Closed3
DeepEvalを使ってみる
ドキュメントを参考にとりあえず動かしてみる
deepevalをインストール
poetry add deepeval --group test -C server
評価結果を可視化できるように Confident AI のアカウントを作成し、APIキーを取得する
Confident AIにログインする
poetry run -C server deepeval login --confident-api-key <API Key>
テストファイルを作成
server/tests/test_example.py
import pytest
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
def test_answer_relevancy():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output of your LLM application
actual_output="We offer a 30-day full refund at no extra cost.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra cost."]
)
assert_test(test_case, [answer_relevancy_metric])
以下の記載があるので、OPENAI_API_KEY 環境変数にOpenAIのAPIキーを設定しておく
You'll need to set your OPENAI_API_KEY as an enviornment variable before running the AnswerRelevancyMetric, since the AnswerRelevancyMetric is an LLM-evaluated metric.
実行
poetry run -C server deepeval test run server/tests/test_example.py
# ...略
✨ You're running DeepEval's latest Answer Relevancy Metric! (using gpt-4-0125-preview, strict=False, async_mode=True)... Done! (5.57s)
PASSEDRunning teardown with pytest sessionfinish...
============================================================================= slowest 10 durations =============================================================================
5.59s call tests/test_example.py::test_answer_relevancy
(2 durations < 0.005s hidden. Use -vv to show these durations.)
======================================================================== 1 passed, 3 warnings in 5.60s =========================================================================
Test Results
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Overall Success Rate ┃
┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ test_answer_relevancy │ │ │ │ 100.0% │
│ │ Answer Relevancy │ 1.0 (threshold=0.5, evaluation model=gpt-4-0125-preview, reason=The score is 1.00 because the │ PASSED │ │
│ │ │ response perfectly addressed the concern without including any irrelevant information. Great job │ │ │
│ │ │ on maintaining focus and relevancy!) │ │ │
└───────────────────────┴──────────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────┴────────┴──────────────────────┘
✅ Tests finished! View results on https://app.confident-ai.com/project/xxxxxxxxxxxxxxxxxxxxxxxxx/unit-tests/xxxxxxxxxxxxxxxxxxxxxxxxx/test-cases
自動でブラウザが起動し、以下のように実行結果をグラフィカルに確認することもできる
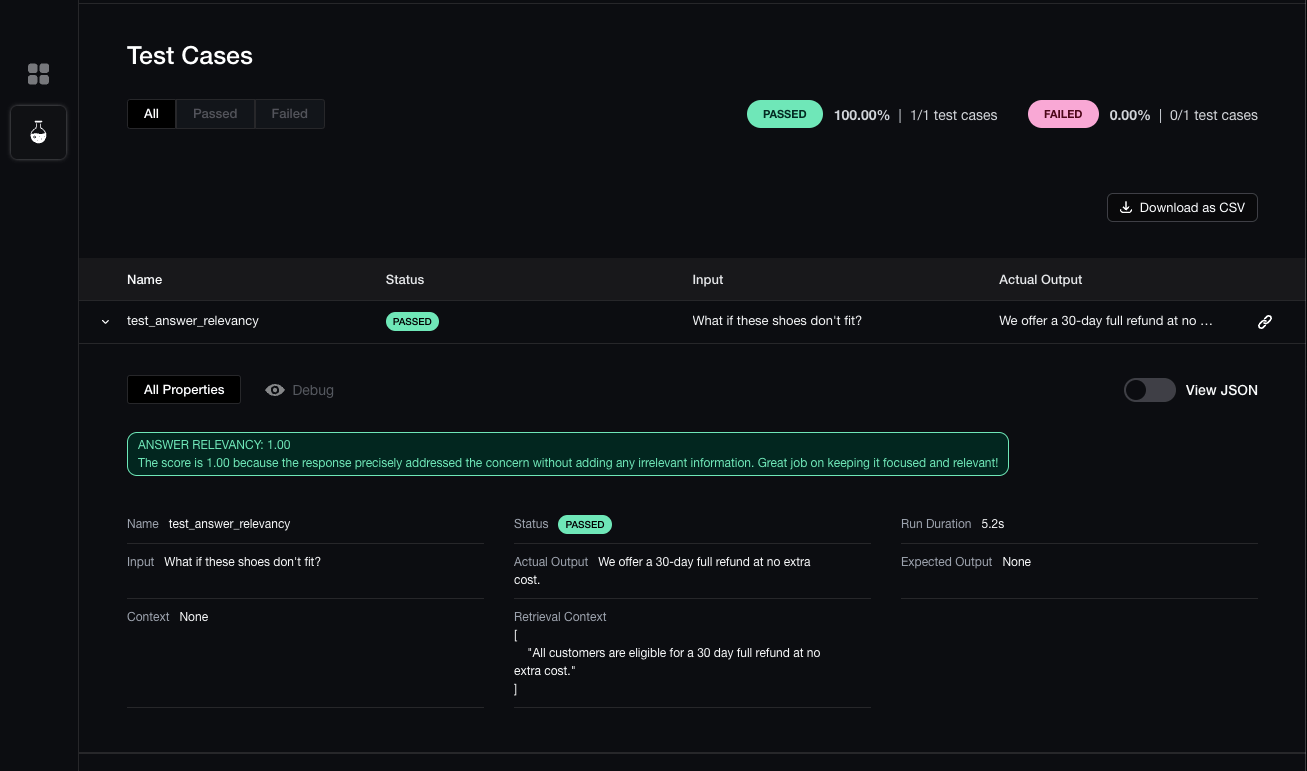
実際のLLM実行に対して評価を行ってみる
評価対象
server/libs/chatbot_with_memory.py
import pprint
import time
from typing import TypedDict
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models import BedrockChat
from langchain_core.messages import BaseMessage
from langchain_core.runnables.history import (
GetSessionHistoryCallable,
