うさぎでもわかるOpenAI.fm使い方ガイド
うさぎでもわかるOpenAI.fm使い方ガイド
はじめに
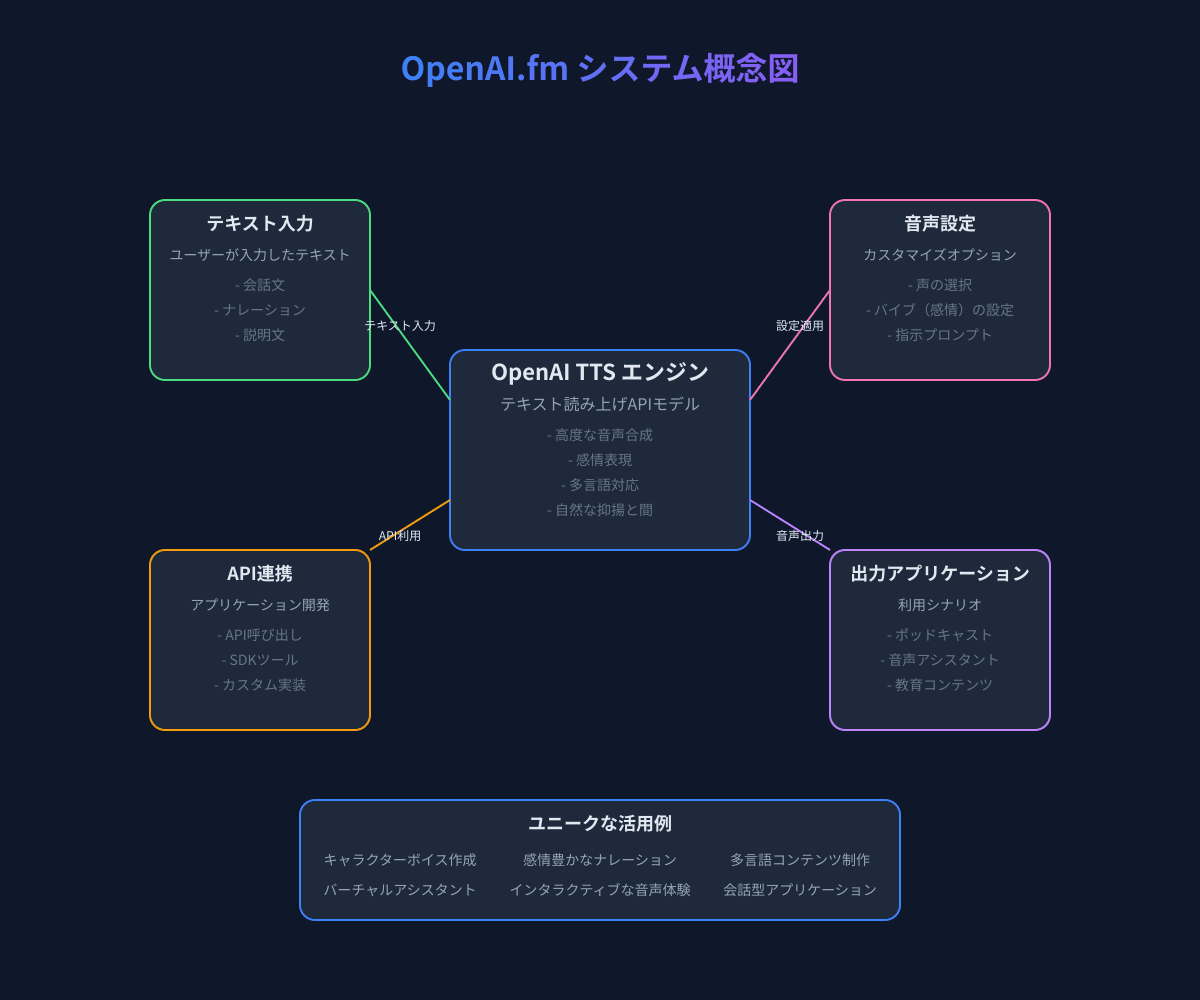
OpenAI.fmは、OpenAIが提供する最新のテキスト読み上げ(TTS: Text-to-Speech)モデルを試すことができるインタラクティブなデモサイトです。開発者向けに設計されたこのプラットフォームでは、テキストを自然で表現豊かな音声に変換できるだけでなく、声質や感情表現などの様々な要素をカスタマイズすることができます。
OpenAI.fmを使いこなせば、ポッドキャスト制作、教育コンテンツの作成、多言語対応のナレーション、キャラクターボイスの作成など、様々な用途で差別化されたコンテンツを生み出すことができます。ぴょんぴょん!
