🚚
DynamoDBからSQLiteに移行した


概要
DynamoDBに保存しているデータをCSVでエクスポートしSQLiteにインポートしたのですが、その手順や作業をするにあたっての注意点を書いています。
なぜ移行するのか
もともとAWS AmplifyでWebアプリケーションを運用していましたが、ツールとして少人数が使用しており、管理していたデータもそれほど多くなかったためです。
それ以外にもユーザビリティなどの観点から別のアプリケーションとして切り出す形になりました。
手順
今回は次のような手順で作業を行いました。
- DynamoDBからデータをエクスポート
- SQLiteにデータをインポート
- 整合性の確認
1. DynamoDBからデータをエクスポート
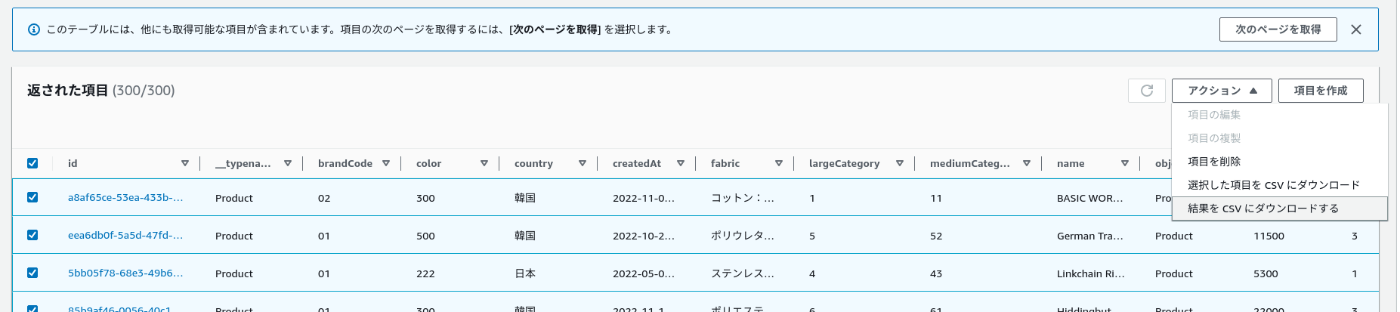
AWSのコンソールから直接出力結果のCSVをエクスポートできます。
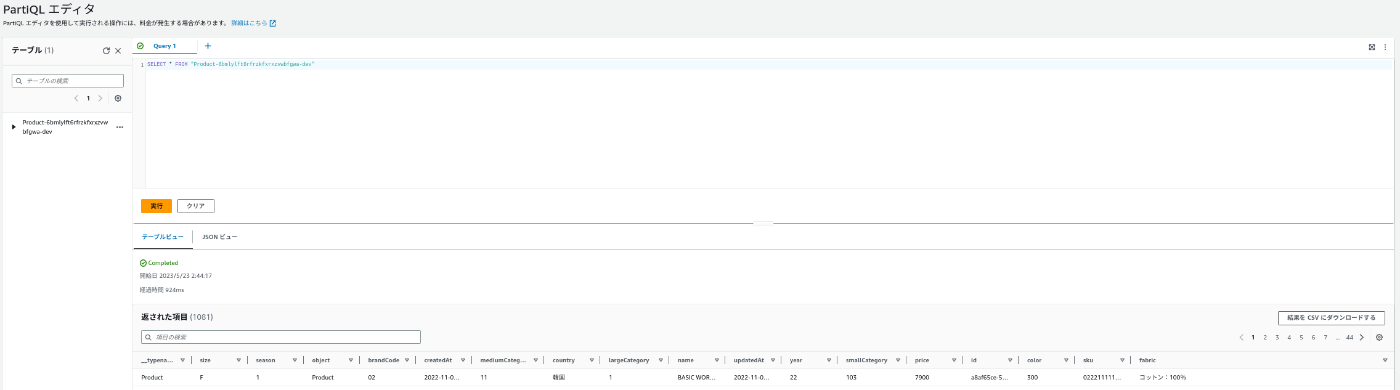
ただ項目のスキャンをするだけだと最大300件ずつしか読み込めないので、PartiQLで全件取得するのが楽です。
項目のスキャンで取得
PartiQLで取得
2. SQLiteにデータをインポート
エクスポートされたCSVをパーサを通してデシリアライズ後、SQLでバルクインサートします。
デシリアライズには PapaParse を使用し問題なくデシリアライズできましたが、SQLでバルクインサートをせず、逐次インサートする形にするとExpressプロキシのハングアップや実行時間が長くなってしまうことがありました。
バルクインサート時生成されるプレースホルダの例
INSERT OR IGNORE INTO stickers
(sku, name, price, fabric, country)
VALUES
(?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?), (?, ?, ?, ?, ?)
3. 整合性の確認
エクスポートとインポートが完了したらDynamoDB側とSQLite側でデータに差異がないか確認します。
今回はCSVを介しているのでそれぞれ出力結果CSVからdaffを使って比較します。
daffを使った比較

一部項目を抽出していると上のような表示になります。
主要なデータに違いがないのでこれでOKです。
まとめ
DynamoDB側でエクスポートしたCSVをSQLite側でインポートしました。
- テーブルからの全件データ取得をするためにPartiQLを使う
- SQLはバルクインサートでまとめておく
- daffで整合性を確認
が大事かなと思います。
Discussion