アニメーションで国会を可視化した個人開発がネットニュースになった話
#国会 Today (kokkai.today) の制作にこめた想いや技術的な解説を書いていきます.

** gif アニメなのでカクついていますが実際はスムーズです.
Google Developer Groups アドベントカレンダーの 24 日目の記事です.
また, この記事は 12/30 に開催される冬コミ C105 のサークル合同紙に寄稿したものの前半部分を元にしています.

ぼーっと眺めたくなるアプリ
情報の流れを見ると落ち着く感覚があります.
Twitter のタイムライン, Flightradar24 の飛行機の動き, Windy.com の風の動き, Mini Tokyo 3D...
今回のアプリである #国会 Today (kokkai.today) は, このような感覚をコンセプトにしています.
従来のワードクラウドを発展させ, 『言葉の泉』のように, 言葉が湧き出るアニメーションで表現した『ワードスプリングス』と, それを使ったアプリケーション, #国会 Today (kokkai.today) の制作にこめた想いや技術的な解説を書いていきます.
#国会 Today とは
#国会 Today は 1 日の国会の衆参の全発言を可視化する Web サービスです.


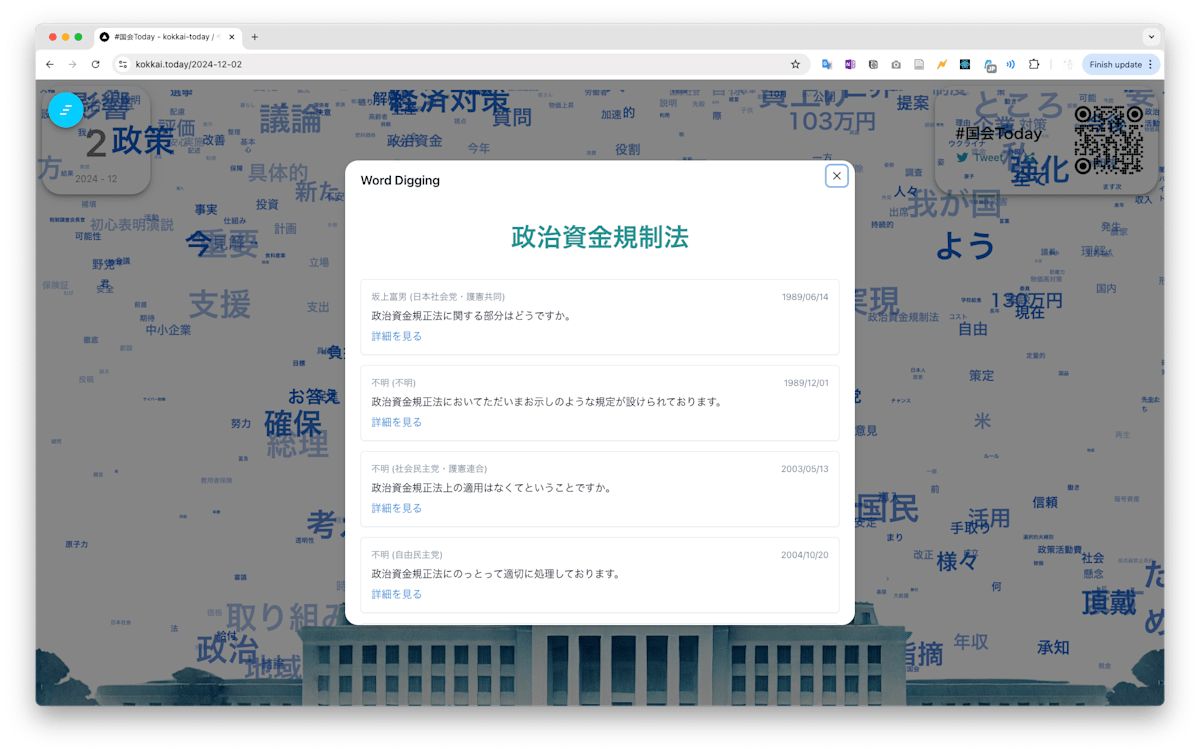
国会図書館の国会議事録 API, 衆議院インターネット審議中継, 参議院インターネット審議中継の 3 つのデータソースから取得した, 1 日の国会の全発言を形態素解析, キーワード抽出し, 言葉が湧き出る泉のようなアニメーションで可視化しています.
ブラックボックスになりがちな国会で今日何が話されたのか, 可視化により国会をより身近に感じてもらい, 国会の議論に参加しやすくすることを目指しています.
公開後たくさんの反響いただき, Twitter (x.com/taniiicom/status/1853418731864739900) で広く拡散していただいたり, ネットニュース (internet.watch.impress.co.jp/docs/yajiuma/1637438.html) に取り上げていただいたりしました.
また, より様々な話題を, ついつい見てしまうような UI で可視化できるように, アニメーション UI の実装を含めた全てのソースコードを OSS として公開しています.
技術について
ソースコードは以下のリポジトリで公開しています.
大きく, tasks と front に分かれており, tasks はデータ取得, 解析, キーワード抽出, front はアニメーション UI を含むフロントエンド (と DB アクセスのための薄いバックエンドを含む) を担当しています.
tasks: データ取得, 解析, キーワード抽出
議事録を取得し, 形態素解析, キーワード抽出を行う部分です.
処理の内容的に, python を使っています.
- 議事録の取得: 国会図書館の API を使って取得
- 形態素解析:
janomeを使って並行処理で形態素解析 - キーワード抽出: 形態素解析の結果から, 名詞を抽出のうえ, 後処理で一部ドメインに特化したヒューリスティックなルールを適用してキーワードを抽出
一般的な形態素解析によるキーワード抽出の流れを踏襲していますが, ちょっとした工夫として, 平行処理 と ヒューリスティックなルール を取り入れているので, その部分について詳細を書きます.
形態素解析の並行処理
1 日の全ての発言を形態素解析する都合上, そこそこ時間がかかります.
なので, 形態素解析の部分は平行処理を入れています.
以下のように, ThreadPoolExecutor を使って, 複数のスレッドで形態素解析を行いつつ, 進捗を表示しています. これにより, 1 日の全ての発言を効率よく形態素解析することができます.
完了後は, トランザクションで, もともとあった古いデータの削除と同時にデータベースに保存しています.
from concurrent.futures import ThreadPoolExecutor
def process_speeches(date):
# スピーチデータを指定した日付から取得
speeches = fetch_speeches(date, start_record=1, maximum_records=100)
all_word_counts = Counter() # 全スピーチの単語出現回数を格納するカウンタ
print(f"Starting text parsing and word count aggregation for {len(speeches)} speeches...")
# ThreadPoolExecutor を使用して並行処理を実行
with ThreadPoolExecutor() as executor:
# parse_text 関数を各スピーチのテキストデータに対して並行して適用
results = executor.map(parse_text, [speech['speech'] for speech in speeches])
# 並行処理の結果を順次取得し, 単語の出現回数を集計
for idx, word_count in enumerate(results, start=1):
all_word_counts.update(word_count) # 各スピーチの単語出現回数を合計
# 進捗を 10 件ごと, またはすべて処理した時点で表示
if idx % 10 == 0 or idx == len(speeches):
print(f"Processed {idx}/{len(speeches)} speeches.")
# 集計した単語の出現回数をデータベースに保存
save_to_postgres(date, all_word_counts)
キーワード抽出のヒューリスティックなルール


