DeepFakeの仕組みを全て解説してみた
はじめに
本記事では、既存のDeepFake技術がどのような仕組みで動いているのかを解説します。
DeepFakeのオープンソースプロジェクトで有名なものとしてFaceFusionがありますが、本記事ではこのFaceFusionの実装に沿って解説していきます。
余談ですが、僕はFaceFusionの開発メンバーです。
DeepFakeとは
基本的に、FaceSwapはsource画像, target画像というものを用意し、source画像の顔をtarget画像に当てはめます。
従来のDeepFaceLabなどに代表される手法では同一人物のsource画像を大量に用意し、GANと呼ばれる手法でその場でモデルを学習し、推論させるというものでした。
この手法では極めて高い精度を出すことができますが、大量のデータセットを用意する必要がある・学習に時間がかかりすぎる・学習が難しいなど多くのデメリットもありました。
そこで近年注目されているのが、事前学習済みモデルを用いて1枚のsource画像からFaceSwapを行うという手法です。
この手法ではその場でモデルを学習させる必要がないため、非常に高速でoutputを出力することができます。(RTX 4090のCUDA環境で80fps程度)
また、source画像も1枚あればいいので非常に手軽です。
この手法自体は以前からあったのですが、InsightFaceが出したinswapper_128というモデルが非常に精度が高かったため、現在では主流となっています。
さて、長々と書きましたが、本記事ではINSwapper等の事前学習済みモデルを用いたFaceSwapのワークフローを解説します。
source画像の前処理
source画像を顔交換モデルに入力できる形式にするまでの前処理です。
source画像の前処理は顔交換モデルによって、画像をそのまま渡す場合と顔の特徴量を抽出してから渡す場合があります。
前者の場合は以下に記述する顔の位置合わせまで、後者の場合は顔認識まで行います。
1. 顔検出
まず、画像から物体検出モデルを用いて人間の顔を認識します。
モデルが出力する情報は顔の領域を四角で囲ったbounding_boxと、両目、鼻、口の端の5点のkey_pointsです。
key_pointsを以降の処理で使います。
以前書いたYOLOv8に関する記事に詳しい解説が載っています。
使用するモデルの例
- YOLOv8
- Yunet
- RetinaFace
2. 顔の位置合わせ
次に、モデルに渡す前の準備として、顔検出から得られたkey_pointsを使って顔の位置合わせを行います。
モデルに渡す前の準備として、key_pointsがモデルのテンプレート(トレーニングデータセットの平均のkey_points座標)に合うようにaffine変換によって画像を回転させ、さらに全体の画像から顔だけを四角形で切り取ります。
3. 顔認識
位置合わせされた顔の画像を入力として、顔認識モデルによって顔の特徴量を抽出します。
具体的には、画像のピクセル情報からモデルの推論によってベクトル化された特徴量を得るというものです。
なお、顔認識モデルは顔交換モデルとセットで使います。
使用するモデルの例
- ArcFace
target画像の前処理
こちらもtarget画像を顔交換モデルに入力できる形式にするまでの前処理です。
