CloudTrailを利用したセキュリティ強化 〜Partition構成の検討
はじめに
この記事は、CloudTrailのログをどのように扱っていくかにおいてAthenaを使用する際に検索を楽にするためのPartition構成を検討かつ検証したものです。
TL;DR
Athenaでログ検索するならPartition必須
ユースケース
具体的なシナリオ:特定のユーザーに対して行う、そのユーザーがどのようにして作られてきたのか、→アカウントベースの管理、アカウントの特定も欲しい。
探索フロー:そのアクションに対して誰がやったのか→いつ行ったのか。→詳細
検討Athenaパーティション構成
- region, year, mouth, week, account?
- dayのログ量が少ない(定量的ではないが、今後の検証[速度, コスト]で判断)ならweekでパーティションを切る
- region, year, mouth, day, account?
- dayのログ量が多いなら、dayで管理
上記の2つの懸念点
- accountで切れるのか?->Organizationで行ける!
- 切りすぎるとSQLの際にWHERE句に全部入れなきゃいけない。(まあちゃんとdocを作ればいい話か。)
S3環境のパーティション構成
S3バケット
└ AWSLogs
└ Organization ID
└ (AWSアカウントID)
└ CloudTrail
└ AWSリージョン
└ 日付 (yyyy/mm/dd)
動作確認のAthenaパーティション構成
[AccountId, AWSRegion, Date(yyyy/mm/dd)]
以下が実行予定のSQLです。
[CloudTrail用S3バケット名] と [Organizational ID] は適宜書き換えてください。
CREATE EXTERNAL TABLE IF NOT EXISTS `sample_cloudtrail`.`partitioned_table` (
`eventversion` string,
`useridentity` STRUCT <
type: STRING,
principalid: STRING,
arn: STRING,
accountid: STRING,
invokedby: STRING,
accesskeyid: STRING,
userName: STRING,
sessioncontext: STRUCT <
attributes: STRUCT <
mfaauthenticated: STRING,
creationdate: STRING
>,
sessionissuer: STRUCT <
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING
>,
ec2RoleDelivery: string,
webIdFederationData: map <
string,
string >
>
>,
`eventtime` string,
`eventsource` string,
`eventname` string,
`awsregion` string,
`sourceipaddress` string,
`useragent` string,
`errorcode` string,
`errormessage` string,
`requestparameters` string,
`responseelements` string,
`additionaleventdata` string,
`requestid` string,
`eventid` string,
`resources` array <
STRUCT <
arn: STRING,
accountid: STRING,
type: STRING
>
>,
`eventtype` string,
`apiversion` string,
`readonly` string,
`recipientaccountid` string,
`serviceeventdetails` string,
`sharedeventid` string,
`vpcendpointid` string,
`tlsDetails` struct <
tlsVersion: string,
cipherSuite: string,
clientProvidedHostHeader: string
>
)
PARTITIONED BY (region string, date string, accountid string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = '2023/01/01,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'projection.region.type' = 'enum',
'projection.region.values'='us-east-1,us-east-2,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1',
'projection.accountid.type' = 'injected',
'storage.location.template' = 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/${accountid}/CloudTrail/${region}/${date}',
'classification'='cloudtrail',
'compressionType'='gzip',
'typeOfData'='file',
'classification'='cloudtrail'
);
Athena上で実行時Log
まず、DB作成
CREATE DATABASE test_cloudtrail_logs
パーティションありのテーブル
CREATE EXTERNAL TABLE IF NOT EXISTS `test_cloudtrail_logs`.`partitioned_table` (