RunnableWithMessageHistory,
)
class InvokeResult(TypedDict):
answer: str
latency_in_sec: float
class ChatbotWithMemory:
chain_with_history: RunnableWithMessageHistory
def __init__(
self,
get_session_history: GetSessionHistoryCallable,
model_id: str = "anthropic.claude-v2:1",
) -> None:
chat = BedrockChat(
model_id=model_id,
region_name="us-east-1",
model_kwargs={
"temperature": 0,
},
verbose=True,
)
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
chain = prompt | chat
self.chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="question",
history_messages_key="history",
)
def invoke(self, conversation_id: str, question: str) -> InvokeResult:
config = {"configurable": {"session_id": conversation_id}}
start_time = time.time()
response: BaseMessage = self.chain_with_history.invoke(
{"question": question}, config=config
)
end_time = time.time()
elapsed_time_in_sec = end_time - start_time
print(f"Elapsed time: {elapsed_time_in_sec} seconds")
pprint.pprint(response)
return {"answer": response.content, "latency_in_sec": elapsed_time_in_sec}
テストコード
実DBに接続するとデータの準備や後片付けが手間なので、会話履歴はインメモリで保持するようにしている
server/tests/test_chatbot_with_memory_claude2.py
import deepeval
from deepeval import assert_test
from deepeval.metrics import LatencyMetric
from deepeval.test_case import LLMTestCase
from langchain.memory import ConversationBufferMemory
from libs.chatbot_with_memory import ChatbotWithMemory
model_id = "anthropic.claude-v2:1"
def test_latency():
latency_metric = LatencyMetric(max_latency=60)
chatbot = ChatbotWithMemory(
model_id=model_id,
get_session_history=lambda session_id: ConversationBufferMemory(
session_id=session_id, input_key="question", memory_key="history"
).chat_memory,
)
question = "おすすめのお肉料理の候補を3つ挙げてください"
response = chatbot.invoke(
conversation_id="dummy-conversation-id", question=question
)
test_case = LLMTestCase(
input=question,
actual_output=response["answer"],
latency=response["latency_in_sec"],
)
assert_test(test_case, [latency_metric])
@deepeval.log_hyperparameters(model=model_id, prompt_template="")
def hyperparameters():
return {}
実行結果
poetry run -C server deepeval test run server/tests/test_chatbot_with_memory_claude2.py
# ...中略
server/tests/test_chatbot_with_memory_claude2.py::test_latency Elapsed time: 13.157072067260742 seconds
AIMessage(content='はい、おすすめのお肉料理の候補を3つ挙げさせていただきます。\n\n1. ステーキ\n肉のうまみが存分に味わえる定番のお肉料理です。レア~ミディアムレアがおすすめです。\n\n2. ハンバーグ\n具だくさんのハンバーグは子供から大人まで人気のメニュー。卵とパン粉でとろとろの食感が楽しめます。\n\n3. 焼き鳥\n骨付きの鳥肉を炭火で焼いたジューシーな焼き鳥は、ビールとの相性も抜群です。塩・タレがおすすめ。\n\nいかがでしょうか。ご家族やご友人と楽しんでいただければ幸いです。他にもおすすめ料理があれば教えてください。')
✨ You're running DeepEval's latest Latency Metric! (using None, strict=False, async_mode=True)... Done! (0.00s)
PASSEDRunning teardown with pytest sessionfinish...
