分離チェック)
例えば2つの関数を並列に実行する par 関数を定義しましょう。このとき、2つの引数fとgのうち、片方があるリソースのupdateメソッドを呼び出している場合、別の引数はそれにアクセスすることはできません。
def par[A, B](f: () => A, g: () => B): (A, B) = ???
// ❌ Separation failure: argument of type () ->{r} Unit
// to method par: [A, B](f: () => A, g: () => B): (A, B)
// ...
par(() => r.set(2), () => r.set(3))
// ❌ これもだめ
par(() => r.get, () => r.set(3))
par(() => r.set(2), () => r.get)
// ✅ これはOK
par(() => r.get, () => r.get)
ちょっと強すぎる制約な感じがしますね。例えば順番に関数を実行する seq ではこんな制約要らないんですが...。実はこれはHideという仕組みによって実装されていて、gに適切にcapabilityを指定することで回避することができるのですが、そのためにまずはHideの仕組みについて簡単に説明する。
// ❌ Separation failure: argument of type () ->{r} Unit
def seq(f: () => Unit, g: () => Unit): Unit = f(); g()
seq(() => r.set(1), () => r.set(2))
Move Semantics みたいなやつ
Separation Checkingでは T^(T^{cap})は、誰とも共有されてない独立したcapability、という特別な型を表現する(単なるuniversal capabilityじゃないのか~)。
そしてある変数yをT^に代入するということは、yはxという排他的なcapabilityによって"Hide"(moveじゃん?)されたとし、xが生きている限り元のyにアクセスすることができない。(でないとxとyが同じcapabilityを共有することになる)
これにより、yを経由してxを操作してしまうという意図しない操作を防ぐことができる。
val y = Ref(0)
update(y, 4) // ok
locally {
val x: Ref^ = y // y は x によって hide される
// Separation failure: Illegal access to {y} which is hidden by the previous definition
// of value x with type Ref^.
update(y, 4) // ❌
}
// ちなみに
locally {
val x: Ref^{y} = y // 明示的にcapture setを書いた場合はhideは起きない
update(y, 4) // ✅ OK
}
ここで先ほどの par の定義を思い出してみると、par の引数もuniversal capability [5]をもつ型。
// () => A は (() -> A)^ の省略形
def par[A, B](f: () => A, g: () => B): (A, B) = ???
-
par(() => r.set(1), () => r.set(2))呼び出すと -
() => r.set(1)はfによってhideされる (推移的にこのクロージャがcaptureするrがfでhideされることになる) -
() => r.set(2)はrにアクセスしようとするが、fによってhideされているのでアクセスできない。
これは、以下のように明示的に、gがfの隠蔽する値にアクセスできることを許可することで回避することができる。
def seq(f: () => Unit, g: () ->{f} Unit): Unit = f(); g()
// ✅ OK
seq(() => r.set(1), () => r.set(2))
Consume Parameters
関数の返り値を通して Ref^ を返せば、hideをすり抜けられるのでは? 例えば以下のような inplace update をする関数を定義してみる。結論からいうとこれは禁止されているのですが。
def incr(a: Ref^): Ref^ =
a.set(a.get + 1)
a
val a = new Ref(1)
val b: Ref^ = incr(a) // bは実はaのaliasだが、現状のルールではhideされない
incr(a) // なので、aを更新することで、bの値を更新することができてしまう。
b.get // 3 !?
関数が新たなuniversal capabilityをもつ値を返す操作は、そのパラメータがもう利用されない場合に限り安全となる(関数の中でエイリアス作って返してるかもしれないですからね)。なので実は上の incr 定義はエラーとなる。
Separation failure: method incr's result type Ref^ hides parameter a.
The parameter needs to be annotated with consume to allow this.
コンパイルを通すためには以下のように引数に consume 修飾子をつけ、incrに与えた引数はhideされることを明示的に教えてやる必要がある(move semanticsだね?)。
def incr(consume a: Ref^): Ref^ =
a.set(a.get + 1)
a
val a = new Ref(1)
val b: Ref^ = incr(a) // aはincrによりconsume(bによりhide?)される
incr(a) // ❌
まとめ
Capture Checking も Separation Checking もまだまだ開発途上の機能ですが、基本的にはGCでメモリを気にせずに書きつつも部分的にはRustみたいな制約を一部取り入れたプログラムが書けるようになって便利&楽しくなるのではないでしょうか。
このブログは2025年11月27日に開催されたScalaわいわい勉強会 #6で発表した内容をブログに書き起こしたものです。
参考資料
-
Capture Checking - Bringing Effect Checking to the Masses
- Capture Checking のプロジェクトページ、ここから各種論文とかにアクセスできる
- Capture Checking | Scala 3 Reference
- Separation Checking | Scala 3 Reference
-
System Capybara: Capture Tracking for Ownership and Borrowing | ICFP/SPLASH'25
- Youtubeレコーディングのこの辺から https://www.youtube.com/live/D4uQiayHmv0?si=Hbfv_ZVvWGo3TcF-&t=4036
-
目ざといScalaプログラマは
() -> Unitじゃなくて() => Unitじゃないの? と思うかもしれません。実は->は capture checking 導入にあたって追加された記法。従来の関数型A => Bは任意の値をキャプチャ可能な関数を表し、新たに導入されたA -> Bはいかなる値もcaptureしない純粋な関数を表す。A ->{c,d} Bは(A -> B)^{c,d}の省略形。詳しくはFunction Types | Capture Checking。 ↩︎ -
ドキュメントでは
T^はT^{cap}の省略形で、任意の値(capability)をキャプチャ可能な型。capは universal capability と呼ぶとのこと。capture checkingによるトラッキングの対象になるにはcapture setが空でないcapturing typeでないといけないので、universal capabilityを持つcapturing typeを追跡対象であることをマークするために使っているが、本質的にはc: Counter^ = new Counterが任意のcapabilityをcaptureできるというのは直感的にはなんか意味不明な感じがする。(後述するsubtypingルールとかでは必要なんですけどね)。 ↩︎ -
subtyping関係はcapturing typeによって拡張される: より小さいcapturing setを持つ型はより小さなサブタイプとなる。例えば
T^{} <: T^{c1} <: T^{c1,c2} <: T^{cap}. つまり、() ->{c1,c2} Unitな値を、() ->{c1} Unit型に代入できないというふうに見ることもできる。 ↩︎ -
これがcapture checkingの例としてよく出されるけど、あまり自明じゃない例だと思う ↩︎
-
もう universal capability って言い方やめたほうがいいのでは??? ↩︎
Discussion