本記事では、OpenAI.fmの基本的な使い方から、ユニークな活用法、APIを使った実装例まで、幅広く解説します。特に「他の人とは違う使い方」や「差別化できるテクニック」に焦点を当てて、あなたのプロジェクトに役立つアイデアをご紹介します。
OpenAI.fmの基本知識
OpenAI.fmとは何か
OpenAI.fmは、OpenAIが開発した高度なテキスト読み上げ(TTS)モデルをウェブブラウザ上で簡単に試すことができるデモサイトです。このサービスは、テキストから自然な人間の声に近い音声を生成することができます。
OpenAIは2024年にOpenAI.fmと共に新しい音声モデルを発表しました。これには次世代の音声認識(Speech-to-Text)モデルと音声合成(Text-to-Speech)モデルが含まれており、その技術はOpenAI.fmを通じて体験することができます。
提供されている主な機能
OpenAI.fmでは、以下の主な機能が提供されています:
- 複数のボイスタイプ: Alloy、Nova、Echo、Fable、Onyx、Shimmerなど、様々な声質から選択できます。
- 感情表現(Vibe)の調整: Sincere(誠実)、Dramatic(劇的)、Serene(穏やか)など、様々な感情表現を選択できます。
- 指示プロンプト: 話し方や表現方法をテキストで細かく指示することができます。
- テキスト入力: 読み上げたいテキストを自由に入力できます。
- 音声生成: 設定した条件でテキストを音声に変換します。
対象ユーザー
OpenAI.fmは主に以下のようなユーザーを対象としています:
- 開発者: 自社のアプリケーションやサービスに音声機能を実装したい方
- コンテンツクリエイター: ポッドキャスト、オーディオブック、教育コンテンツなどを制作したい方
- UXデザイナー: 音声インターフェースを設計したい方
