Rust で GraphQL server を書いてみた
こんにちは
どうも、僕です。
みなさん、Rust 書いていますか。自分は最近入門しました。
今回は、元々 Go で書いていた個人ブログのサーバサイドを Rust で書いてみたのでそれについて書きます。
ソースコードはこちら。
※ 筆者がこのコードを書き始めた段階での Rust 力は Tour of Rust を1周流し読みしたくらいの力量です。
どうして Rust なのか
個人的に入門してみたかったから。これに尽きます。
自分はフロントエンドの技術が好きで、普段からブラウザに近い部分のコードを書く機会が多いです。
そこでどうして Rust かというと、最近のフロントエンドはアプリケーションのランタイムの部分は従来通り JavaScript で動作している状態ではありますが、ビルド周りであったりのツールチェイン周りは他言語に置き換わるケースをしばしば見かけます。具体的な例で言うと、esbuild は Go で書かれていますし、swc は Rust で書かれています。
以上のような背景から、元々興味があったが手を出していなかった Rust に、自分が普段触れることが多く、最低限の知見は持っているウェブアプリケーションのコードという形で入門をしようと思い、Rust を選びました。
今後はさらに広い分野に手を出していこうと思っています。
使用ライブラリ
まずは、今回の開発で使用したライブラリについて説明をします。
axum
ウェブサーバを動かすために axum というフレームワークを使用しました。
バージョンは 0.5.7 を使用しています。
axum = { version = "0.5.7" }
axum は比較的新しいフレームワークで、昨年7月に初回のリリース がされました。
Rust の非同期ランタイムでメジャーである tokio から出されているクレートであり、tokio のエコシステムとの親和性が非常に高いです。
async-graphl
GraphQL のライブラリは async-graphql を使用しました。
バージョンは 3.0 を使用しています。
async-graphql = { version = "3.0", features = ["chrono"] }
GraphQL のライブラリは他に juniper や Apollo がありますが、今回は axum の examples に async-graphql があり、実装の参考になりそうだったのでそのまま選定しました。
個人的に、GraphQL はスキーマベースで開発するのが好みですが、今回は物は試しだ!と思い使ってみました。
Rust でスキーマファーストな設計をした GraphQL server を作りたい方は、rusty-gql というライブラリがあり、下記の記事で作者の方が紹介をしています。
sqlx
データベース接続は sqlx を使用しました。
バージョンは 0.5.0 を使用しています。
sqlx = { version = "0.5.0", features = [ "mysql", "runtime-tokio-rustls", "time", "chrono" ] }
個人的な好みとして、ORM よりはクエリを文字列で記述してマッピングしたい派だったので、diesel と迷った末に sqlx を選択しました。
これは書いてる途中に驚いたことなのですが、sqlx の query! というマクロはコンパイル時にデータベースを見に行き、型をチェックして戻り値をマッピングします。すごい型安全だと思ったのですが、それは同時にコンパイル時に接続先のデータベースが起動していないといけないわけで、例えば CI や CD の時どうするんだっけ?みたいなことは気になりました。
エンドポイントを定義する
実際にアプリケーションの部分を書いていきます。
まずはエンドポイントを定義します。
エンドポイントは1つ、メソッドは2つ定義します。
- playground 用の GET リクエスト
- server としての役割を果たす POST リクエスト
#[macro_use]
extern crate thiserror;
mod resolvers;
use axum::{
extract::Extension,
response::{Html, IntoResponse},
routing::get,
Json,
Router,
};
use async_graphql::{
http::{playground_source, GraphQLPlaygroundConfig},
EmptyMutation,
EmptySubscription,
Request,
Response,
Schema,
};
use std::net::SocketAddr;
use resolvers::QueryRoot;
// QueryRoot は resolver で定義
pub type BlogSchema = Schema<QueryRoot, EmptyMutation, EmptySubscription>;
// GraphQL server
async fn graphql_handler(schema: Extension<BlogSchema>, req: Json<Request>) -> Json<Response> {
schema.execute(req.0).await.into()
}
// playground
async fn graphql_playground() -> impl IntoResponse {
Html(playground_source(GraphQLPlaygroundConfig::new("/")))
}
#[tokio::main]
async fn main() {
let server = async {
let schema = Schema::build(QueryRoot, EmptyMutation, EmptySubscription)
.finish();
// "/" でリクエストを待つ
let app = Router::new().route("/", get(graphql_playground).post(graphql_handler))
let addr = SocketAddr::from(([0, 0, 0, 0], 8000));
// server を起動
axum::Server::bind(&addr)
.serve(app.into_make_service())
.await