======================================================================== slowest 10 durations ========================================================================
13.27s call tests/test_chatbot_with_memory_claude2.py::test_latency
(2 durations < 0.005s hidden. Use -vv to show these durations.)
=================================================================== 1 passed, 5 warnings in 13.74s ===================================================================
Test Results
┏━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Overall Success Rate ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ test_latency │ │ │ │ 100.0% │
│ │ Latency │ 13.16 (threshold=60.0, evaluation model=n/a, reason=None) │ PASSED │ │
└──────────────┴─────────┴───────────────────────────────────────────────────────────┴────────┴──────────────────────┘
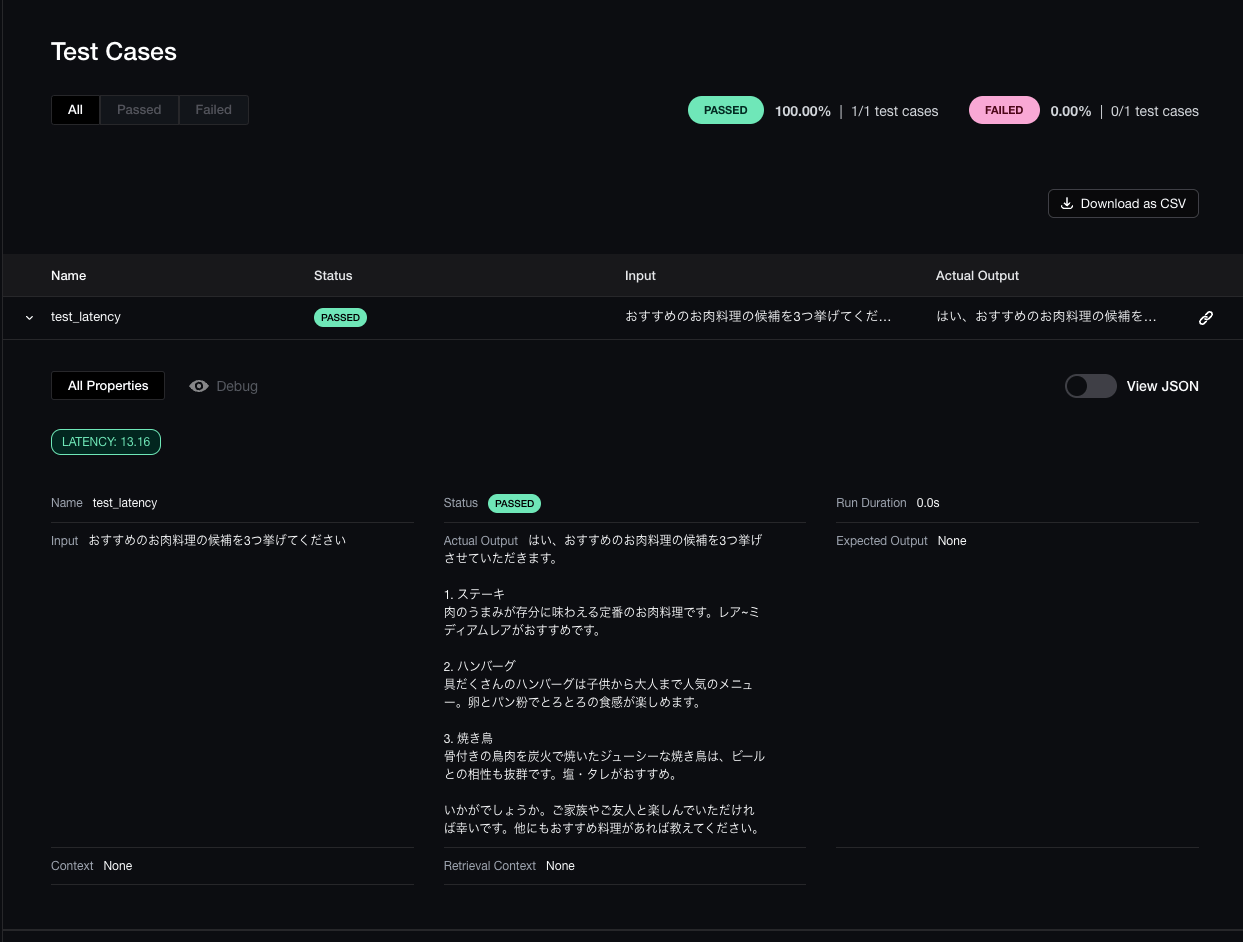
モデルの違いを比較してみる
こちらを参考に、モデルを変更した際の評価結果を比較してみる
別モデルを利用するテストコードを追加
server/tests/test_chatbot_with_memory_claude3.py
import deepeval
from deepeval import assert_test
from deepeval.metrics import LatencyMetric
from deepeval.test_case import LLMTestCase
from langchain.memory import ConversationBufferMemory
from libs.chatbot_with_memory import ChatbotWithMemory
model_id = "anthropic.claude-3-haiku-20240307-v1:0"
# TODO: 重複コードを共通化する
def test_latency():
latency_metric = LatencyMetric(max_latency=60)
chatbot = ChatbotWithMemory(
model_id=model_id,
get_session_history=lambda session_id: ConversationBufferMemory(
session_id=session_id, input_key="question", memory_key="history"
