Athenaのパーティションとは
はじめに
この記事は、Amazon Athenaのパーティションについて解説する記事です。
また私はAWS初心者なので間違った情報などがあると思われます。その際はコメントなどで修正をしていただけると嬉しいです。
パーティションとは
まずパーティションについて、パーティションとは、S3などのディレクトリの切り方においてある規則のあるディレクトリ構成することです。
例えば、日付などのカテゴリーの列でデータを分けることです。以下の図が日付でパーティションしたものです。
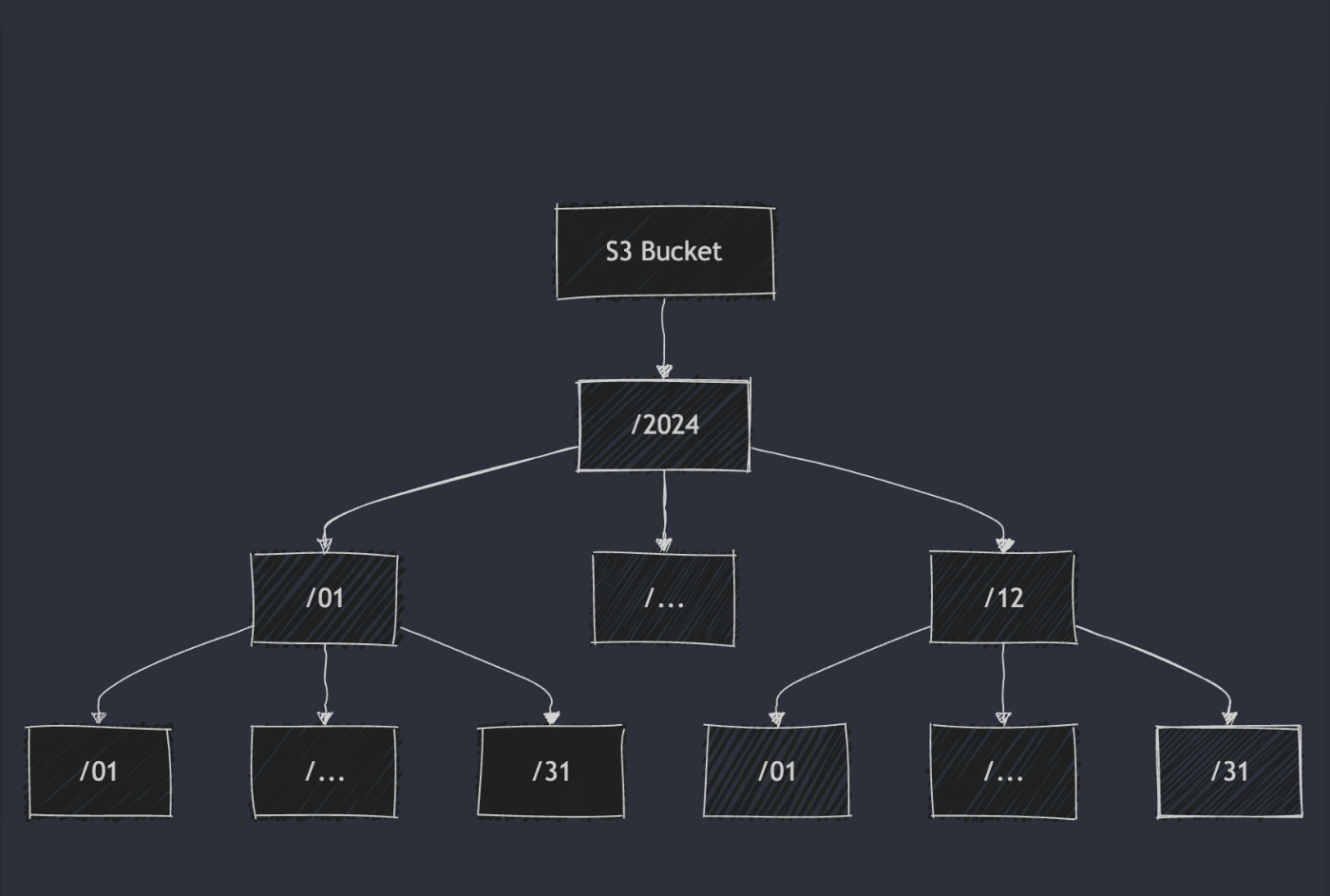
上の図は指定したBucketにおいて年、月、日のフォルダでパーティション化しているものです。
簡単にいうとフォルダ分けしていればパーティション化されているものと考えていいと思ってます。
Athenaにおけるパーティションとは?
S3上でパーティションが切ってあっても、Athenaにおけるパーティションを切っておかないとクエリを叩く際にはフルスキャンしてからWHEREをかけるのでその分、料金と時間がかかります。
これを回避するために、Athena上でパーティションを定義してあげて先にスキャンする範囲を絞ってあげることで、回避できます。
Athena上でパーティションを切るメリットについて
主に以下の2つあります。
- コスト削減
- パフォーマンス(検索速度)の向上
これらの要因はどちらも共通していて、パーティションのキーを条件として指定して検索するため、条件外のものに探索をかけないためスキャンデータ量が下がり、コストも下がり、無駄なファイルに探索をかけないので速度も上がります。
パーティション化の2つの方法
主に以下の2つがある。
- Hive形式
- Hiveじゃない形式
まず、Hive型について、"key = value"の状態になっていたらHive形式です。って言われてもわからないですね。具体例を出します。
例
s3://log/year=2024/mounth=10/day=16/time=2323/
のように変数に値を当てはめている感じで表示しているのがHive形式です。
次に、Hiveじゃない形式についてですが、お察しのいい人はもうわかると思います。
変数がなくそのまま値だけのやつです。以下が例です。
例
s3://log/2024/10/16/2323/
HiveとHiveじゃない形式の相違点
Hiveであると、パーティション(フォルダ)が追加される度にテーブルの再読み込みを実行してあげないと追加されたパーティションを検索できません。
そのため、時間が経過すると同時にファイルが増えていく系の構成にしている場合はHiveじゃない形式のほうがいいです。
まとめ
今回は、Athenaのパーティションについて説明しました。これらは実際にS3上のビッククエリなどの際に検索速度向上やコスト削減に直接つながるものなので十二分に理解して活用してください!
著者について
takumi0706です。エンジニアになりたい人でして、現在はバックエンド開発(フロントもちょっと)に注力しています。技術的な挑戦を続ける中で学んだことをアウトプットすることをなるたけ努力してます。
- ポートフォリオサイト: takumi0706.simple.ink
- GitHub: takumi0706
- X(旧Twitter): @1ye_q
これからも技術的な知見を深め、共有していくことを目指していますので、ぜひフォローやフィードバックをお寄せください。

takumi0706
Discussion