うさぎでもわかるリアルタイムリップシンク 自然に動かせるOSS最前線
うさぎでもわかるリアルタイムリップシンク 自然に動かせるOSS最前線
はじめに
「わたしがしゃべってなくても、キャラクターが自然に口を動かして話してくれたらいいのに...」
「画像だけじゃなくて、動画でも自然な唇の動きを実現したいぴょん!」
こんな願いを持つクリエイターやエンジニアの皆さん、リアルタイムリップシンク技術が大きく進化している今、その願いはすでに現実のものとなっています。
リップシンク(Lip Sync)とは、音声に合わせて口の動きを同期させる技術のこと。近年のAI技術の発展により、単に口の開閉だけでなく、唇の形、歯の見え方、さらには舌の動きまでリアルに再現できるようになりました。さらに、リアルタイムで処理できるツールも増えてきています。
本記事では、高精度なリアルタイムリップシンクを実現するオープンソースソフトウェア(OSS)を紹介し、それぞれの特徴や使い方、応用例までを解説します。開発者やクリエイターの方々が、自分のプロジェクトに最適なツールを見つけるための参考になれば幸いです。
では、さっそく、うさぎでもわかるリアルタイムリップシンクの世界へ飛び込んでみましょう!
リアルタイムリップシンク技術の基本
\n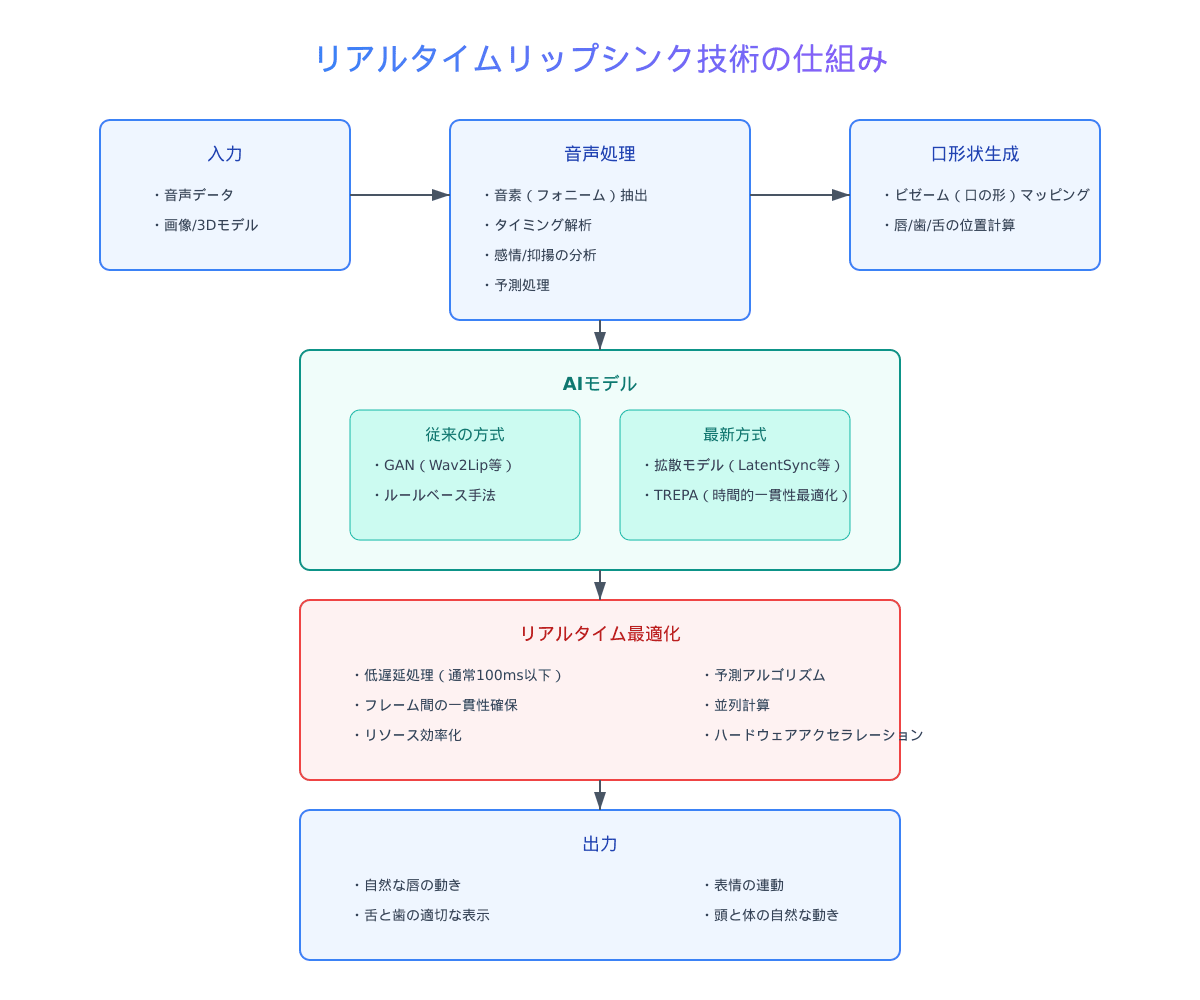
リップシンク技術とは
リップシンク技術は、音声データに合わせて口の動きを生成する技術です。単純な例では、声の大きさに合わせて口の開き具合を変えるといった方法もありますが、現代の高度なリップシンク技術では、以下のような要素が考慮されます:
- 音素(フォニーム)解析: 音声から「あ」「い」「う」といった音素を識別し、それに対応する口の形を生成
- 口の形状(ビゼーム): 各音素に対応する口の形や唇の位置を正確に表現
- タイミング同期: 音声のタイミングに正確に合わせて口の動きを制御
- 自然な遷移: ある音素から次の音素への移行を滑らかに表現
従来のリップシンク技術では、これらを手作業やルールベースのアルゴリズムで実現していましたが、AIの登場により、より自然で精度の高いリップシンクが可能になりました。
リアルタイム処理の仕組みと課題
リアルタイムリップシンクでは、入力された音声をわずかな遅延で分析し、即座に対応する口の動きを生成する必要があります。この過程では、次のような課題が存在します:
- 低遅延処理: 人間が違和感を感じないレベルの遅延(通常は100ms以下)で処理する必要がある
- 予測処理: 次に来る音素を予測して滑らかな動きを生成する
- リソース効率: 限られたコンピュータリソースでも動作させるための最適化
- フレームの一貫性: フレーム間で不自然な飛びや揺れ(ジッター)を防止する
これらの課題に対して、最新のOSSツールではディープラーニングや拡散モデルといった先進的なアプローチで対応しています。
高精度リップシンクに必要な要素
真に自然なリップシンクを実現するためには、以下の要素が重要です:
- 唇の精密な動き: 唇の開き方、丸め方、横への広がりなどを正確に表現
- 歯の可視性: 特定の音素での歯の見え方を正確に再現
- 舌の動き: 「た」「ら」「な」などの発音時の舌の位置や動きの表現
- 頬や顎の連動: 口の動きに連動する頬や顎の微妙な動きの再現
- 表情との連携: 笑顔や怒りなどの表情と口の動きの自然な組み合わせ