.unwrap();
};
tokio::join!(server);
}
ここで、定義していないエンドポイントにリクエストが来たときに 404 である旨を伝えるミドルウェアを追加しましょう。
+ async fn notfound_handler() -> impl IntoResponse {
+ (StatusCode::NOT_FOUND, "not found")
+ }
これを、main 関数内で呼びます。
+ let app = app.fallback(notfound_handler.into_service());
GraphQL では、単一のエンドポイントからリクエストをもらうため、これでエンドポイントの定義は完了です。
一度、playground が正常に起動するかを確かめます。
cargo run
正しく起動ができました。
エラーハンドリング
resolver, database connection を定義する前に、エラー処理を定義します。
大きく分けて、3つのエラーを扱う方向でいきます。
- ブログ詳細ページにて、存在しない主キーにアクセスした場合に出すエラー(404)
- ブログ投稿一覧ページにて、投稿がないときに出すエラー(404)
- 環境変数が存在しない、コネクションが弾かれた等のデータベースの接続に失敗したエラー(500)
上記の3パターンを、Result 型で捌くための enum を定義します。
#[derive(Debug, Error)]
pub enum BlogError {
#[error("投稿が存在しません")]
NotFoundPost,
#[error("投稿が存在しません")]
NotFoundPosts,
#[error("ServerError")]
ServerError(String),
}
これで、3つのエラーを表現することができるようになりました。
ServerError のみ、パターンがいくつかあるのでその都度テキストを入力できるようにしています。
これらを使って、resolver/database connection を実装していきます。
データベースアクセスを定義する
次に、実際にリソースにアクセスするためにデータベースアクセスを定義します。
データベースは RDS 上にあり、自分が個人ブログの投稿を始めた2年半前くらいからずっと動いています。ローカルからもプロダクションからもそこにアクセスするようにします。
余談ですが、料金が高いので Aurora serverless か、他のプラットフォームへの乗り換えを検討しています。
コネクションを確立する関数
まずは、コネクションを張る関数を定義します。
コネクションを確立する関数は、エラーのパターンが2つあります。
- 環境変数がなかった場合
- コネクションが張れなかった場合
それぞれを捌き、エラーの場合は上で定義したエラーを返すような形にします。
async fn pool () -> Result<MySqlPool, BlogError> {
let url = match env::var("DATABASE_URL") {
Ok(url) => url,
Err(_) => {
return Err(BlogError::ServerError("DATABASE_URL is not set".to_string()));
}
};
let pool = MySqlPool::connect(&url).await;
match pool {
Ok(pool) => Ok(pool),
Err(e) => Err(BlogError::ServerError(e.to_string())),
}
}
投稿一覧を取得する
次に、上で定義したコネクションの関数を利用して、必要なリソースを取得する関数を定義します。
ここでは、現在のページと、カテゴリを引数として受け取り、ページからオフセットを求め、カテゴリを用いてカテゴリ検索を行い、クエリを実行して戻り値を返します。
最後に match で値かエラーを返すようにしていますが、fetch_all 関数は1件も該当するレコードがない場合でもエラーを吐かないので、ここで拾うエラーは NotFound ではなく未知のエラーになります。
// 投稿の struct
// category 以外はテーブルと一致している(category は FK が入るので JOIN して得た値を入れる前提)
#[derive(SimpleObject)]
#[derive(sqlx::FromRow)]
pub struct Post {
id: i32,
title: String,
category: Option<String>,
contents: Option<String>,
pub_date: DateTime<Utc>,
open: i8,
}
pub async fn get_posts(page: i32, category: String) -> Result<Vec<Post>, BlogError> {
let pool = match pool().await {
Ok(pool) => pool,
Err(_) => return Err(BlogError::ServerError("Database Error: connection failed".to_string())),
};
// オフセットを求める
let offset = if page == 0 { 0 } else { 5 * (page - 1) };
// カテゴリがなかったら where は入れない
let category_query = if category == "" {
format!("{}", "")
} else {
format!("AND blogapp_category.name = '{}'", category)
};
let sql = format!(
"
SELECT
blogapp_post.id,
title,
blogapp_category.name as category,
left(contents, 200) as contents,
pub_date,
open
FROM
blogapp_post
INNER JOIN
blogapp_category
ON
blogapp_post.category_id = blogapp_category.id
WHERE
open = true
{}
ORDER BY
blogapp_post.pub_date desc
LIMIT 5
OFFSET ?
