なるべく安くマネージドにDynamoDB上のデータに対してリレーショナルクエリを実現するスレ
やりたいこと
- 日々のトランザクションはDynamoDB(プライマリデータベース)で管理
- toCアプリケーションなので、エンドユーザー個人のデータに関してはNoSQL + イベント駆動サーバーレスがかなりフィットしている
- 非同期で構わないので、溜まったデータに対して管理サイドがアドホックかつリレーショナルなクエリを発行できるようにする
- 例えば「予約検索」のような機能は、エンドユーザーには不要だが管理者側の画面にはついていると嬉しい
現状
- DynamoDBからStream => SQS => Lambda経由でAurora Serverless v1に反映(REPLACE INTOまたはDELETE句を使用)
- 非同期で全く問題ないため、OLTP機能等は不要だが、Aurora Serverless v1はコールドスタートがやはり遅く、常時起動するには高い。本当に一部の検索画面でしか使わない機能なのに常時コストかけたくない
戦略その1
DynamoDB Stream => Kinesis Data Stream => Kinesis Firehose => S3 => Athenaでクエリ
メリット
- 安そう。
- 完全ノーコードでいけそう
デメリット
- 断面を取れるわけではなく、MODIFY/REMOVE/INSERTのイベントをクエリできるだけなので、集計関数を使って最新の状態を表現するビューを作成する必要あり
- その場合、スキャンする分量は増えそう
- そもそもやりたいことが最新の断面に対するリレーショナルなクエリなのに、変更ログイベントに対する集計という知識も混在するようになるとすこし辛そう
実は集計関数ビューを使ってCTASし、それに対してさらに新たな断面ができるたびにCTASし続けるというトーナメント型式もありなのかもしれない。
ちなみに、Kinesis Firehoseで蓄積されたログに対してのAthenaクエリは、以下のようなカスタムプレフィックスを定義しないとパーティションがうまく効かず実行できない。
任意のディレクトリ/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
戦略その2
DynamoDB Stream => Kinesis Data Stream => Kinesis Firehose => S3 => Lambda => Redshift(Upsert)
- RedShiftは、ワークテーブルを作成してデリートインサートする方法が確立されているのでそれを使う。
