機械学習の実験パイプラインを Buildkite で構築したら PoC サイクルを高速で回せた話
本記事は Uzabase Advent Calendar 2023 の 24 日目の記事です。
はじめに
私の所属チームでは、ある機械学習モデル(以下モデル)の推論精度を高める目的で、モデルに対して実験を行うパイプラインを Buildkite で構築しました。その結果、PoC のサイクルを高速に回すことができたので、やり方を共有したいと思います。「実験管理をなるべく自動化して PoC を高速に回したい」という方の参考になれば嬉しいです。
どんな PoC をやったのか?
「モデルの推論精度が XX % 以上になるような入力データを作ること」を目的として、以下の図のような流れで実施しました。
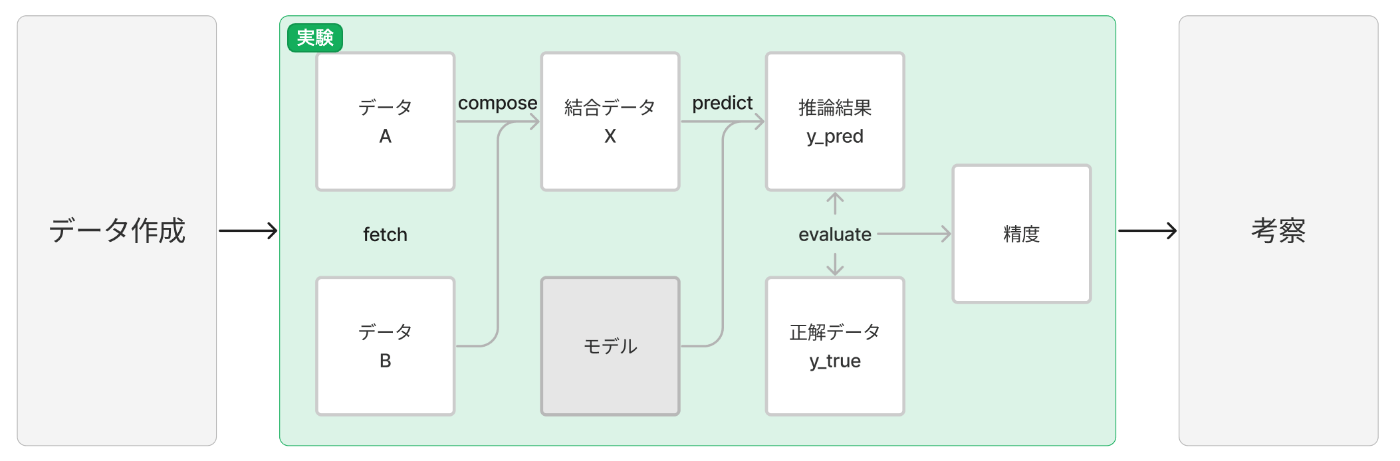
1. データ作成
実験用のデータ(図では データA と データB)を用意します。このデータを修正していくことで精度改善を目指します。
2. 実験
4 つのステップを順に実行します。
| # | ステップ | やること |
|---|---|---|
| 1 | fetch | データA と データB を取得します。 |
| 2 | compose | データA と データB を結合して データX (predict できる形式)を出力します。 |
| 3 | predict | 結合データ X をモデルに入力して得られた推論結果( y_pred )を出力します。 |
| 4 | evaluate | 推論結果 y_pred を正解データ y_true で評価し、精度を出力します。 |
3. 考察
得られた推論結果や精度を見て、より良い精度を得られそうなデータを考察します。
PoC のサイクルを高速で回すために実験で重視したいこと
再現性の確保
使用したデータ、モデル、パラメータ、ソースコードなど、実験に紐づく情報は複数あり、これらを手動で管理すると情報が失われるリスクが大きくなります。もしそうなった場合再現が困難になり、サイクルの中断を招きます。そのため、以下のことを自動化することでリスクを回避します。
- 実験ごとに識別子を付与
- 実験ごとにコミットハッシュを紐付け
- データのバージョニング
監視の効率化
実験のワークフローとステータスを GUI で可視化することで、デバッグしやすくします。
試行回数を増やしやすくすること(試行回数増加の容易化?)