最新のツールでは、これらの要素を統合的に扱い、より自然で説得力のあるリップシンクを実現しています。
主要オープンソースリップシンクツールの比較
\n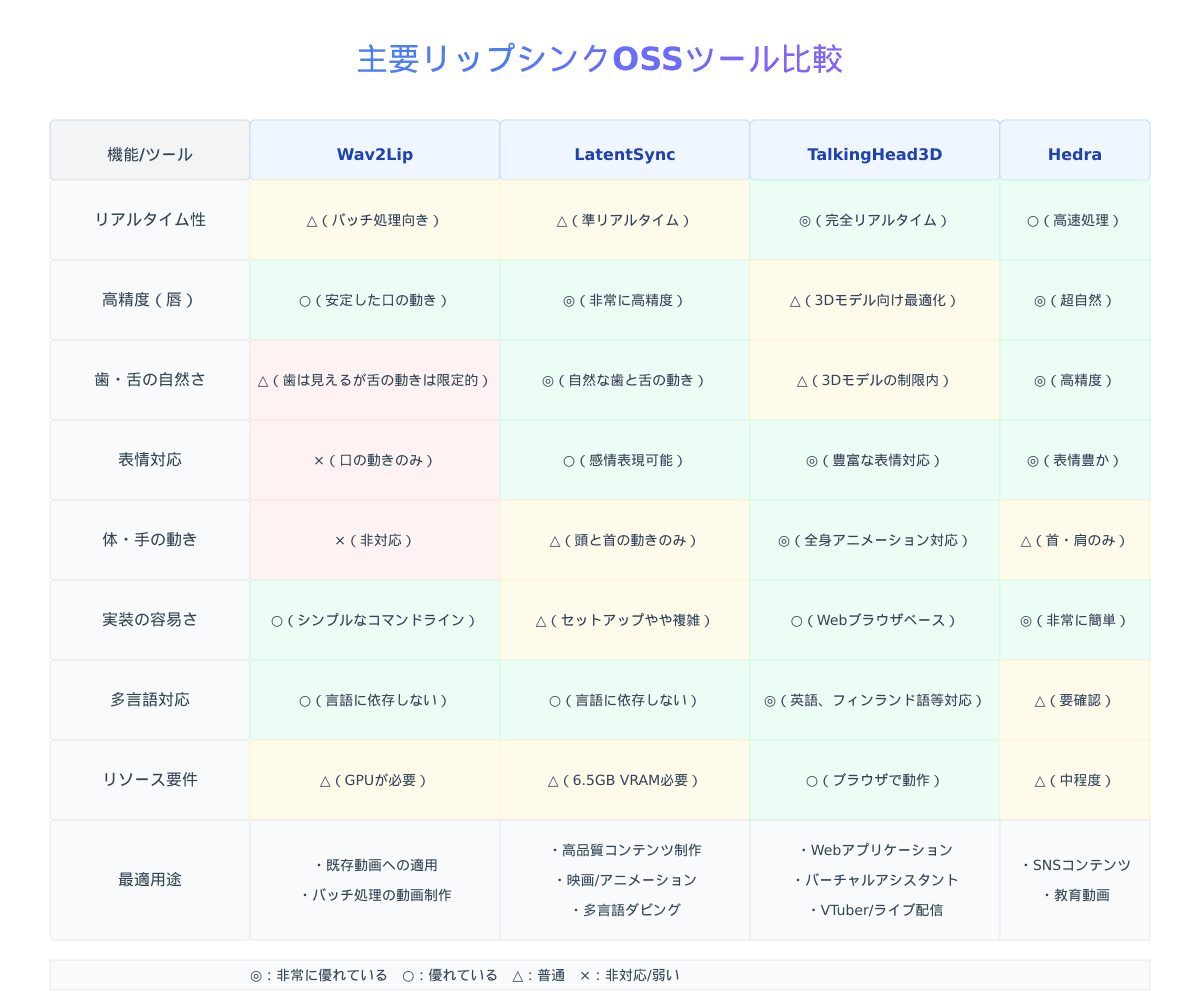
それでは、現在入手可能な主要なオープンソースリップシンクツールを見ていきましょう。それぞれの特徴や長所・短所を理解することで、目的に合ったツールを選択できるようになります。
Wav2Lip
概要:
Wav2Lipは、2020年にACM Multimediaで発表された高精度なリップシンク生成ツールです。任意の音声と映像のリップシンクを正確に同期させるように設計されています。
主な特徴:
- 高品質な口元シンクロ生成
- 完全なトレーニングコードと推論コード
- 事前にトレーニング済みのモデルを提供
- 研究、学術、個人での使用に適している
長所:
- 既存の動画に対して安定したリップシンクを提供
- 実装が比較的シンプル
- 様々な顔の角度や照明条件でも機能する
短所:
- 完全なリアルタイム処理には適していない
- 舌の詳細な動きや表情の変化には制限がある
- 歯の表現があまり自然でない場合がある
Wav2Lipは初期の高精度リップシンクOSSとして広く使われていますが、最近ではより高度な技術が登場しています。
LatentSync (ByteDance)
概要:
ByteDanceが開発・公開した革新的なリップシンクツールです。音声条件付き潜在空間拡散モデルに基づくエンドツーエンドのリップシンクフレームワークで、高精度な音声-映像同期を実現しています。
主な特徴:
- 音声駆動の潜在拡散モデルを使用
- 中間表現なしで高品質のリップシンクを直接生成
- 実写とアニメキャラクターの両方に対応
- エンドツーエンドで一貫性のある最適化プロセス
- 時間的一貫性(TREPA)の最適化技術採用
長所:
- 従来手法で見られたフレームジッターの問題を解決
- 完璧な時間的一貫性を実現
- 舌や歯を含む自然な口の動きを生成
- 表情や発話パターンのニュアンスを反映
- 推論に約6.5GBのVRAMのみが必要(比較的低リソース)
短所:
- 完全なリアルタイム処理には一部制限がある
- セットアップが若干複雑
LatentSyncは最新のAI技術を活用した高度なリップシンクツールで、特に時間的一貫性と自然な表現において優れています。
TalkingHead3D
概要:
TalkingHead3Dは、Ready Player Meの3Dアバターを使用してリアルタイムにリップシンクと表情を生成するJavaScriptクラスです。WebGLを使用した3Dレンダリングにより、ブラウザ上でリアルタイムに動作します。
主な特徴:
- Ready Player Me全身3Dアバター(GLB)対応
- Mixamoアニメーション(FBX)のサポート
- 字幕機能
- 絵文字から表情への変換機能
- Google Cloud TTS対応(デフォルト)
長所:
- 完全なリアルタイム処理が可能
- 頭、体、手の動きも含めた総合的なアニメーション
- ブラウザベースで容易に実装可能
- 複数言語(英語、フィンランド語、リトアニア語など)に対応
- 豊かな表情変化の表現
短所:
- 3Dアバターに限定される(実写には非対応)
