うさぎでもわかる最新リップシンクOSS技術 - 歌ってみた動画を作るための高精度ツール比較
うさぎでもわかる最新リップシンクOSS技術
👇️PodCastでも聴けます
こんにちは、🐰です!今日は「歌ってみた動画を作るための最新リップシンク技術」について紹介するよ!
「歌ってみた動画を作りたいけど、口の動きが合わなくて不自然...」
「高品質なリップシンク技術って何があるの?」
「オープンソースで使えるツールを教えて欲しい!」
そんな疑問にお答えします!最近のAI技術の進歩により、リップシンク(口の動きと音声を同期させる技術)は驚くほど進化しています。今回は2025年現在、最も精度が高いオープンソースのリップシンク技術を比較して紹介します。
リップシンクとは?
リップシンク(Lip Synchronization)とは、映像内の人物の口の動きと音声を同期させる技術です。従来は映画やアニメーションの吹き替えなどで手作業で行われていましたが、AI技術の発展により、自動化されたツールが次々と登場しています。
リップシンクが重要な理由は単純です。人間の脳は、聞こえる音声と見える口の動きが一致していないと、違和感を覚えるようにできているからです。高品質なリップシンクは、視聴者に自然で没入感のある体験を提供します。
リップシンクの主な応用分野
- 歌ってみた動画作成: 自分の歌声に合わせて口元を動かす
- 動画のローカライズ: 外国語の動画を翻訳した音声に合わせて口の動きを調整
- バーチャルアバター/VTuber: リアルタイムの音声に合わせてキャラクターの口を動かす
- 映画/アニメ制作: アニメーションキャラクターの口の動きを音声に合わせる
- 教育コンテンツ: 学習ビデオの多言語対応
今回は特に、オープンソースで利用できる最新の高精度リップシンク技術に焦点を当てていきます。
リップシンク技術の基礎
最新のAIリップシンク技術を理解するためには、基本的な仕組みを知っておくことが大切です。ここでは、現代のリップシンク技術の中核となる要素を解説します。
基本的な処理フロー
一般的なAIリップシンク処理は、以下のようなステップで行われます:
- 音声解析: 入力された音声を解析して、フォニーム(言語の最小音韻単位)に分解します
- フェイシャルトラッキング: 元の映像から口や顔の特徴点を検出・追跡します
- マッピング: 音声のフォニームと口の形状(ビジーム)を対応付けます
- 生成/合成: 音声に合わせて新しい口の動きを生成し、元の映像に合成します
従来の方法との違い
リップシンク技術は大きく進化してきました:
- 従来の手法: 手動アニメーションや基本的なルールベースのマッピング