- 言語学習者: 発音や抑揚を学びたい方
- 音声アシスタント開発者: カスタマイズされた音声アシスタントを開発したい方
基本的な使い方
OpenAI.fmへのアクセス方法
OpenAI.fmは、ウェブブラウザから直接アクセスできます。以下の手順で利用を開始できます:
- ウェブブラウザで OpenAI.fm にアクセスします。
- サイトにアクセスすると、すぐにデモインターフェースが表示されます。
- 特別なアカウント登録やログインは必要ありません(デモ版の場合)。
インターフェースの説明
OpenAI.fmのインターフェースはシンプルで直感的に使えるように設計されています。
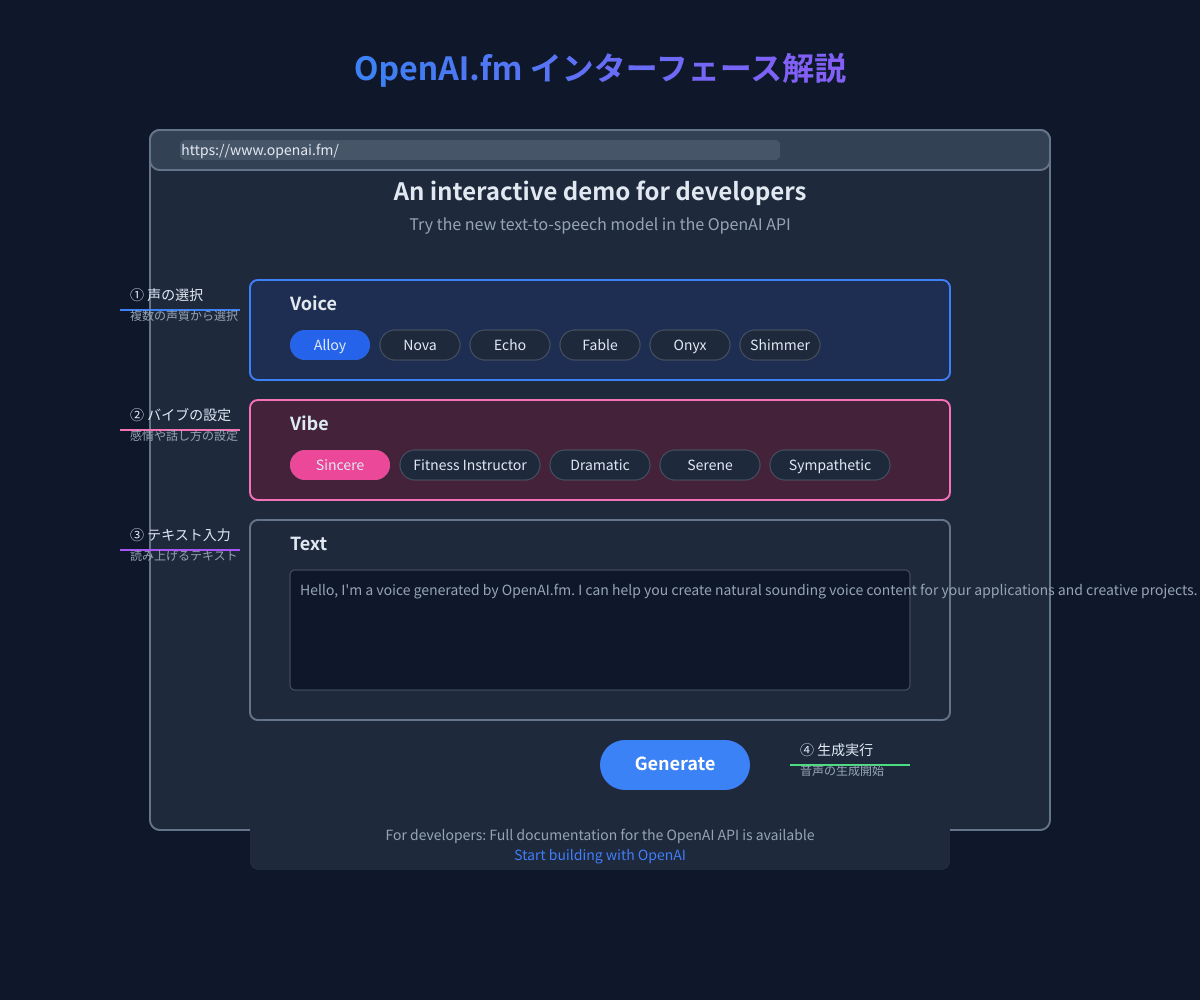
インターフェースは主に以下の要素で構成されています:
- Voice(ボイス選択): 様々な声質のオプションから選べます。
- Vibe(バイブ設定): 感情表現や話し方のスタイルを選択できます。
- Text(テキスト入力): 音声に変換したいテキストを入力するエリアです。
- Generate(生成ボタン): 設定した条件でテキストを音声に変換します。
基本的な音声生成の手順
OpenAI.fmで基本的な音声を生成する手順は以下の通りです:
- Voice(ボイス)を選択: 使いたい声質をクリックして選びます(例:Alloy、Nova、Echoなど)。
- Vibe(バイブ)を選択: 声の感情表現や話し方を選びます(例:Sincere、Dramatic、Sereneなど)。
- テキストを入力: 音声に変換したいテキストをテキストエリアに入力します。
- Generateボタンをクリック: 設定した条件で音声が生成され、自動的に再生されます。
生成された音声は、その場で聴くことができ、APIを利用する場合はダウンロードや保存も可能になります。
うさぎさんでも簡単にできるでしょ!