- 細部のリアリズムでは他のツールに劣る場合がある
- 特定のアバターフォーマットに依存
TalkingHead3Dは特にWeb上でのリアルタイムアプリケーションやバーチャルアシスタント、教育コンテンツなどに適しています。
その他の注目ツール
Hedra Character-1:
- 音声データと一枚の画像から自然な動画を生成
- 口の動きだけでなく、表情や顔の向き、首や肩の動きまで表現
- 高度なAIによる超自然なリップシンク
- 簡単な操作性
- 無料版と有料版あり
Vozo AI:
- プロフェッショナル向けの高度なAIリップシンク機能
- 写真と動画の両方で非常にリアリスティックなアニメーション
- 複数の顔(最大6つ)に対応
- マーケティング、教育、動画制作に最適
Sync.so (旧Synclabs):
- 開発者向けのAPIサポート
- 信頼性の高いリップシンク機能
- 拡張性の高いワークフローと既存アプリケーションへの統合に適している
これらのツールはいずれもオープンソースではないものの、一部無料プランがあり、商用ライセンスでの利用も可能です。用途や必要な機能に応じて選択することができます。
次の項では、これらのツールの実装方法や活用事例について見ていきます。
実装と活用事例
各リップシンクOSSツールの基本的な実装方法と、実際の活用事例を紹介します。
LatentSyncの実装例
LatentSyncは、ByteDanceによるエンドツーエンドのAIビデオリップシンクフレームワークです。GitHub上でオープンソース化されており、以下のような実装が可能です。
基本的なセットアップ:
# リポジトリのクローン
git clone https://github.com/bytedance/LatentSync.git
cd LatentSync
# 依存関係のインストール
pip install -r requirements.txt
# 事前学習モデルのダウンロード
# (公式リポジトリの指示に従ってください)
基本的な使用例:
import latentsync as ls
# モデルの初期化
model = ls.LatentSyncModel.from_pretrained("path/to/model")
# 音声と動画の読み込み
audio = ls.load_audio("input_audio.wav")
video = ls.load_video("input_video.mp4")
# リップシンク動画の生成
output_video = model.sync(video, audio)
# 結果の保存
output_video.save("output_video.mp4")
TalkingHead3Dの実装例
TalkingHead3Dは、Webブラウザで動作するJavaScriptベースのリップシンクツールです。
基本的なセットアップ:
<\!-- HTMLファイルに以下を追加 -->
<script src="path/to/talkinghead.js"></script>
<div id="avatar-container" style="width: 800px; height: 600px;"></div>
基本的な使用例:
// TalkingHeadインスタンスの作成
const talkingHead = new TalkingHead({