).chat_memory,
)
question = "おすすめのお肉料理の候補を3つ挙げてください"
response = chatbot.invoke(
conversation_id="dummy-conversation-id", question=question
)
test_case = LLMTestCase(
input=question,
actual_output=response["answer"],
latency=response["latency_in_sec"],
)
assert_test(test_case, [latency_metric])
@deepeval.log_hyperparameters(model=model_id, prompt_template="")
def hyperparameters():
return {}
実行結果
poetry run -C server deepeval test run server/tests/test_chatbot_with_memory_claude3.py
# ...中略
server/tests/test_chatbot_with_memory_claude3.py::test_latency Elapsed time: 5.371003150939941 seconds
AIMessage(content='はい、おすすめのお肉料理の候補を3つ挙げます。\n\n1. ステーキ\n- 上質な牛肉を使ったステーキは、シンプルな調理方法で肉の旨味を最大限に引き出すことができます。\n- 好みの焼き加減で、柔らかくジューシーな食感を楽しめます。\n- ソースやサイドメニューを組み合わせることで、様々な味わいを楽しめます。\n\n2. ローストチキン\n- 丸ごと鶏肉を焼き上げたローストチキンは、香ばしい皮と柔らかな肉質が魅力的です。\n- 様々な香草やスパイスを使ってアレンジできるので、好みの味付けが楽しめます。\n- 付け合わせのサラダやポテトなどと一緒に食べると、バランスの良い一品になります。\n\n3. ビーフシチュー\n- 牛肉を長時間煮込んで作るビーフシチューは、肉の旨味が染み込んだ濃厚な味わいが特徴です。\n- じっくり煮込むことで、肉がとろっと柔らかくなります。\n- パンやライスと一緒に食べると、満足感のある一品になります。\n\nいかがでしょうか。ステーキ、ローストチキン、ビーフシチューは、それぞれ特徴的な味わいを楽しめるおすすめのお肉料理です。')
✨ You're running DeepEval's latest Latency Metric! (using None, strict=False, async_mode=True)... Done! (0.00s)
PASSEDRunning teardown with pytest sessionfinish...
======================================================================== slowest 10 durations ========================================================================
5.48s call tests/test_chatbot_with_memory_claude3.py::test_latency
(2 durations < 0.005s hidden. Use -vv to show these durations.)