音声カスタマイズオプション
OpenAI.fmの真の力は、様々なカスタマイズオプションを組み合わせることで発揮されます。これらのオプションを適切に設定することで、ユニークで差別化された音声コンテンツを作成することができます。
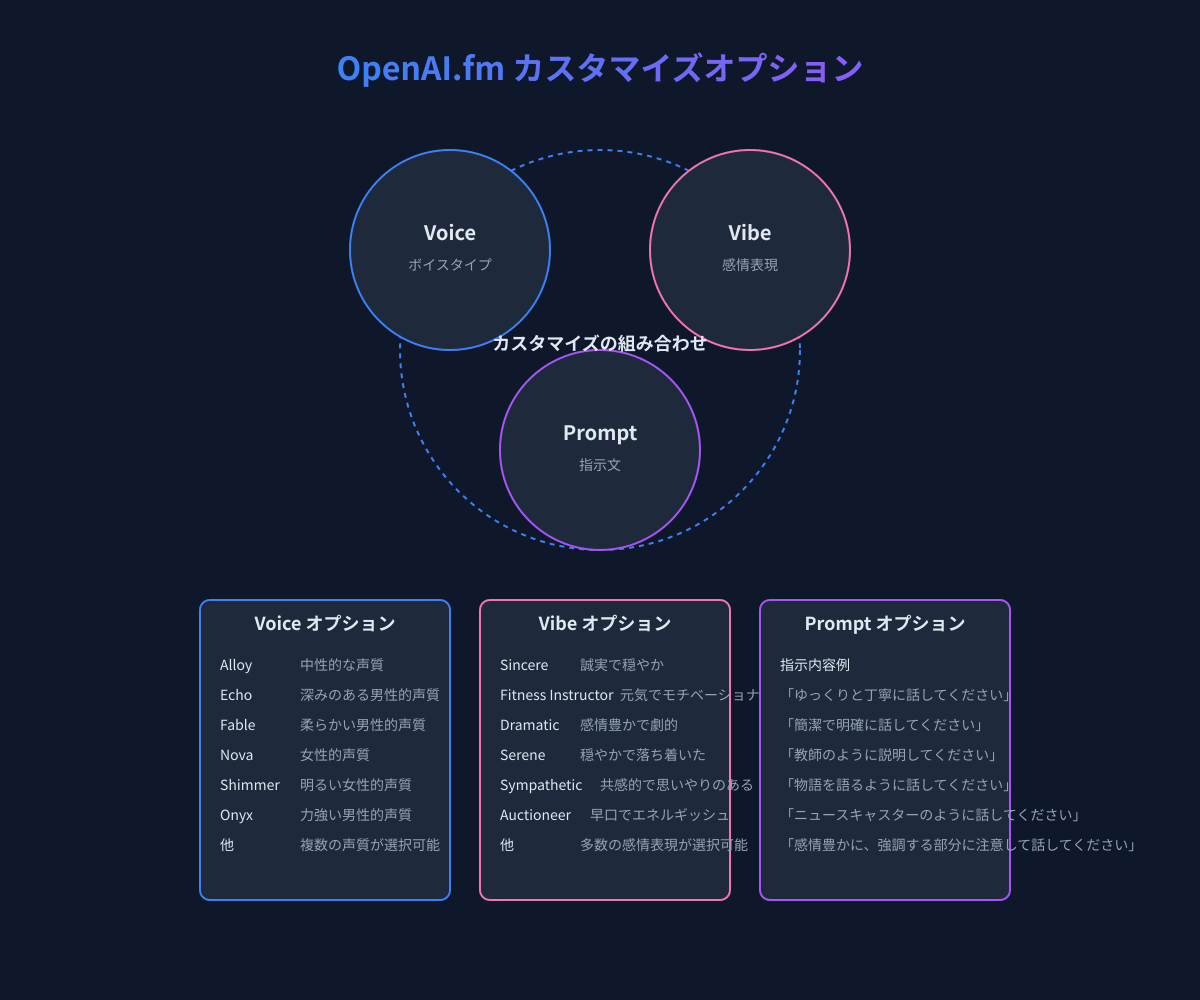
選択可能なボイスタイプとその特徴
OpenAI.fmには多様なボイスタイプが用意されており、それぞれ異なる声質や特徴を持っています。主なボイスタイプとその特徴は以下の通りです:
- Alloy: 中性的で汎用性の高い声質。様々なコンテンツに適しています。
- Nova: 明るく親しみやすい女性的な声質。ポジティブな内容や教育コンテンツに適しています。
- Echo: 落ち着いた深みのある男性的な声質。ナレーションやドキュメンタリーに適しています。
- Fable: やわらかく温かみのある男性的な声質。物語や童話の読み聞かせに適しています。
- Onyx: 力強く自信に満ちた男性的な声質。ビジネスコンテンツや説得力のある内容に適しています。
- Shimmer: 明るく活発な女性的な声質。エネルギッシュなコンテンツに適しています。
バイブ(感情表現)の調整と効果
バイブ(Vibe)は、声の感情表現や話し方のスタイルを指定するオプションです。適切なバイブを選ぶことで、同じテキストでも全く異なる印象を与えることができます。主なバイブオプションは以下の通りです:
- Sincere(誠実): 誠実で穏やかな話し方。信頼感を伝えたい場合に適しています。
- Dramatic(劇的): 感情豊かで表現力の高い話し方。物語や劇的な内容に適しています。
- Serene(穏やか): 落ち着いた静かな話し方。リラックスさせる内容やメディテーションに適しています。
- Fitness Instructor(フィットネスインストラクター): 元気でモチベーションを高める話し方。トレーニングやコーチングに適しています。
- Sympathetic(共感的): 思いやりと理解を示す話し方。医療や心のケアに関するコンテンツに適しています。
- Auctioneer(競売人): 早口でエネルギッシュな話し方。緊急性や活気を伝えたい場合に適しています。
プロンプト指示によるカスタマイズ
プロンプト指示は、音声生成に対してより細かい指示を与えることができる強力な機能です。テキスト形式で指示を与えることで、ボイスタイプやバイブの設定だけでは実現できない複雑な表現が可能になります。効果的なプロンプト指示の例は以下の通りです:
- 「ゆっくりと丁寧に、各単語を明確に発音してください」
- 「重要なポイントを強調し、質問部分では声を上げてください」
- 「教師のように説明するように話してください」
- 「ニュースキャスターのように公式で明確に話してください」
- 「物語を語るように、感情を込めて話してください」
- 「句読点に合わせて適切に間を取り、抑揚をつけてください」
これらのプロンプト指示を適切に組み合わせることで、より自然で表現豊かな音声を生成することができます。うさぎだって褒められる声が出せるぴょん!
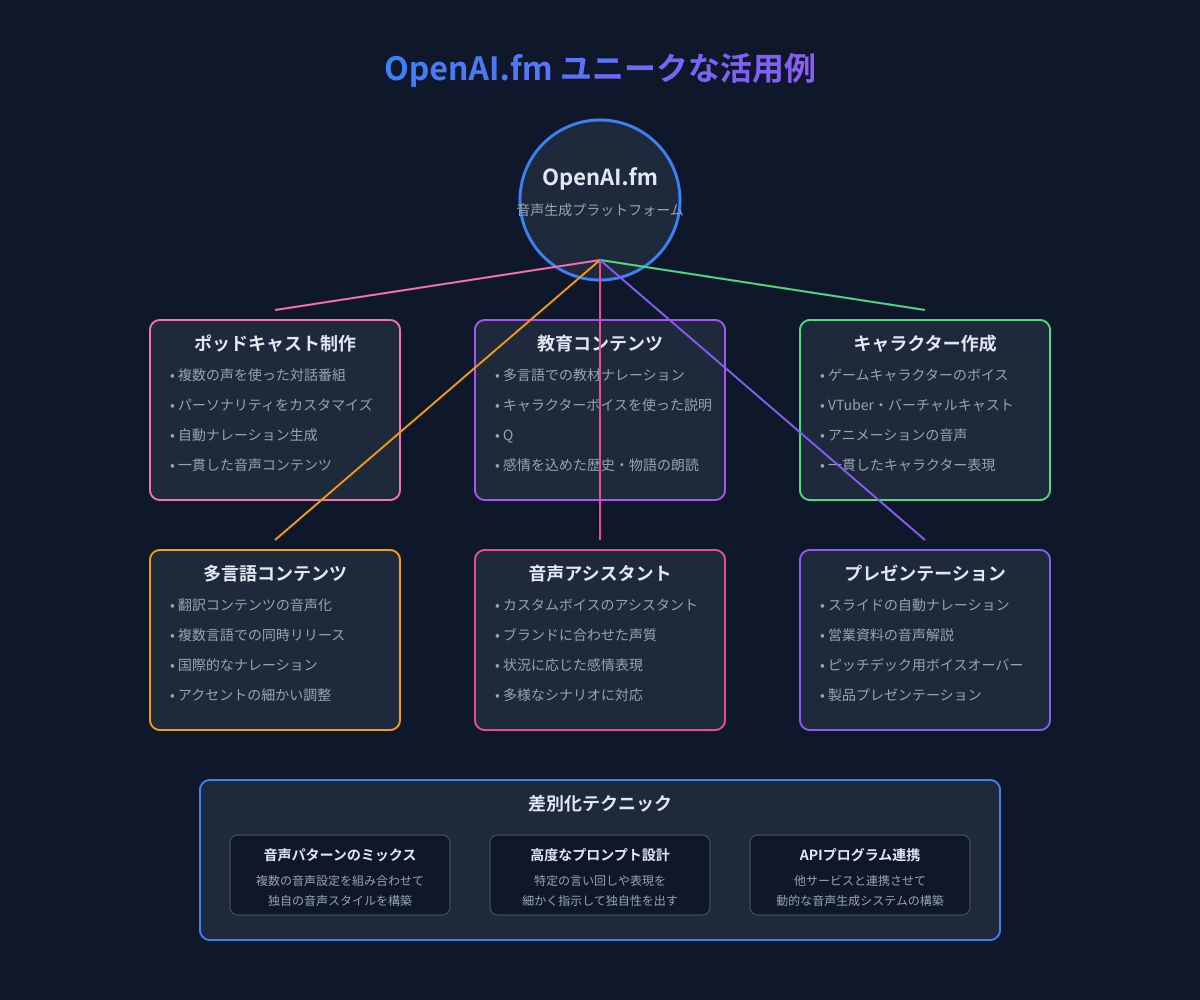
ユニークな使い方
OpenAI.fmの真の価値は、標準的な使い方を超えて創造的に活用することにあります。ここでは、他の人とは一味違ったユニークな使い方をご紹介します。
感情パターンの組み合わせテクニック
単一のバイブ設定だけでなく、複数の感情表現を組み合わせることで、より複雑で人間らしい音声を作成できます。
テクニック例:
-