`eventversion` string,
`useridentity` STRUCT <
type: STRING,
principalid: STRING,
arn: STRING,
accountid: STRING,
invokedby: STRING,
accesskeyid: STRING,
userName: STRING,
sessioncontext: STRUCT <
attributes: STRUCT <
mfaauthenticated: STRING,
creationdate: STRING
>,
sessionissuer: STRUCT <
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING
>,
ec2RoleDelivery: string,
webIdFederationData: map <
string,
string >
>
>,
`eventtime` string,
`eventsource` string,
`eventname` string,
`awsregion` string,
`sourceipaddress` string,
`useragent` string,
`errorcode` string,
`errormessage` string,
`requestparameters` string,
`responseelements` string,
`additionaleventdata` string,
`requestid` string,
`eventid` string,
`resources` array <
STRUCT <
arn: STRING,
accountid: STRING,
type: STRING
>
>,
`eventtype` string,
`apiversion` string,
`readonly` string,
`recipientaccountid` string,
`serviceeventdetails` string,
`sharedeventid` string,
`vpcendpointid` string,
`tlsDetails` struct <
tlsVersion: string,
cipherSuite: string,
clientProvidedHostHeader: string
>
)
PARTITIONED BY (region string, date string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = '2024/10/01,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'projection.region.type' = 'enum',
'projection.region.values'='us-east-1,us-east-2,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1',
'projection.accountid.type' = 'injected',
'storage.location.template' = 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/CloudTrail/${region}/${date}',
'classification'='cloudtrail',
'compressionType'='gzip',
'typeOfData'='file',
'classification'='cloudtrail'
);
パーティションなしのテーブル作成
CREATE EXTERNAL TABLE IF NOT EXISTS `test_cloudtrail_logs`.`non_partitioned_table` (
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
username: STRING>,
ec2RoleDelivery: STRING,
webIdFederationData: MAP<STRING,STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
readOnly STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING,
tlsDetails STRUCT<
tlsVersion: STRING,
cipherSuite: STRING,
clientProvidedHostHeader: STRING>
)
COMMENT 'CloudTrail table for drecom-developer-log bucket'
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/CloudTrail/'
TBLPROPERTIES (
'projection.date.range' = '2024/10/01,NOW',
'classification'='cloudtrail'
);
以下の画像のようにパーティションありとなしができた。
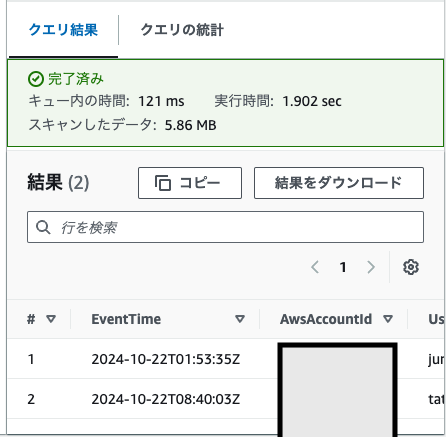
パーティションなしでの探索クエリ
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName as UserRole,
responseElements AS LoginStatus
FROM non_partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' AND
eventname = 'ConsoleLogin' AND
eventtime >= '2024-10-22T00:00:00Z' AND
eventtime < '2024-10-23T00:00:00Z' AND