- 初期のAI手法: GAN(敵対的生成ネットワーク)を使用した生成モデル(例: Wav2Lip)
- 最新のAI手法: 拡散モデル(Diffusion Models)やニューラルレンダリングを活用した高精度技術
評価指標
リップシンクの品質を評価するために、いくつかの重要な指標が使われています:
- SyncNet: リップシンクの精度を評価する標準的な指標
- LSE-C & LSE-D: SyncNetベースの信頼性と距離スコア
- LMD (Mouth Landmark Distance): 口の形状の正確さを評価
- TREPA (Temporal Representation Alignment): 時間的一貫性を評価する新しい指標
これらの指標を用いて、各ツールのパフォーマンスが科学的に評価されています。
2025年の最新OSSリップシンク技術
ここからは、2025年現在で利用可能な最新のオープンソースリップシンク技術を紹介します。各ツールの特徴や長所・短所を比較して、あなたの目的に合ったツールを見つける手助けをします。
LatentSync

開発元: ByteDance (TikTokの親会社)
最新バージョン: 1.5 (2025年3月14日リリース)
GitHub: bytedance/LatentSync
ByteDanceが開発した最新のリップシンク技術で、2025年現在で最も高精度なOSSリップシンクツールと評価されています。
主な特徴:
- 拡散モデルベースの端末間リップシンクフレームワーク
- 中間的な3D表現を必要としない直接生成アプローチ
- 時間表現アライメント技術(TREPA)による時間的一貫性の向上
- Stable Diffusionの機能を活用した複雑な視聴覚関係のモデリング
バージョン1.5の改良点:
- 時間層の追加による時間的一貫性の向上
- 中国語動画に対するパフォーマンスの改善
- ステージ2トレーニングのVRAM要件を20GBに削減
長所:
- 現在最も高い精度のリップシンク品質
- フレームジッタリング(ちらつき)の問題を解決
- 高解像度のリップシンクに対応
- 総合的なビデオ処理ツールチェーンを提供
短所:
- 比較的高いハードウェア要件(20GB VRAM推奨)
- セットアップがやや複雑
- トレーニングデータの解像度制限(256x256)による出力の詳細損失
Wav2Lip

開発元: 研究者グループ
GitHub: Rudrabha/Wav2Lip
Wav2LipはAIリップシンク分野の先駆的なプロジェクトで、今でも広く使われているベースライン技術です。
主な特徴:
- 音声入力からリアルな口の動きを生成