感情の遷移: 同じ内容でも、段落ごとに異なるバイブ設定を適用し、感情の変化を表現します。
// 最初の段落: Serene(穏やか) // 中盤の段落: Dramatic(劇的) // 最後の段落: Sincere(誠実) -
コントラスト効果: 対照的な感情を意図的に組み合わせて、メリハリのある表現を作ります。
// 問題提起部分: Dramatic // 解決策説明部分: Serene // 締めくくり: Fitness Instructor
多言語対応と国際化
OpenAI.fmは多言語対応しており、これを活用して国際的なコンテンツを作成できます。
テクニック例:
-
アクセント調整: 同じ言語でも、プロンプト指示でアクセントを調整します。
// 英語のアメリカンアクセント "Speak with a clear American accent, emphasizing the 'r' sounds." // 英語のイギリスアクセント "Speak with a British accent, using proper British pronunciation and intonation." -
コードスイッチング: 一つのコンテンツ内で複数の言語を自然に切り替えます。
// 日本語と英語を交互に使う例 "日本語と英語を交互に話し、日本語の後に英語で同じ内容を繰り返してください。英語部分では少しスピードを落として話してください。"
キャラクター作成とストーリーテリング
OpenAI.fmを使って一貫したキャラクターの声を作成し、物語やストーリーテリングに活用できます。
テクニック例:
-
キャラクタープロファイル: 特定のキャラクターの声を再現するためのプロファイルを作成します。
// 老賢者キャラクター Voice: Echo Vibe: Serene Prompt: "あなたは年老いた賢者です。ゆっくりと深い知恵を伝えるように話し、時々咳払いをし、単語の間に少し間を置いてください。" // 元気な子供キャラクター Voice: Shimmer Vibe: Fitness Instructor Prompt: "あなたは10歳の元気な子供です。高い声で話し、興奮したように言葉を早口で話し、時々笑いながら話してください。" -
ダイアログ生成: 複数のキャラクター間の会話を作成します。
// スクリプト例 [老賢者]: "長い旅の途中で何を学んだのかね、若者よ。" [若者]: "多くのことを学びました、先生。特に忍耐の価値について。"
ポッドキャストやオーディオコンテンツ制作
OpenAI.fmを活用して、プロフェッショナルなポッドキャストやオーディオコンテンツを効率的に制作できます。
テクニック例:
-
マルチホストポッドキャスト: 異なるボイスを使って複数のホストがいるポッドキャストを一人で制作します。
// ホストA(司会者) Voice: Alloy Vibe: Sincere // ホストB(専門家) Voice: Echo Vibe: Dramatic // ホストC(ゲスト) Voice: Nova Vibe: Sympathetic -
インタビューセグメント: インタビュー形式のセグメントを作成します。
// インタビュアー "今日のゲストをご紹介します。AI技術の専門家である山田太郎さんです。山田さん、よろしくお願いします。" // インタビュイー "よろしくお願いします。今日はAIの最新動向についてお話できることを楽しみにしています。"
教育・学習コンテンツでの活用
OpenAI.fmを使って、効果的で魅力的な教育コンテンツを作成できます。