container: document.getElementById('avatar-container'),
ttsLang: 'ja-JP',
ttsVoice: 'ja-JP-Standard-A',
modelFPS: 30
});
// アバターの読み込み
talkingHead.showAvatar({
url: 'path/to/avatar.glb',
body: 'maleM'
});
// テキストを喋らせる
talkingHead.speakText('こんにちは!これはリアルタイムリップシンクのデモです。');
Wav2Lipの実装例
Wav2Lipは、Python環境で動作するリップシンクツールです。
基本的なセットアップ:
# リポジトリのクローン
git clone https://github.com/Rudrabha/Wav2Lip.git
cd Wav2Lip
# 依存関係のインストール
pip install -r requirements.txt
# 事前学習済みモデルのダウンロード
wget -P checkpoints/ https://iiitaphyd-my.sharepoint.com/:u:/g/personal/radrabha_m_research_iiit_ac_in/Eb3LEzbfuKlJiR600lQWRxgBIY27JZg80f7V9jtMfbNDaQ?download=1
基本的な使用例:
python inference.py --checkpoint_path checkpoints/wav2lip_gan.pth --face video.mp4 --audio audio.wav --outfile result.mp4
活用事例
これらのツールを活用した実際の事例を見てみましょう。
バーチャルYouTuber/VTuber制作:
TalkingHead3DやLatentSyncを使用して、リアルタイムでリップシンクするバーチャルキャラクターを作成できます。配信者が話す音声に合わせて自動的に口が動く3Dアバターは、生配信やYouTube動画制作に革命をもたらしています。
多言語コンテンツ制作:
LatentSyncのような高精度ツールを使うと、一度撮影した動画を異なる言語に変換する際に、自然なリップシンクを維持できます。国際的なマーケティングやグローバルな教育コンテンツに非常に有効です。
インタラクティブガイド:
博物館や観光地などでは、TalkingHead3Dを活用したインタラクティブなガイドキャラクターが来場者に情報を提供します。リアルタイムなリップシンクにより、まるで本物のガイドと会話しているような没入感が得られます。
教育コンテンツ:
語学学習や発音訓練において、正確な口の動きと音声を同期させることで、より効果的な学習体験を提供しています。特に舌や歯の動きが見える高精度リップシンクは、正確な発音の習得に役立ちます。
技術的課題と今後の展望
リアルタイムリップシンク技術は急速に発展していますが、いくつかの技術的課題も残されています。
現在の主な課題
-
リアルタイム処理と品質のバランス:
高品質なリップシンクほど計算コストが高くなる傾向があり、リアルタイム性との両立が難しい場合があります。特に舌や歯の細かい動きを含めた高精度リップシンクをリアルタイムで処理するには、さらなる最適化が必要です。 -