- GANベースのディープラーニングアーキテクチャ
- 高精度のリップシンク、特に英語音声に対して
長所:
- 比較的低いハードウェア要件
- 豊富なコミュニティサポートと多数の派生プロジェクト
- インストールと使用が比較的簡単
短所:
- 顔の表情や頭の動きの欠如(口のみに焦点)
- 時間的一貫性の問題が発生することがある
- 最新の拡散モデルベースのツールと比較して品質が劣る
SadTalker

開発元: 研究者グループ
GitHub: OpenTalker/SadTalker
SadTalkerは、より自然な表情と頭の動きを実現するために開発されたリップシンクツールです。
主な特徴:
- 単一画像から頭の動きと表情を含むトーキングフェイスアニメーションを生成
- 3Dフェイスモデルを使用した自然な頭の動き
- 口だけでなく、顔全体の表情も生成
長所:
- 自然な頭の動きと表情を生成
- 単一の画像からアニメーションを生成可能
- アーティスティックな表現が可能
短所:
- Wav2Lipと比較してリップシンクの精度がやや劣ることがある
- リソース消費が大きい
- 特定の顔のポーズや角度に制限がある
OmniHuman-1

開発元: ByteDance
発表: 2025年2月
OmniHuman-1は、単一の人物画像と音声から、リップシンクとジェスチャーを含む完全な人物動画を生成できる最新技術です。
主な特徴:
- 1枚の静止画像と音声入力から完全な人物動画を生成
- 高精度なリップシンクだけでなく、複雑なジェスチャーも生成
- 音声に適した表情や体の動きを生成
長所:
- 最も総合的な動画生成能力
- 自然なジェスチャーと身体動作
- 入力要件が最小限(1枚の画像と音声のみ)
短所:
- 最も高いハードウェア要件
- 現時点では完全なオープンソース実装がまだ限定的
- 処理に時間がかかる
最高精度のOSSリップシンクツール「LatentSync」詳細紹介
調査の結果、現時点で最も高精度なオープンソースリップシンク技術は「LatentSync」であることがわかりました。ここでは、より詳しくその仕組みとセットアップ方法を紹介します。
LatentSyncの技術的仕組み
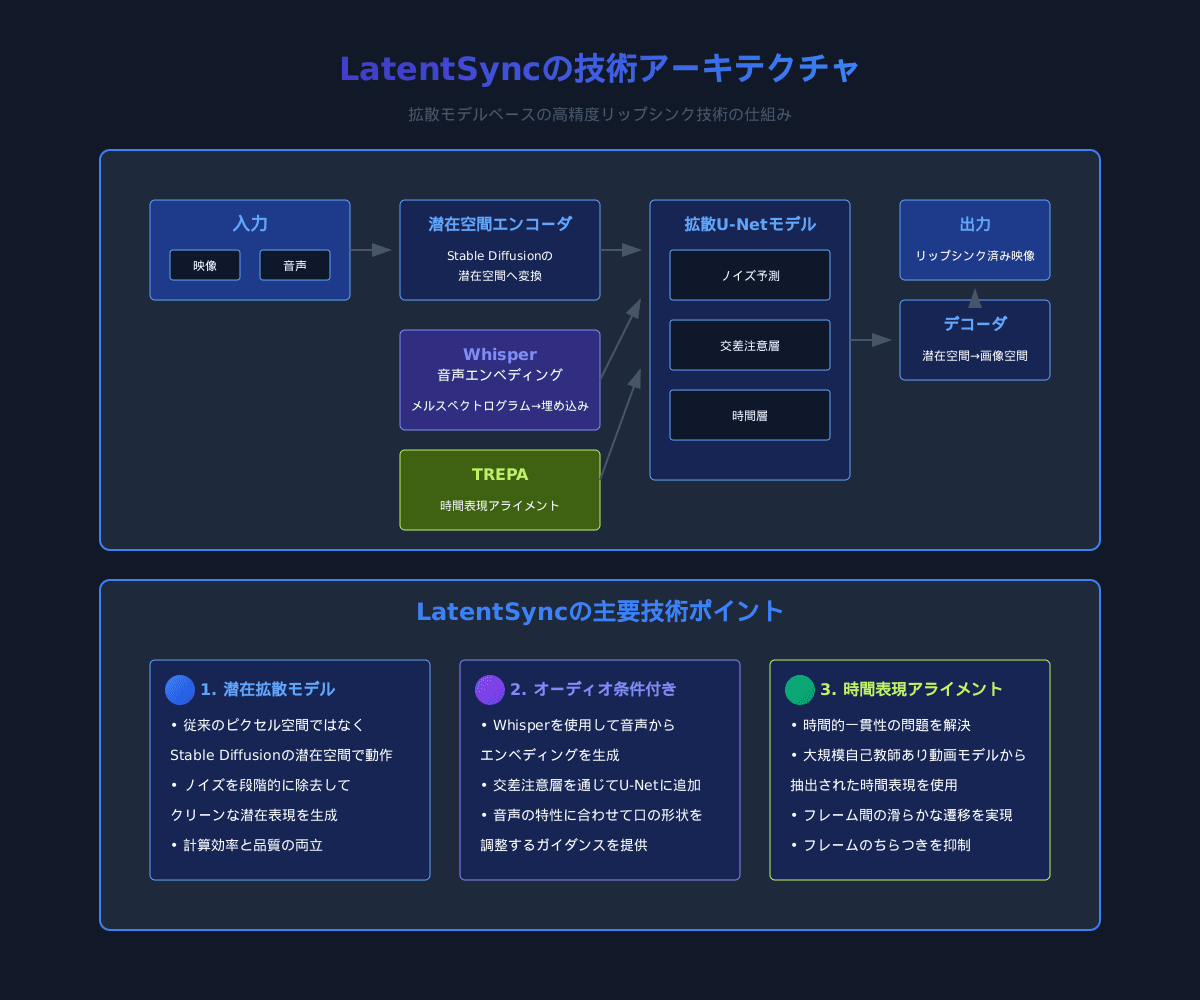
LatentSyncは、以下のような革新的な技術アプローチを採用しています:
- 潜在拡散モデル: 従来のピクセル空間ではなく、Stable Diffusionの潜在空間で動作する拡散モデルを使用
- オーディオ条件付き: Whisperを使用してメルスペクトログラムから音声埋め込みを生成し、U-Netの交差注意層を通じて追加