",
category_query
);
// query_as で Post 型にマッピングしている
let posts = sqlx::query_as::<_, Post>(
sql.as_str(),
)
.bind(offset)
.fetch_all(&pool)
.await;
match posts {
Ok(posts) => Ok(posts),
// fetch_all は該当するレコードがなくてもエラーを吐かない
// つまりここで拾うべきは想定していない未知のエラー
Err(_) => Err(BlogError::ServerError("unknown error".to_string())),
}
}
投稿詳細を取得する
次に、投稿一覧と同様に投稿詳細を取得する関数も定義します。
先ほどと違う場所は、 fetch_one は fetch_all と違って該当するレコードがない場合はエラーを返します。
最後にそれを NotFound のエラーとして拾ってあげます。
pub async fn get_post(id: i32) -> Result<Post, BlogError> {
let pool = match pool().await {
Ok(pool) => pool,
Err(_) => return Err(BlogError::ServerError("Database Error: connection failed".to_string())),
};
let post = sqlx::query_as::<_, Post>(
r#"
SELECT
blogapp_post.id as id,
title,
blogapp_category.name as category,
contents,
pub_date,
open
FROM
blogapp_post
INNER JOIN
blogapp_category
ON
blogapp_post.category_id = blogapp_category.id
WHERE
blogapp_post.id = ?
"#,
)
.bind(id)
.fetch_one(&pool)
.await;
match post {
Ok(post) => Ok(post),
// fetch_one はリソースが見つからない場合にエラーになる
// そのため、ここで拾うのは NotFound
Err(_) => Err(BlogError::NotFoundPost),
}
}
これで投稿一覧と投稿詳細のそれぞれにアクセスする関数を定義することができました。
resolver を定義する
次に、resolver を定義していきます。
今回は、以下のようなクエリが飛んでくることを想定しています。
※スキーマ定義は書いてないのでないです...。
# 投稿一覧
query postsQuery($pages: Int, $category: String) {
getPosts(page: $pages, category: $category) {
current
next
previous
category
last
results {
id
title
contents
category
pub_date
}
}
}
# 投稿詳細
query postQuery($id: Int) {
getPost(id: $id) {
id
title
contents
pub_date
category
}
}
QueryRoot の定義
async-graphql では QueryRoot というトレイトを介してリクエストを捌きます。
async_graphql::Object マクロを使用して定義を行います。
また、ここで定義する関数の名前がそのままクエリの名前になります。
例えば、以下のようなクエリを定義します。
#[derive(SimpleObject)]
#[derive(sqlx::FromRow)]
struct Ping {
status: String,
code: i32,
}
#[Object]
impl QueryRoot {
async fn ping(&self) -> Ping {
Ping {
status: "ok".to_string(),
code: 200
}
}
}
そうすると、このような形でクエリを投げることができるようになります。

この調子で resolver を定義していきます。
投稿一覧を取得する
投稿一覧を取得する resolver を定義します。
クエリの引数として、ページネーションで現在のページを示すための page と、カテゴリで絞りたい場合に指定する category という2つの引数を取ります。
それぞれの引数は、先ほど上で定義した get_posts 関数に渡され、ほしいリソースが返ってきて、それを Posts 型にマッピングしてクライアントに返します。