awsregion = 'ap-northeast-1';

やはり、遅いしスキャン量が多い。
次にパーティションありでの探索クエリ
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName AS UserRole,
responseElements AS LoginStatus
FROM partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' and
eventname = 'ConsoleLogin' and
date = '2024/10/22' and
region = 'ap-northeast-1';
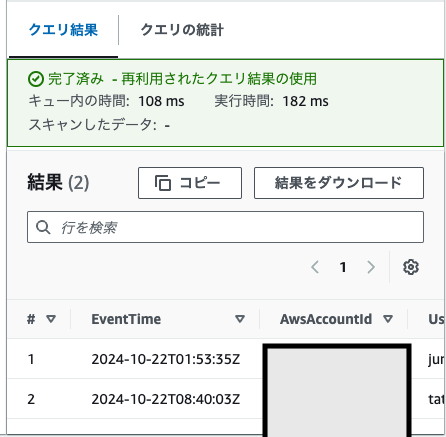
パーティションなしよりは断然早いし、量も少ない。
しかし、私的な感覚としては、スキャン量が多い気がする。→多分だが、Locationの指定ミス?OrganizationIdまでしか指定していない、CloudTrailまで指定してみる。
以下でpartitioned_table再作成する
CREATE EXTERNAL TABLE IF NOT EXISTS `test_cloudtrail_logs`.`partitioned_table` (
`eventversion` string,
`useridentity` STRUCT <
type: STRING,
principalid: STRING,
arn: STRING,
accountid: STRING,
invokedby: STRING,
accesskeyid: STRING,
userName: STRING,
sessioncontext: STRUCT <
attributes: STRUCT <
mfaauthenticated: STRING,
creationdate: STRING
>,
sessionissuer: STRUCT <
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING
>,
ec2RoleDelivery: string,
webIdFederationData: map <
string,
string >
>
>,
`eventtime` string,
`eventsource` string,
`eventname` string,
`awsregion` string,
`sourceipaddress` string,
`useragent` string,
`errorcode` string,
`errormessage` string,
`requestparameters` string,
`responseelements` string,
`additionaleventdata` string,
`requestid` string,
`eventid` string,
`resources` array <
STRUCT <
arn: STRING,
accountid: STRING,
type: STRING
>
>,
`eventtype` string,
`apiversion` string,
`readonly` string,
`recipientaccountid` string,
`serviceeventdetails` string,
`sharedeventid` string,
`vpcendpointid` string,
`tlsDetails` struct <
tlsVersion: string,
cipherSuite: string,
clientProvidedHostHeader: string
>
)
PARTITIONED BY (region string, date string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/CloudTrail/' #変更点:[Organizational ID]/ → [Organizational ID]/CloudTrail/
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = '2024/10/01,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'projection.region.type' = 'enum',
'projection.region.values'='us-east-1,us-east-2,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1',
'projection.accountid.type' = 'injected',
'storage.location.template' = 's3://[CloudTrail用S3バケット名]/AWSLogs/[Organizational ID]/CloudTrail/${region}/${date}',
'classification'='cloudtrail',
'compressionType'='gzip',
'typeOfData'='file',
'classification'='cloudtrail'
);
以下の探索クエリを叩き直す。
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName AS UserRole,
responseElements AS LoginStatus
FROM partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' and
eventname = 'ConsoleLogin' and
date = '2024/10/22' and
region = 'ap-northeast-1';
めちゃめちゃ早くなったわ。やっぱLocationの指定が間違ってた。
以下に比較結果をまとめておく!
レッツ比較
比較条件