テクニック例:
-
インタラクティブレッスン: 問いかけと解説を組み合わせた学習コンテンツを作成します。
// 問いかけ部分 Voice: Nova Vibe: Fitness Instructor Text: "では、次の問題を考えてみましょう。2次方程式 x² - 5x + 6 = 0 の解は何でしょうか?少し時間を取って考えてみてください。" // 解説部分 Voice: Echo Vibe: Sincere Text: "解説します。因数分解すると、(x - 2)(x - 3) = 0 となりますので、x = 2 または x = 3 が解となります。" -
多感覚学習: 視覚資料と音声を組み合わせた学習教材を作成します。
// スライド1に合わせた音声 "このグラフは、過去10年間のデータトレンドを示しています。特に注目すべきは2021年の急上昇です。" // スライド2に合わせた音声 "次に、この現象の3つの主要因について詳しく見ていきましょう。第一に..."
ぴょんぴょん!これらのユニークな使い方を試して、あなただけの音声コンテンツを作成してみてください!
API実装例
OpenAI.fmで体験できるTTSモデルの機能は、OpenAI APIを通じて自分のアプリケーションに組み込むことができます。ここでは、実際の実装例とコードサンプルを紹介します。
OpenAI APIとの連携方法
OpenAI APIを使用するには、まず以下の準備が必要です:
- OpenAIアカウントの作成: OpenAIの公式ウェブサイトでアカウントを作成します。
- APIキーの取得: OpenAIのダッシュボードからAPIキーを取得します。
- APIライブラリのインストール: 使用する言語に応じたOpenAI APIクライアントライブラリをインストールします。
基本的な実装コード例
JavaScriptでの実装例
import OpenAI from 'openai';
// OpenAIクライアントの初期化
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
async function generateSpeech() {
try {
const speechFile = 'speech.mp3';
// テキスト読み上げリクエスト
const mp3 = await openai.audio.speech.create({
model: "tts-1",
voice: "alloy",
input: "こんにちは!OpenAI APIを使った音声生成の例です。様々なカスタマイズが可能です。",
});
// 音声データをファイルに保存
const buffer = Buffer.from(await mp3.arrayBuffer());
await fs.promises.writeFile(speechFile, buffer);
console.log(`音声ファイルが作成されました: ${speechFile}`);
} catch (error) {
console.error('エラーが発生しました:', error);
}
}
generateSpeech();
Pythonでの実装例
import os
from openai import OpenAI
# OpenAIクライアントの初期化
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def generate_speech():
try:
# テキスト読み上げリクエスト
response = client.audio.speech.create(