また、処理の途中でいくつかエラーになるポイントが存在します。
- 公開済みの投稿の数が0件の時
- 該当する投稿が0件の時(1に付随する)
- ページ数が全体のページ数を超えている時
上記のそれぞれを、パターンマッチで弾いてあげます。
また、resolver で発生するエラーは、データベース側で発生するエラーも吸収したいので、以下のようにエラーだったらさらにエラーを拾うようなパターンマッチをするようにしています。正直 Rust 初心者でこのエラー処理が正しい自信がないので、有識者の方やもっとスマートに書ける方法があるという方はコメントをいただけると嬉しいです。
// エラーの中のエラーの例
match hoge {
// 正常
Ok(hoge) => hoge,
// エラーの際にはさらにエラーを分解する
Err(err) => return Err(
match err {
// リソースがない
BlogError::NotFoundPosts => FieldError::new(
"投稿がありません".to_string(),
),
// server error
BlogError::ServerError(message) => FieldError::new(
message.to_string(),
),
// 未知のエラー
_ => FieldError::new("unknown error".to_string()),
},
),
};
最終的な関数は以下のようになります。
// 戻り値用
#[derive(SimpleObject)]
pub struct Posts {
current: i32,
next: Option<i32>,
prev: Option<i32>,
category: String,
page_size: i32,
results: Vec<Post>,
}
#[Object]
impl QueryRoot {
#[allow(non_snake_case)]
async fn getPosts(
&self,
_ctx: &Context<'_>,
#[graphql(desc = "current page")] page: i32,
#[graphql(desc = "selected category")] category: String
) -> FieldResult<Posts> {
let page = if page == 0 { 1 } else { page };
let categoryForResult = category.clone();
// count は公開済みの投稿の数を取得する関数
let count = match count().await {
Ok(count) => match count {
// 1. 公開済みの投稿の数が0件の時
0 => return Err(BlogError::NotFoundPosts.into()),
_ => count,
},
Err(err) => return Err(
match err {
BlogError::ServerError(message) => FieldError::new(
message.to_string(),
),
_ => FieldError::new("unknown error".to_string()),
},
),
};
let posts = get_posts(page, category).await;
let results = match posts {
Ok(posts) => posts,
// 2. 該当する投稿が0件の時(1に付随する)
Err(err) => return Err(
match err {
BlogError::NotFoundPosts => FieldError::new(
"投稿がありません".to_string(),
),
BlogError::ServerError(message) => FieldError::new(
message.to_string(),
),
_ => FieldError::new("unknown error".to_string()),
},
),
};
let page_size = (count / 5) + 1;
// 3. ページ数が全体のページ数を超えている時
match page > page_size {
true => return Err(BlogError::NotFoundPosts.into()),
_ => (),
}
let next = if page == page_size { Some(page_size) } else { Some(page + 1) };