** 筆者の 2024-11-25 の発表資料より
上のように, 国会では「閉会中審査」「議院運営委員会」などの複合語が多く登場し, これらの単語を 1 つのキーワードとして抽出することが重要です.
例えば, 「公職選挙法」というキーワードであれば, 公職選挙法に関する議論が行われているということがわかります. しかし, このような複合語を細かく解析してしまうと, 「公職」「選挙」「法」の 3 単語に分かれてしまい, 議論の話題を特定するには一般的すぎる単語になってしまいます.
そこで, ヒューリスティックなルールとして,
- 連続する名詞を 1 単語とみなす後処理
を導入しています.
簡易的ではあるものの強力な方法で, 日本語において, 「1 文節 1 自立語」であり, 複合語以外で名詞が連続することが少ないという特徴を活かしています.
この方法では, 少数ではあるものの, 一定数, 意図しない複合語が出力されるのですが, このような文の構造上たまたま生まれた単語は, ほとんどが 1 回しか生成されない単語であるので, 今回の可視化のような単語の出現回数を使って可視化する場合には, その影響が現れないことがほとんどです.
このように, データマイニングでは, ミクロ的にミスが生じうる手法であっても, マクロ的には大きな影響にならず意味のある結果を得られることも多いので, 局所的な精度にとらわれず, コストと全体の精度のバランスを考えて適切な手法を考えるのが大切なんじゃないかなと思っています.