model="tts-1",
voice="nova",
input="こんにちは!OpenAI APIを使った音声生成の例です。様々なカスタマイズが可能です。"
)
# 音声データをファイルに保存
speech_file_path = "speech.mp3"
response.stream_to_file(speech_file_path)
print(f"音声ファイルが作成されました: {speech_file_path}")
except Exception as e:
print(f"エラーが発生しました: {e}")
generate_speech()
GitHubで公開されているライブラリの紹介
OpenAI.fmの機能を簡単に利用するためのライブラリやツールが、GitHubで公開されています。以下はその一例です:
-
openai-fm: OpenAI公式のOpenAI.fmデモのコードリポジトリ
- リポジトリ: https://github.com/openai/openai-fm
- NextJSとSpeech APIを使用したデモ実装
-
fairy-root/openai-fm: OpenAI.fmの非公式Pythonラッパー
- リポジトリ: https://github.com/fairy-root/openai-fm
- さまざまな音声とバイブのカスタマイズをサポート
実際のアプリケーション例
ポッドキャスト自動生成アプリ
import OpenAI from 'openai';
import fs from 'fs';
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
async function generatePodcastEpisode(script) {
// スクリプトをホストとゲストのセグメントに分割
const segments = script.split('\n\n');
const audioFiles = [];
for (const segment of segments) {
// 話者と内容を分離
const [speaker, content] = segment.split(': ');
let voice, vibe;
// 話者に基づいて音声設定を選択
if (speaker === 'ホスト') {
voice = 'echo';
vibe = 'sincere';
} else if (speaker === 'ゲスト') {
voice = 'nova';
vibe = 'dramatic';
}
// 音声生成
const fileName = `segment_${audioFiles.length}.mp3`;
const response = await openai.audio.speech.create({
model: "tts-1",
voice: voice,
input: content,
});
// 音声をファイルに保存
const buffer = Buffer.from(await response.arrayBuffer());
await fs.promises.writeFile(fileName, buffer);
audioFiles.push(fileName);
}
// 複数のオーディオファイルを結合(外部ライブラリ使用)
await combineAudioFiles(audioFiles, 'podcast_episode.mp3');