- 時間表現アライメント (TREPA): 大規模な自己教師あり動画モデルから抽出された時間表現を使用して生成フレームを調整し、時間的一貫性を向上
これにより、従来のGANベースのアプローチや初期の拡散モデルと比較して、より高品質で時間的に一貫性のあるリップシンクが可能になりました。
LatentSyncのセットアップ方法
要件
- NVIDIA GPU(VRAM 20GB以上推奨)
- Python 3.8以上
- PyTorch 1.12以上
- CUDA 11.7以上
インストール手順
# GitHubからリポジトリをクローン
git clone https://github.com/bytedance/LatentSync
cd LatentSync
# 依存関係のインストール
pip install -r requirements.txt
# 事前学習済みモデルのダウンロード
bash scripts/download_models.sh
基本的な使用方法
# 基本的な動画のリップシンク
python inference.py \
--input_video path/to/input_video.mp4 \
--input_audio path/to/audio.wav \
--output_dir path/to/output \
--model_path pretrained_models/latentsync_v1.5.pth
高品質な結果を得るためのコツ
LatentSyncで最良の結果を得るためのヒントをいくつか紹介します:
- 入力映像の品質: 顔が明確に見え、十分な解像度(最低720p)を持つ映像を使用する
- 音声の品質: クリアな音声ファイルを使用し、背景ノイズを最小限に抑える
- 顔の向き: 正面を向いた映像が最も良い結果を生む傾向がある
- 後処理: 出力動画の嘴周辺の詳細が不足する場合は、超解像モデル(Real-ESRGANなど)を使って品質を向上させることができる
LatentSyncの実用例
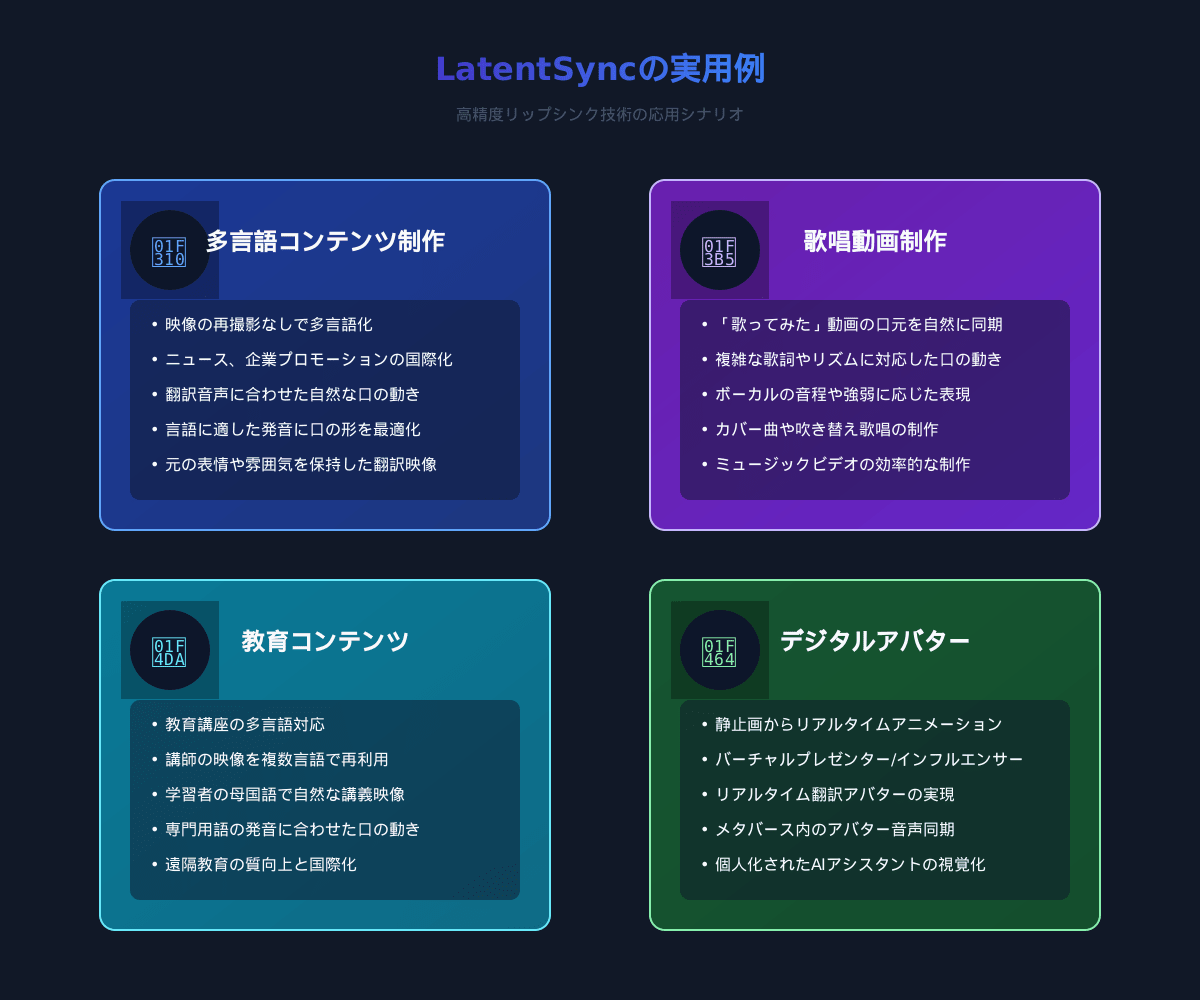
LatentSyncは以下のような用途で特に効果を発揮します:
- 多言語コンテンツ制作: 異なる言語の音声で同じ映像を再利用
- 歌唱動画: 歌声に合わせた自然な口の動きの生成
- 教育コンテンツ: 講師の映像を複数の言語に対応させる
- デジタルアバター: 写真から生成したアバターに音声を同期させる
実践的な応用例: 歌ってみた動画の作成
ここでは、LatentSyncを使って「歌ってみた」動画を作成する手順を紹介します。
必要なもの
- 顔が写った動画クリップ(正面向きが理想的)