- デメリットとして、集計ではなく検索目的で使う場合においてはかなり遅いし高かった気がする。
戦略その3
(定時実行のStepfunctions) => DynamoDB PITR S3 Export => Athena
メリット
- 構成としてはDeadly Simple。
- PITR S3 ExportはRCUの消費量ゼロなので、安そう。
- Athenaのクエリ対象としてもかなりシンプル(最新の断面そのまま)なのでクエリも簡単そう。
デメリット
- どうしてもエクスポート自体が断面指向のため、実行間隔やタイムラグが気になる。
- 意外とそれぐらい、、、?
戦略その3
を目指して一度やってみることにする。
なるべく簡単に済ませたいので、Lambdaの記述等もしたくない。
ということで、まずはStepFunctionsのビジュアルなエディタから、DynamoDBのAPIをキックできないか検証する
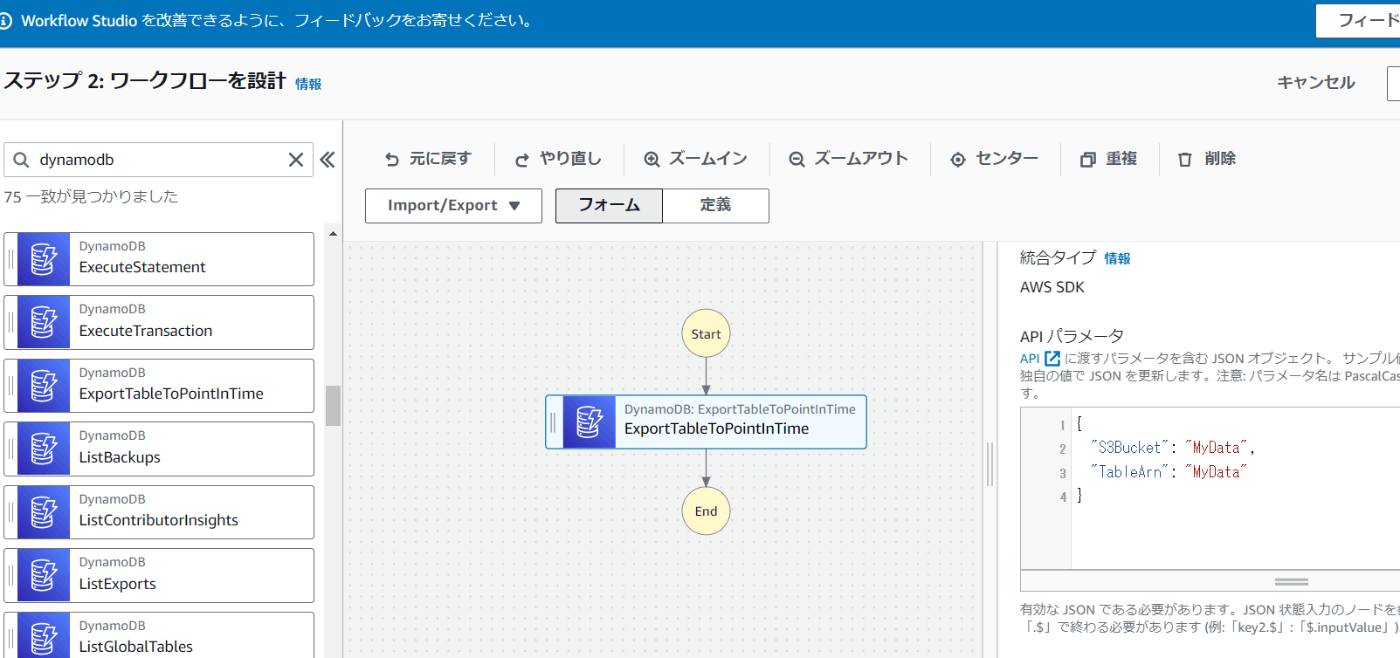
これでいいのか・・・?

現在時刻18:46なので、だいたい全エクスポートで8分程度かかる計算。
絶妙だな、、、
少し変更が加わったのちおなじprefixに再出力した際には少し早くなってるとかあるのかわからんが、とりあえずこれに対してAthenaでよいかんじにクエリできないかを検証してみる。
Glue Clawlerでクロールしてみる。
しかしディレクトリ構成に元のDynamoDBのテーブル名が全く入ってないのでクローラ経由だと変なGlueテーブル名になってしまうな、、、
Athenaは#が列名に入ってると落ちるので一回定義をコピーして_に置換してから戻す必要がある。
もう慣れたけど普通に不便すぎる
簡単なクエリ(JOINあり、WHEREあり、ORDERあり)一本で30秒ぐらいかかってしまった。
索引など貼れないか検証する

結論だがおそらくAthenaには単純な索引というものは存在しない。
今回やりたいことは、本来であれば日付でパーティショニングされるであろう予約データを、それでも過去まで遡って一気に検索するということなのでどうしてもパーティショニングは使いづらい。(というかそれで絞れるなら別にDynamoDBでかまわない)
ある種アドホックに後から索引が貼れるデータベースの方がまあ使い勝手は良いか、、、
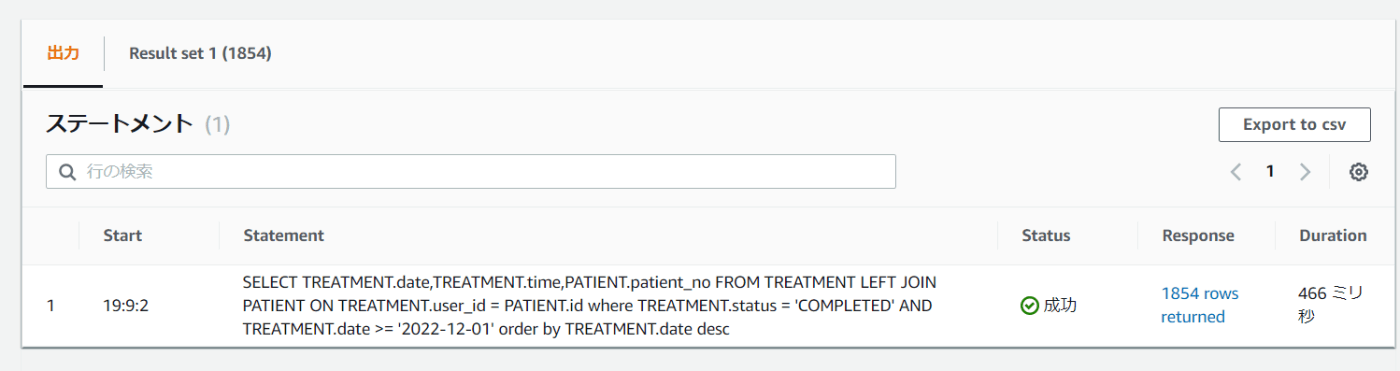

ほぼ同じ内容のクエリを比較してみても、Aurora Serverless v1であれば1秒未満で返ってくるクエリがAthenaでは16秒とかなり顕著な差が出ている。