let prev = if page == 0 { Some(0) } else { Some(page - 1) };
// Posts 型にマッピングして戻す
Ok(Posts {
current: page,
next,
prev,
category: categoryForResult,
page_size,
results,
})
}
}
投稿詳細を取得する
次に、投稿詳細を取得する resolver を定義します。
投稿一覧の resolver ほど細かくエラーを拾う必要はなく、データベースにアクセスして取得した値をそのままクライアントに流すだけの関数になります。
エラーのパターンは
- データベース側で吐かれた NotFound を拾う
- コネクションまわりで吐かれた ServerError を拾う
- 未知のエラーを拾う
の3パターンですが、特に意識することはないのでそのまま定義すると勝手に拾われるようになります。
最終的な関数は以下のようになります。
impl QueryRoot {
#[allow(non_snake_case)]
async fn getPost(
&self,
_ctx: &Context<'_>,
#[graphql(desc = "id of the post")] id: i32,
) -> FieldResult<Post> {
let post = get_post(id).await;
match post {
Ok(post) => Ok(post),
Err(err) => Err(
match err {
BlogError::NotFoundPost => FieldError::new(
"投稿が存在しません".to_string(),
),
BlogError::ServerError(message) => FieldError::new(
message.to_string(),
),
_ => FieldError::new("unknown error".to_string()),
},
),
}
}
}
これで resolver の定義も完了しました。
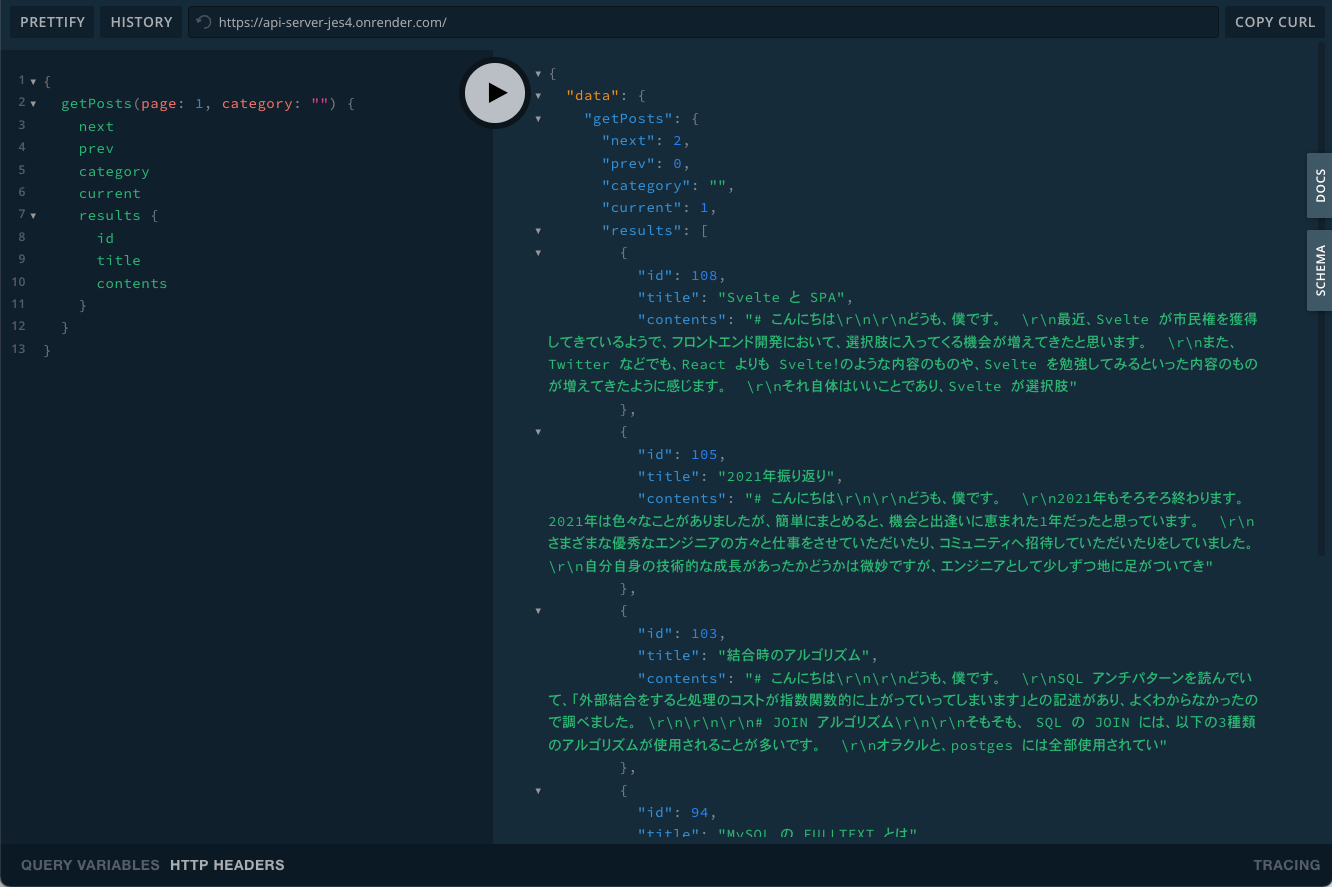
この状態で playground で色々実行することができます。
例えば投稿一覧はこのような形で取得することができます。
存在しないページネーションを指定した場合はこのような形になります。

感想
Rust に入門してみて、いくつか感じたことを書きます。
Result 型と Option 型がいい
Option 型は取得できないかもしれない値を、Result 型は失敗するかもしれない値を処理するためのものですが、これが非常に使いやすいなと感じました。
これらで拾った値をパターンマッチで拾うことにより、Null が存在しない世界線を実現してくれます。
所有権といい、Null を Option で拾えることといい、Rust の安全性を感じることができました。
パターンマッチがいい
パターンマッチがいいと感じたことは、大きく分けて2つあります。
1つは他言語で switch 文として表されるものが match という式で表現できること、もう1つはそのパターンマッチの型の表現が強いということです。
match 式
自分がこれまで触ってきた言語の多くが、任意の値をもとに複数の条件に分岐をしたい場合には swtich という文が存在していました。自分が業務で主に用いている TypeScript や PHP も例外ではなく、複数の条件に分岐するような文として扱われてきました。
しかし、Rust の場合、任意の値をもとに複数の条件に分岐をしたい場合には match という式によって表現されます。自分がプログラムを書いている時、switch 文に戻り値が欲しくなる時があります。場合によりますが、TypeScript だったら let で変数を宣言して、マッチしたら再代入してということを書きます。それを式として表現できることに嬉しさを感じました。
パターンマッチの型が強力
上記でパターンマッチが式で表現できることを挙げましたが、さらにパターンマッチは型が同じであれば一致します。例えば Option をマッチさせようとした時、値があればSome となり、存在しなかったら None となるような型もマッチさせることができます。
上記のあたりに Rust の嬉しさを感じました。
まとめ
あまり設計とかを考えずに、とりあえず入門として始めたのでモジュールの管理がだいぶ雑ですが、とりあえず動くものを作ることができ、Rust の理解も深まったので良かったと感じています。
世の中にはすでに Rust で動いてるものがたくさんあり、自分もそういったものに興味があるので今後どんどん掘っていけるようにしたいです。
また、隙があれば業務でも使用していこうと思います。
Discussion