target画像の前処理では、位置合わせされた画像から顔のマスクを生成し、顔を切り取ります。
なお、顔の位置合わせまではsource画像と全く同じ処理をするので、省略します。
顔のマスク作成
targetの顔から顔のマスクを作成します。
深層学習モデルを用いて顔の輪郭を切り取ってマスクを作成する方法と、モデルの推論を挟まずに四角形で切り取る方法があります。
どちらを使ってもいいですが、
・輪郭を切り取った場合は精度が上がる(顔周辺のチラつきが減る)代わりに速度が落ちる
・四角形で切り取った場合は非常に高速になるが精度が落ちる(気にならない場合も多い)
という精度と速度のトレードオフの関係になっています。これはタスクによって使い分けるといいでしょう。
使用するモデルの例
- face-occluder
- face-parser
顔交換
上記の手順によってsource画像, target画像を前処理したものをFaceSwapモデルに入力します。
FaceSwapモデルはGANベースの手法(StyleGANなど)によって事前学習され、モデルはEncoder-Decoderの構造になっています。
source画像, target画像から特徴量を抽出(Encoder)
↓
潜在空間上でsource, targetの特徴量を合成
↓
合成された特徴量から画像を復元(Decoder)
という流れです。特徴量合成の部分の手法が顔交換モデルにとって鍵となっています。
ちなみに、source画像の前処理の部分で記述した、画像をそのまま入力するか特徴量を抽出してから入力するかという違いは、Encoderがモデルと一体となっているか分離されているかの違いだけです。
さて、このようにしてモデルに推論させた結果、target画像の顔の特徴(表情や照明条件など)を保持したsourceの顔の画像が生成されます。
使用するモデル例
- INSwapper
- SimSwap
- BlendFace
後処理
顔交換によって生成された顔の画像を、元の全体のtarget画像に貼り付けます。
target画像のaffine変換に使った行列を使って逆affine変換を行い、元の位置に戻します。
そして、その画像をtarget画像に貼り付けます。
以上で顔交換は完了です。
おわりに
本記事ではDeepFakeがどのように行われているかを解説しました。
ここからは少し宣伝です。
FaceFusionの実装を参考に、さらに速度を最適化したMimixというプロジェクトを作りました。
プレビュー:
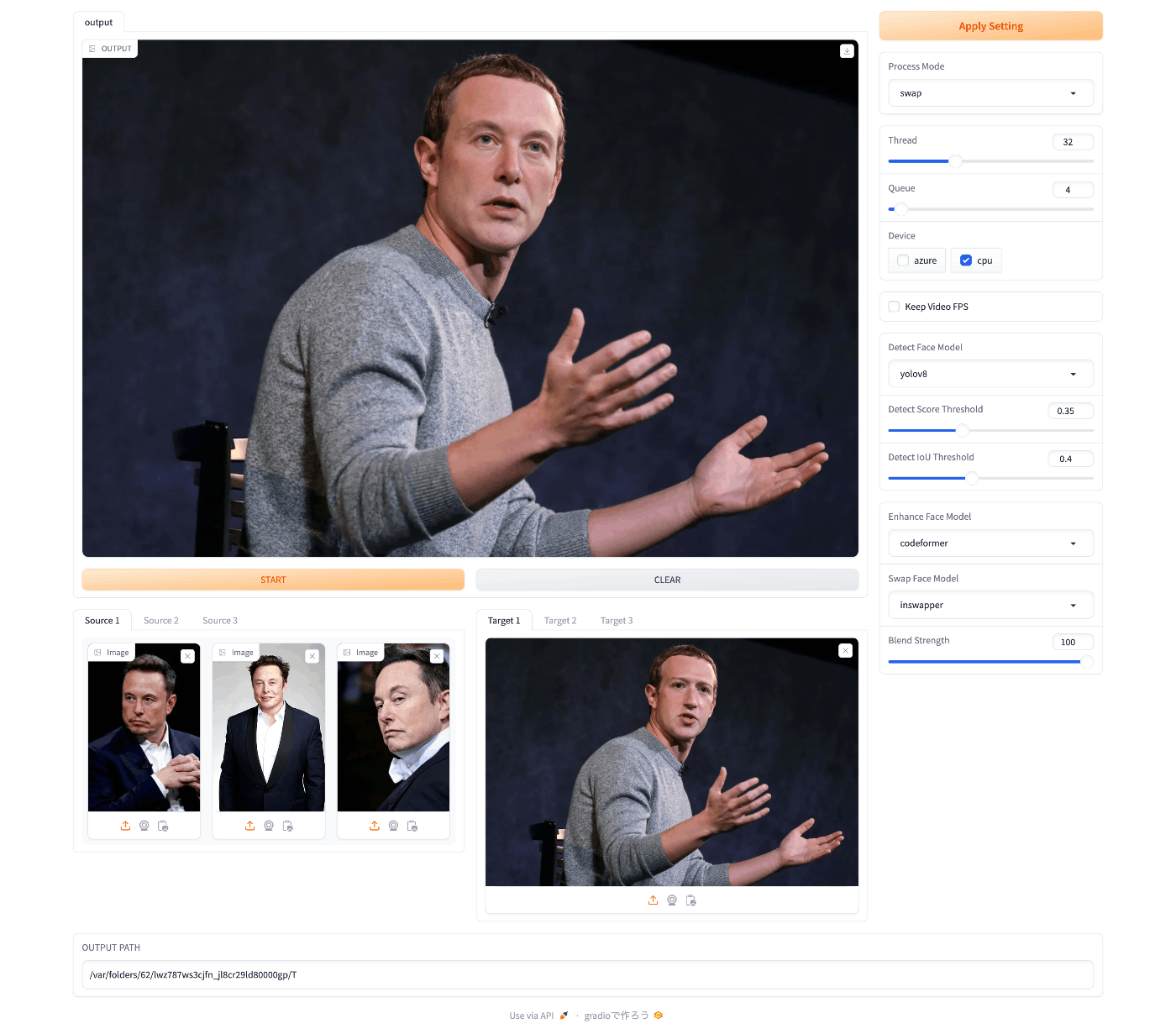
これからの展望としては自分でモデルをFinetuningまたはワークフローを改善し、アジア人に特化したものを作りたいと考えています。
というのも、現在のDeepFakeモデルは欧米人などは非常に高い精度が出るのですが、アジア人に関してはモデルのポテンシャルを100%発揮しているとは思えない精度だからです。
また、速度の最適化に関しても十分ではないと感じています。
まだまだ改善の余地があるプロジェクトですが、ぜひチェックしてみてください。
また、プログラミングを学ぶコミュニティCodeNestを作りました。
完全初学者から1ヶ月でコードが書けるようにロードマップを作っています。
機械学習についても学べるので、興味のある方は参加してみてください。
Discussion