実験を並列で実行できるようにします。
実験で重視したいことを Buildkite で実現する
Buildkite は CI/CD 用のパイプラインとして用いられることが多いですが、先ほどの 4 つのステップを持った実験用のパイプライン(以下実験パイプライン)として用いると、以下の 4 つはすぐに実現できます。
実験ごとに識別子を付与
実験パイプラインをビルドするごとに付与される Build number を利用
実験ごとにコミットハッシュを紐付け
実験で用いたソースコードは全てひとつのリポジトリで管理し、実験パイプラインにリポジトリを登録する
実験のワークフローとステータスを GUI で可視化
ビルドごとに GUI でワークフローと各ステップのステータスが可視化されます
実験を並列で実行
実験パイプラインの yml ファイルでは、ステップごとに agent と呼ばれるビルドランナーを指定します(以下のコードでは ml-experiment-agent )。ステップに登録されたコマンドは agent の環境でジョブとして実行されます。
steps:
- label: "fetch"
command:
- ...
agents:
queue: "ml-experiment-agent"
- wait
- label: "compose"
command:
- ...
agents:
queue: "ml-experiment-agent"
- wait
- label: "predict"
command:
- ...
agents:
queue: "ml-experiment-agent"
- wait
- label: "evaluate"
command:
- ...
agents:
queue: "ml-experiment-agent"
リポジトリ中の ml-experiment.yml を実験パイプラインに登録し、かつ ml-experiment-agent に複数の実行環境( k8s の Pod など)を登録することで、同じパイプラインの別々のビルド(実験)を並列で実行することができます。
データのバージョニングを Buildkite で実現する
実験パイプラインのビルドごとに GCS にフォルダを作成し、そこにステップごとに出力されたデータを保存することで実現しました。わかりやすさのためにステップが fetch と compose のみの図で表すと以下のようになります。

fetch するデータはビルド前に置く必要があるので、 GCS の static_files というフォルダに置きます。 static_files 内のフォルダの分け方は任意です。 fetch および compose で出力されたデータは、 static_files と同じバケットにある history フォルダ内の 1 フォルダに自動で保存されます。 history フォルダ内のフォルダはビルドごとに自動で作成され、フォルダ名は Build number です。
上記のデータのバージョニングを実現するために、 Buildkite の Repository hooks と Artifacts という機能を用います。まず、リポジトリ直下に ./buildkite/hooks/pre-command ファイルを置くことで、各ステップのコマンド実行前にファイル内のスクリプトが実行されます。
export BUILDKITE_ARTIFACT_UPLOAD_DESTINATION="gs://my-bucket/history/$BUILDKITE_BUILD_NUMBER/$BUILDKITE_JOB_ID"
BUILDKITE_ARTIFACT_UPLOAD_DESTINATION は実験パイプライン上のファイルをアップロードする先のパス、 BUILDKITE_BUILD_NUMBER は Build number 、 BUILDKITE_JOB_ID はステップの ID を示す環境変数です。ファイルのアップロードは buildkite-agent artifact upload コマンド、ダウンロードは buildkite-agent artifact download コマンドで行います。また、アップロードはステップで artifact_paths を設定することでもコマンド実行後のアップロードが可能です。上図を実現する実験パイプラインの yml ファイルは以下のようになります。
steps:
- label: "fetch"
command:
- rm -rf data | true
- mkdir -p data
- gcloud storage cp gs://my-bucket/exp1 data
- buildkite-agent artifact upload "data/*"
agents:
queue: "ml-experiment-agent"
- wait
- label: "compose"
command:
- buildkite-agent artifact download "data/*" data/ --step "fetch"
- [compose のコマンド]
artifact_paths:
- "data/*"
agents:
queue: "ml-experiment-agent"
終わりに
今回の PoC は XP (eXtream Programming) のプラクティスに基づいて取り組んでいます。 XP についても興味がある方はこちらの発表もご覧いただけると嬉しいです。
Discussion