=================================================================== 1 passed, 5 warnings in 5.97s ====================================================================
Test Results
┏━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test case ┃ Metric ┃ Score ┃ Status ┃ Overall Success Rate ┃
┡━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩
│ test_latency │ │ │ │ 100.0% │
│ │ Latency │ 5.37 (threshold=60.0, evaluation model=n/a, reason=None) │ PASSED │ │
└──────────────┴─────────┴──────────────────────────────────────────────────────────┴────────┴──────────────────────┘
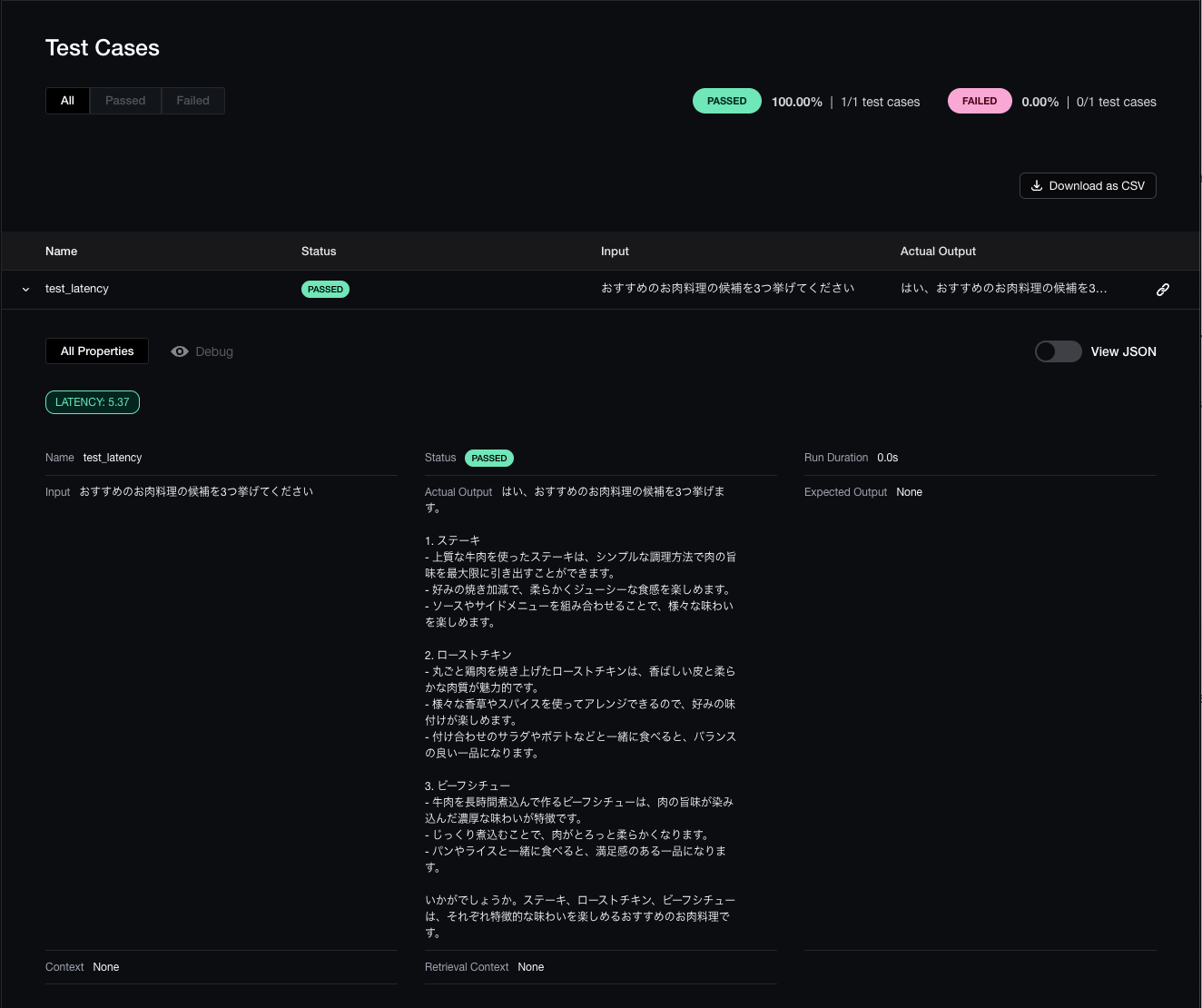
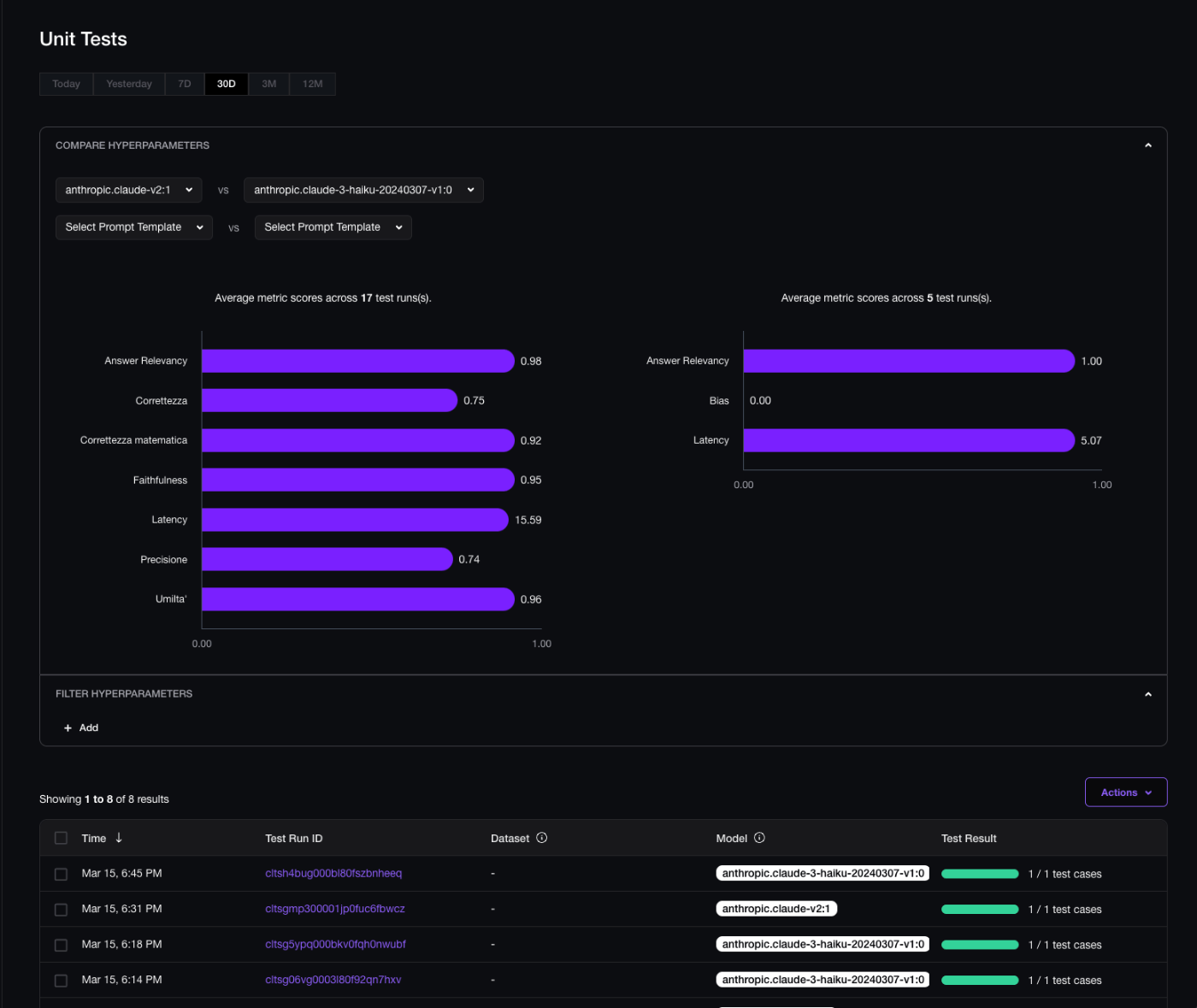
比較結果
モデルごとの結果を比較できた
動作確認時に計測されたメトリクスの結果も含まれているため綺麗な比較にはなっていない
このスクラップは2024/03/15にクローズされました