AWSアカウントの東京リージョン(ap-northeast-1)で、2024年10月23日に発生したサインインのログを検索します(IAM Identity Center によるシングルサインオンを使用していますので、そのログを取得しています)。
また、パーティション化させている部分としては2024年10月01日からにしております。
パーティションなしのクエリ
以下のクエリを実行します。
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName as UserRole,
responseElements AS LoginStatus
FROM non_partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' AND
eventname = 'ConsoleLogin' AND
eventtime >= '2024-10-22T00:00:00Z' AND
eventtime < '2024-10-23T00:00:00Z' AND
awsregion = 'ap-northeast-1';
パーティションありのクエリ
以下のクエリを実行します。
WHERE句でパーティション化した属性を指定しています。
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName AS UserRole,
responseElements AS LoginStatus
FROM partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' AND
eventname = 'ConsoleLogin' AND
date = '2024/10/22' AND
region = 'ap-northeast-1';
結果
以下にパーティションあり、パーティションなしのクエリ結果を表示する。
パーティションなしのクエリ結果
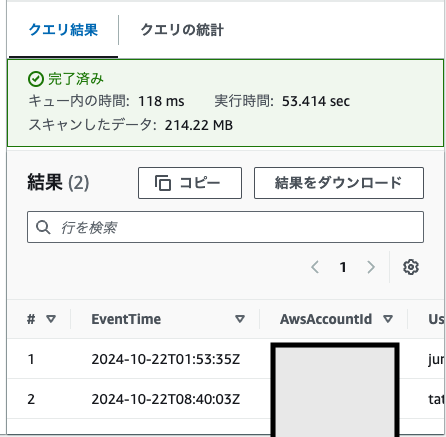
クエリの実行時間は 約1分、スキャンしたデータ量は 214.22MB となりました。ちなみに実行時のS3バケットのデータ量は 約250MB でしたので、ほぼ全データがスキャンされたことになります。
Athenaはスキャンしたデータ量に応じた従量課金で、S3のデータ量が増えていくにつれ利用料が嵩むことになる!(1TBにつき5.00USDの課金)。さらにクエリの実行時間も長くなりストレスフル。
パーティションありのクエリ結果
帰ってきた結果はパーティションなしと同じなので、期待通りです。
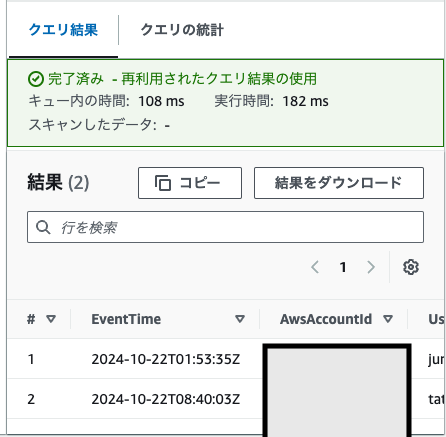
一方、実行時間としては0.182秒、スキャンしたデータ量は小さすぎて?表示されてないですね。パーティション化によって制限したため量が格段に減っているのでコスト削減に貢献しており、速度も格段に早くなっていますね。
まとめ
結果
検証結果としては、パーティションなしとありでは格段に速度とコスト面が違うことが判明。
速度面に対してはなしに対してありは最大で10分の1の速さで実行可能
コスト面に関しては最大で2分の1のコストで実行可能
利点
- セキュリティ強化:不正操作の早期検知やトラブル発生時の原因究明の迅速化
- コスト削減:パーティションを適切に設計することでAthenaのクエリコストを最小限に抑える
- 可視性向上:組織全体でどのユーザーがどのリソースにアクセスしているかを一元的に可視化
詳細
これらの結果に対して速度面に関して、検証中の実感でパーティションなしで行うと大抵1分〜の待ち時間がありとてもロスであった。それに対してアリの場合だと10秒以内にクエリを終了するためとても快適でかつ迅速であることがわかった。またコスト面も早さからわかる通りパーティションを切っているため全てをロードぜす指定部分だけロードしてから検索するためとても安く済むこともわかった(*Athenaは1TB探索すると5.00USDかかる)
おまけ
単一の日にちではなく複数の日にちでのクエリを追記しておきます。
単一の日にちではなく期間で検索する方法
以下のようにすると2024/10/01~2024/10/22の期間で検索をかけることが可能である。
SELECT
eventtime AS EventTime,
useridentity.accountid AS AwsAccountId,
regexp_extract(useridentity.arn, '([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})', 1) AS UserName,
useridentity.sessioncontext.sessionissuer.userName AS UserRole,
responseElements AS LoginStatus
FROM partitioned_table
WHERE
eventsource = 'signin.amazonaws.com' and
eventname = 'ConsoleLogin' and
date between'2024/10/01' and '2024/10/22' and
region = 'ap-northeast-1';
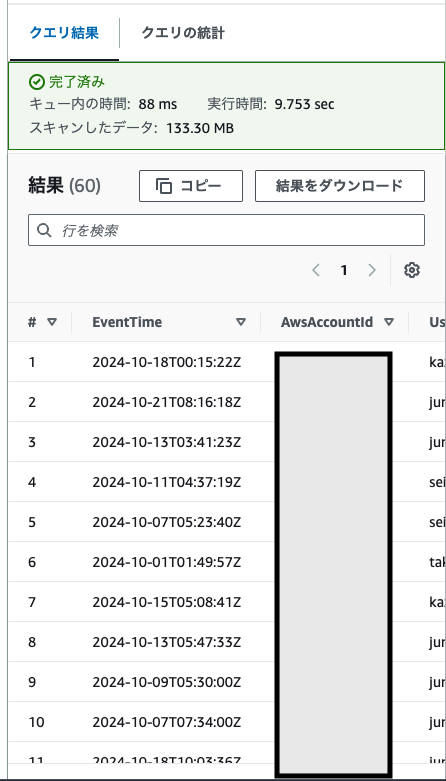
以上のように期間での検索が可能である。またスキャン量は133.30MBだが、これはS3上の10月のデータ量を一致している。
参考サイト:
著者について
takumi0706です。エンジニアになりたい人でして、現在はバックエンド開発(フロントもちょっと)に注力しています。技術的な挑戦を続ける中で学んだことをアウトプットすることをなるたけ努力してます。
- ポートフォリオサイト: takumi0706.simple.ink
- GitHub: takumi0706
- X(旧Twitter): @1ye_q
これからも技術的な知見を深め、共有していくことを目指していますので、ぜひフォローやフィードバックをお寄せください。

takumi0706
Discussion