多言語対応の課題:
言語によって口の動きのパターンが大きく異なるため、多言語に対応したリップシンクシステムの開発は複雑です。特に日本語と英語のように音素体系が大きく異なる言語間でのリップシンクには課題が残ります。 -
表情との自然な統合:
口の動きだけでなく、それに伴う表情全体(目の動き、眉の動き、頬の変化など)との自然な連携が重要です。これらを統合的に扱うモデルの開発がさらに必要とされています。 -
ユースケースごとの最適化:
VRチャット、生配信、映画制作など、用途によって求められる精度やリアルタイム性が異なります。これらの多様なニーズに対応するためのカスタマイズ性の向上が課題です。
今後の展望
-
ハードウェアとの連携強化:
AR/VRヘッドセット、モーションキャプチャシステム、表情認識カメラなどのハードウェアと連携することで、より自然でインタラクティブなリップシンク体験が実現可能になるでしょう。 -
マルチモーダルAIの発展:
音声、動画、テキストなどの複数のモダリティを組み合わせたAIモデルの発展により、文脈や感情を理解したより自然なリップシンクが実現する可能性があります。 -
軽量モデルの開発:
エッジデバイスやモバイル端末でも高品質なリップシンクを実現するための軽量モデルの開発が進むことで、アプリケーションの幅が大きく広がるでしょう。 -
オープンスタンダードの確立:
異なるプラットフォームやツール間で相互運用可能なリップシンクデータフォーマットやAPIの標準化が進むことで、エコシステムがさらに発展する可能性があります。
まとめ
本記事では、高精度なリアルタイムリップシンクを実現するオープンソースツールを紹介しました。各ツールには独自の特徴があり、用途や要件に応じて最適なものを選ぶことが重要です。
ツール選択のポイント:
-
完全なリアルタイム性が必要な場合:
TalkingHead3Dがブラウザベースで最も適しています。特にWebアプリケーションやインタラクティブなコンテンツに向いています。 -
最高の品質と自然さを求める場合:
LatentSyncが時間的一貫性と表現の自然さにおいて優れており、プロフェッショナルな制作に適しています。 -
既存動画への適用に重点を置く場合:
Wav2Lipは既存の動画素材に対して安定したリップシンクを提供し、後処理向きです。 -
総合的なアニメーションが重要な場合:
TalkingHead3DやHedraなどは、口の動きだけでなく表情や体の動きも含めた総合的なアニメーションに適しています。
リアルタイムリップシンク技術は今後も進化を続け、より自然で表現力豊かなデジタルコミュニケーションを可能にしていくでしょう。クリエイターやエンジニアの皆さんがこれらのツールを活用し、新たな表現や体験を創造されることを願っています。
「これで私のキャラクターもリアルに話せるぴょん!」
リップシンク技術の世界は、まだまだ発展途上。新しいツールや手法が次々と登場していますので、引き続き最新の動向に注目していきましょう!
Discussion
TalkingHead3Dについて、このキーワードのまま検索してもヒットせず、ハルシネーションが発生している可能性が高いです。
これかも
見つかりました、、!すみません!
READMEにはTalkingHead(3D)とありました!
()の有無で検索結果も変わるんですね、、
ご迷惑おかけしました。