- 歌声の音声ファイル
- LatentSyncがインストールされた環境
手順
1. 準備
まず、以下の準備をします:
- 元となる動画を選択(正面を向いている部分が含まれているもの)
- 歌声の音声ファイルを用意(WAV形式推奨)
- 必要に応じて動画をトリミングし、使いやすい長さにする
2. 映像と音声の同期
LatentSyncを使用して、映像と歌声を同期させます:
python inference.py \
--input_video your_face_video.mp4 \
--input_audio your_singing_voice.wav \
--output_dir ./output \
--model_path pretrained_models/latentsync_v1.5.pth \
--enhance_lip True
--enhance_lip Trueオプションを追加することで、唇の部分の詳細さを強調できます。
3. ポストプロセッシング
生成された動画の品質を向上させるための後処理:
- 超解像処理: 嘴周辺の詳細が不足している場合は、Real-ESRGANなどの超解像モデルを適用
- カラーグレーディング: 必要に応じて色調補正を行い、元の映像と合わせる
- 音声処理: BGMの追加や音量調整、エコーやリバーブの追加などを行う
4. 最終編集
編集ソフトウェア(Adobe Premiere Pro、DaVinci Resolve、Final Cutなど)を使用して:
- イントロやアウトロの追加
- トランジションの適用
- テロップやクレジットの追加
- 最終的なエクスポート(高品質設定を推奨)
ヒントとコツ
- 表情を含む: リップシンクだけでなく、歌に合った表情も重要です
- フレームレート: 元の動画とリップシンク後の動画のフレームレートを合わせる
- ショートクリップの連結: 複数の短いクリップをリップシンクし、編集で繋げる方法も効果的
- 画質向上: LatentSyncの出力の解像度に制限がある場合は、超解像処理を適用して品質を向上させる
これらの手順とコツを参考に、高品質な「歌ってみた」動画を作成してみてください!
リップシンク技術の将来展望
リップシンク技術は急速な進化を続けており、今後さらに発展が期待されています。ここでは、2025年以降に予想される技術の進化と課題について考察します。
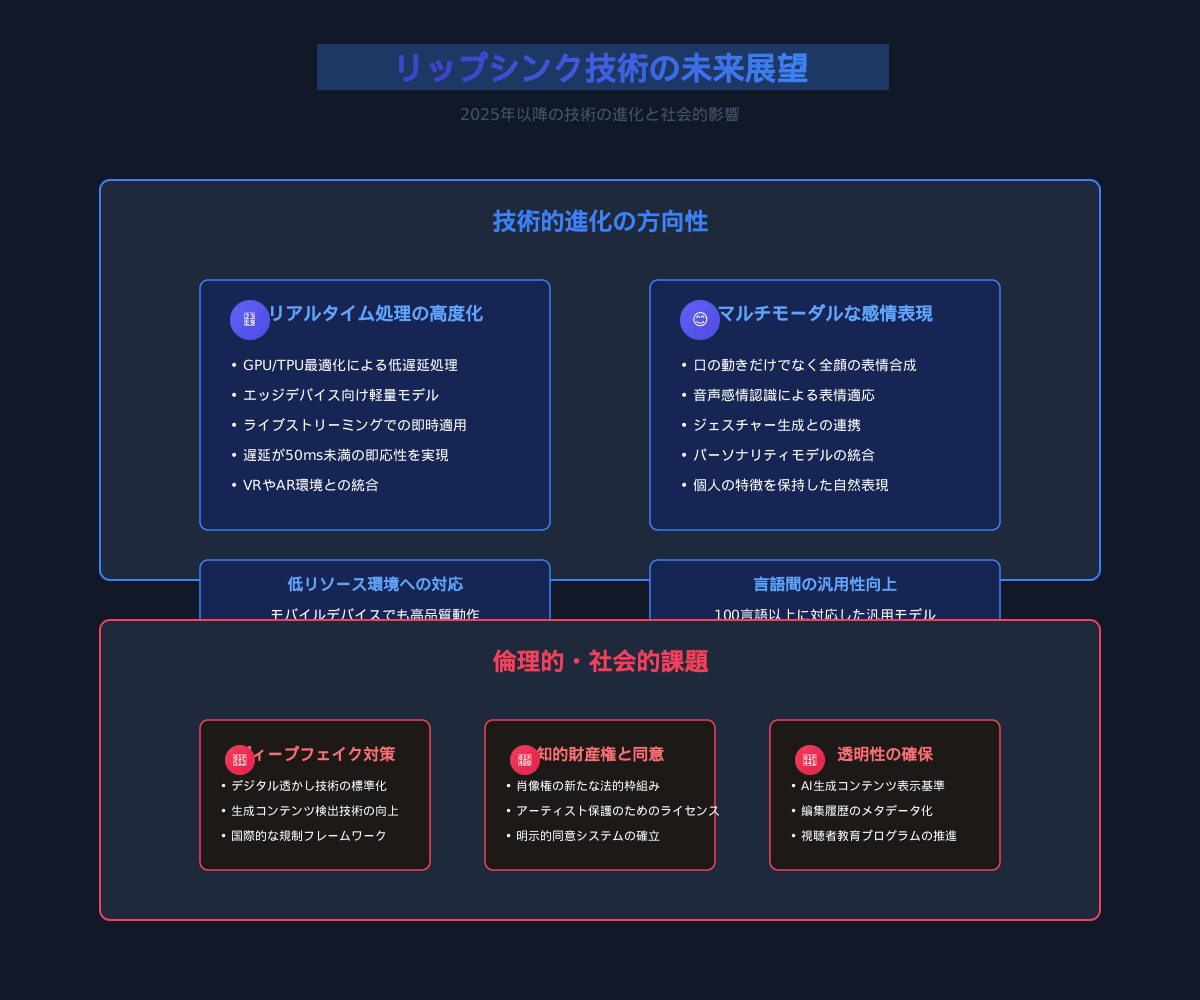
技術的な進化の方向性
-
リアルタイム処理の高度化
- 現在のリップシンク技術の多くは、処理に時間がかかりますが、今後はリアルタイム処理の精度と品質が向上していくでしょう