** 筆者の 2024-11-25 の発表資料より
def parse_text(text):
tokenizer = Tokenizer()
words = []
temp_word = ""
# テキストから人名部分と不要な行を除去
text = remove_speaker_name_and_skip_lines(text)
for token in tokenizer.tokenize(text):
# 名詞であれば一時的に保存し, 次の名詞に連結
if token.part_of_speech.startswith("名詞"):
temp_word += token.surface
else:
# 名詞の連続が終わった場合, 保存してリセット
if temp_word:
words.append(temp_word)
temp_word = ""
# 最後の名詞の連続を処理
if temp_word:
words.append(temp_word)
# 出現回数をカウントして返す
return Counter(words)
ただし, もちろんこの手法で上手くいかないのもあります. 例えば, 「後日理事会」という単語はよくくっついて出てきてしまいます.
先日, 一橋大学の小町守教授とお話しさせていただき, 本当にありがたいことにご厚意でたくさんのアドバイスをいただいたので, これから様々なアイデアを試していくのが楽しみです!
front: アニメーション UI を含むフロントエンド (と DB アクセスのための薄いバックエンドを含む)
可視化において, 一番重要なのは, どのようにデータを表現するかです.
今回のアプリにおいて目標としたのは, 『ぼーっとつい眺めたくなるアプリ』.
なので, フロントエンドの実装についても, ここでは, アニメーション UI の実装について詳しく書きます.
「ぼーっとつい眺めたくなるアプリ」を実現するために, 各単語は, 頻度情報に基づいて, 以下のようなスタイルの変化をつけて, framer-motion を使ってアニメーションされています.
-
サイズ (fontSize)
単語の大きさは, 表示される単語の「出現頻度」に応じて変化します. 頻出度が高い単語ほど大きく表示されるようにデザインされています.
また, 1 日のなかでの相対量だけでなく, その日の議論の盛り上がり度も表現できるように, 絶対的な指標を取り入れています. (国会で議論が白熱した日は画面を埋め尽くすように単語が溢れる)const fontSize = Math.min(50, wordCount.count * 2);- 単語の頻出度 (
count) が増えるごとに比例して拡大
- 単語の頻出度 (
-
透明度 (opacity)
単語の透明度にはランダム性を加え, 奥行きを表現しています.
これにより, アニメーションに深みが生まれ, 柔らかく有機的な印象を与える効果があります.const randomOpacity = 0.3 + Math.random() * 0.7;- 透明度は 0.3〜1.0 の範囲でランダムに設定.
- 視覚的に強弱が生まれ, 単語が画面を漂うような感覚を演出.
-
速度 (duration)
単語の動く速度はランダムに設定されます. これにより, 単語ごとに異なる速度で画面を上昇し, 自然で動きのある画面を作り出します.
それぞれのオブジェクトは, 等速運動であっても, オブジェクトごとにその速度が異なることで, 一気に自然な動きになります.
桜の花びらが落下するのと同じで, 終端速度に達することで等速運動になるものの, それぞれの花びらがわずかに異なる速度で落下することで, 自然で美しい動きになります.const animationDuration = 15 + Math.random() * 5;- アニメーション持続時間は 15 秒〜20 秒.
- 単調な動きではなく, ゆったりとした変化が画面にリズムを与えます.
-
左右の位置 (left)
単語の初期位置は画面の横幅 0% から 100% の範囲でランダムに配置されます.const randomLeftPosition = Math.random() * 100;- ここは, 今後応用が可能な部分です. 例えば, 発言者の与野党別で左右に分けるなど, さまざまなアイデアが考えられます
-
上下の動き (y 軸アニメーション)
単語は画面の下部から上部へと流れ, 画面外に消えた後も再度表示されます.animate={{ y: `-${window.innerHeight + fontSize * 2}px` }}- 動きの開始地点は画面の下部 (高さの外側).
- 単語は画面の高さ以上の距離を上昇し, ループします (
repeat: Infinity).
さらに, インタラクティブな要素として, 単に単語が流れるだけでなく, ユーザーが単語をクリックすることで, その単語が含まれる発言を議事録データから検索し, より深い情報にアクセスする機能を, bunko.jp さんとのコラボレーションにより実現しています.
単語をクリックすることで, その単語が含まれる発言を議事録データから検索し, その発言の前後を確認することができます.
このあたりのコンポーネントを跨いだ状態管理では, recoil を使ってシンプルかつ, 疎結合を維持したまま, グローバルな状態管理を行っています.
制作の想い
国会では, 1 日に, 衆議院・参議院, 本会議・委員会で様々な議論がされています.
しかし, メディアがニュースとして取り上げるのは, その中のほんの一握りの話題のみです.
しかも, 「政治」と聞いてすぐに思い浮かぶような一部の大きな政治的議題を除けば, 多くの法案は本会議の採決の段階になってようやくニュースに取り上げられるのです.
これでは, 議題について, 世論として意思表示をするのが遅れてしまいます. 採決よりももっと前の段階で, 議題を見て, 国民が議論に参加し, 選挙の時だけでなく, 常に世論として意思表示することが, 民主主義において重要だと考えています.
オープンデータや情報開示の進展により, 一次情報にアクセスすることは容易になりました. しかし, そのままその情報を扱うには, 多くの時間と労力が必要です.
情報があっても, その情報が届かなければ, 届かない人にとってはその情報は存在しないのと同じです.
もっと気軽に, ぼーっと眺めるだけで, 国会の内側を知ることができる. そこから, 心の中にちょっと意見が生まれる, ちょっと考えを表明してみる. という体験が, 制作にこめた想いです.
この記事は 12/30 に開催される冬コミ C105 のサークル合同紙に寄稿したものの前半部分です.
後半部分は, 月曜日 東ア41b で頒布される citruz.dev/v2024win に掲載される予定です. 後半部分では, 誰でも『ワードスプリングス』を使った可視化ができるような簡単なレシピを書いています.
レシピは初心者向けなので, 経験者の方はあんまり必要ないかもしれないのですが, 他の方の記事とかわいい表紙がおすすめなのでよければぜひ.
1 日の半分くらい滞在している予定なので, お話しだけでもお気軽にお立ち寄りください〜!
Discussion