まあ、1分以内であればよくね?とは一瞬思ってしまうが、、、
ふと思って、結合済みのマテリアルビューテーブルをCTASで作ってみる。
結合自体を先に行っておき、それを_JOINEDという名称のテーブルにしておく。
そこに対して後でクエリをかけてみた。
するとそちらのクエリ自体はかなりのスピードで完了した。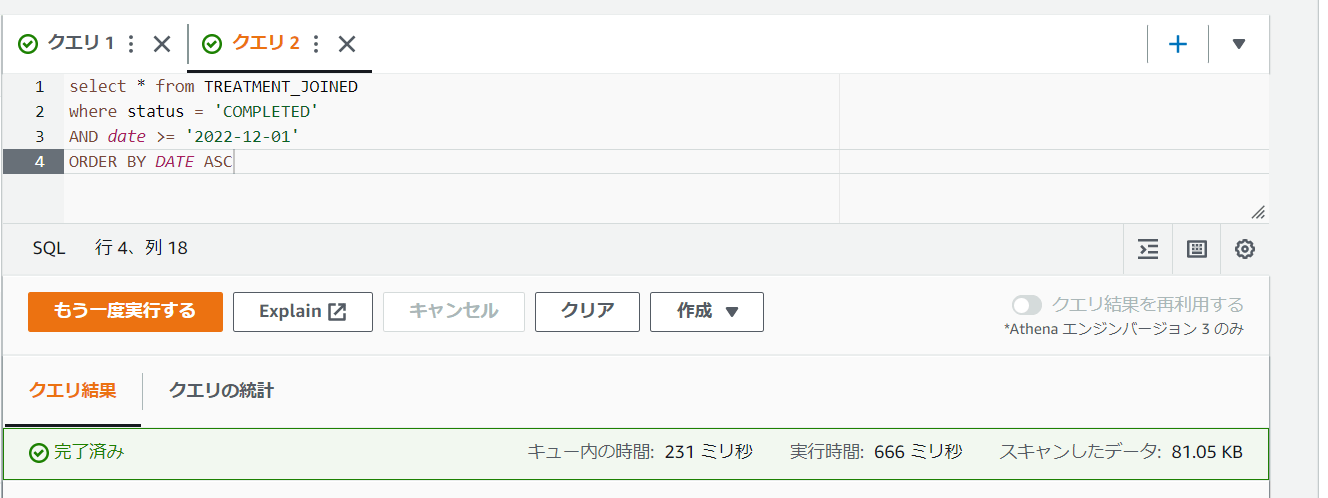
やはり対象のデータが大きいことと、結合がハイコストだったのか?
DynamoDBから直エクスポートしたJSONには、かなりいろいろな情報が含まれている(そのうちほとんどは検索にも出力にも使わない)
それをCTASでうまく削ぎ落したり、結合の前処理を行ったりしてあげると、かなり実用性があったりするのだろうか。
気が付けば、EXISTS句などのDEPENDENT SUBQUERY自体をほぼ使っていないうえ、今後も使わなさそうなので、そう思うとエクスポート ~ CTASを一つのワークフローとし、更新をトリガーとするバッチウィンドウの中で済ませてしまって、そこに対してクエリするような感じにするとひょっとしていいのだろうか・・・?
ただ、増分更新に比べてこちらの方法では常に全データのスキャンが必要になるので微妙そう。
他に試してみたいこと
- BigQuery
- OpenSearchService Serverless
- ただやっぱりSQL使いたいのでluceneベースはちょっと、、、
- PlanetScale等パブクラ以外のマネージドRDBMS
- Cloudflare D1
結論
UPDATE,DELETEも含めて日々更新されるデータを、多少静的なストレージにレプリケートする場合においては、
- 差分適用
- 全量取込
- 差分集計
の三つのパターンがある。
差分適用のパターンにおいては、すなわち更新や削除が自ら行える(同期ができる)必要があるため、比較的リッチなOLTPに近い機能が必要になる。 => Aurora等
全量取込のパターンにおいては、データの圧縮や取捨選択などを通してパフォーマンスの改善ははかれるものの、更新されるたびに全量のスキャンが必要になるため長期的なコストパフォーマンスは怪しい。(詳細コスト未検証) => DynamoDB Export からの Athena CTAS等
差分集計のパターンにおいては、詳細な分析を行いたい場合には簡便だが、何度も繰り返しアドホックに検索を行うことを考えると最もスキャンデータ量としては大きくなる。 => DynamoDB Kinesis Streamからの Athena集計等