- これにより、ライブストリーミングや対話型アプリケーションでのリップシンク利用が一般化することが予想されます
-
マルチモーダルな感情表現
- 口の動きだけでなく、顔全体の表情や身体動作を音声と同期させる技術が発展
- 音声の感情やトーンに合わせて、自然な表情変化を生成する能力の向上
-
低リソース環境への対応
- 現在の高精度モデルはGPUリソースを多く必要としますが、モデルの軽量化と最適化により、モバイルデバイスや一般的なラップトップでも高品質なリップシンクが可能になるでしょう
-
言語間の汎用性向上
- 多言語に対応した汎用リップシンクモデルの開発が進み、言語に依存しない高品質なリップシンクが可能に
- 文化や言語特有の口の動きのニュアンスを保持する能力の向上
倫理的・社会的課題
リップシンク技術の発展に伴い、以下のような課題にも取り組む必要があります:
-
ディープフェイク対策
- リップシンク技術は誤用されるとディープフェイクコンテンツの作成に利用される可能性があります
- ウォーターマーキングや検出技術の開発が重要になっています
-
知的財産権と同意
- 他者の映像を使用する際の同意や権利問題の整理
- アーティストや俳優の肖像権保護のための法的枠組みの整備
-
透明性の確保
- AIで加工された動画であることを明示するための標準的な方法の確立
- 視聴者が人工的に生成されたコンテンツを認識できるようにする仕組み
まとめ
この記事では、最新のオープンソースリップシンク技術についてご紹介しました。2025年現在、最も高精度なOSSリップシンクツールは「LatentSync」であり、拡散モデルベースの革新的なアプローチにより、高品質なリップシンクが可能になっています。
リップシンク技術のポイントをまとめると:
- 技術の進化: GANベースのアプローチから拡散モデルベースへと進化し、品質と時間的一貫性が大幅に向上
- 主要なツール: LatentSync、Wav2Lip、SadTalker、OmniHuman-1など、目的に応じて選べる多様なオープンソースツールが存在
- 応用分野: 「歌ってみた」動画だけでなく、多言語コンテンツ制作、教育、エンターテイメントなど幅広い分野での活用が可能
- 将来性: リアルタイム処理、マルチモーダル感情表現、低リソース環境対応など、さらなる発展が期待される
リップシンク技術は、クリエイターの表現の幅を広げるだけでなく、言語の壁を越えたコミュニケーションを可能にする重要な技術です。この記事が、皆さんのクリエイティブな取り組みの一助となれば幸いです。
🐰「最新技術を使って、素敵な歌ってみた動画を作ってみてね!」
Discussion