console.log('ポッドキャストエピソードが生成されました');
}
// 使用例
const podcastScript = `ホスト: こんにちは、みなさん。今日のテックポッドキャストへようこそ。今日は特別ゲストをお迎えしています。
ゲスト: お招きいただきありがとうございます。今日は最新のAI技術について皆さんと共有できることを楽しみにしています。
ホスト: 早速ですが、現在のAI業界で最も注目すべきトレンドは何だと思いますか?
ゲスト: 素晴らしい質問です。私が特に注目しているのは、マルチモーダルAIの発展です。テキスト、画像、音声を同時に理解できるAIが急速に進化しています。`;
generatePodcastEpisode(podcastScript);
多言語教育コンテンツ生成
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def generate_multilingual_lesson(content, languages):
"""
複数言語で教育コンテンツを生成する関数
"""
lesson_files = {}
for language, voice in languages.items():
print(f"{language}版の音声を生成中...")
try:
# 言語に応じた音声生成
response = client.audio.speech.create(
model="tts-1",
voice=voice["voice"],
input=content[language]
)
# ファイル名の設定と保存
file_path = f"lesson_{language}.mp3"
response.stream_to_file(file_path)
lesson_files[language] = file_path
print(f"{language}版の音声が生成されました: {file_path}")
except Exception as e:
print(f"{language}版の生成中にエラーが発生しました: {e}")
return lesson_files
# 使用例
lesson_content = {
"日本語": "こんにちは。今日は太陽系の惑星について学びましょう。太陽系には8つの惑星があります。",
"英語": "Hello. Today we will learn about the planets in the solar system. There are 8 planets in our solar system.",
"中国語": "你好。今天我们将学习太阳系中的行星。太阳系中有8颗行星。"
}
language_settings = {
"日本語": {"voice": "nova"},
"英語": {"voice": "alloy"},
"中国語": {"voice": "echo"}
}
lesson_files = generate_multilingual_lesson(lesson_content, language_settings)
print("全ての言語版が生成されました。", lesson_files)
うさぎさんも楽しく使えるぴょん!これらの実装例を参考に、自分のプロジェクトでOpenAI.fmの機能を活用してみてください。
差別化テクニック
他の人と同じように使うだけではなく、OpenAI.fmを使って本当に差別化されたコンテンツを作成するための高度なテクニックをご紹介します。
高度なプロンプトエンジニアリング
プロンプト指示は単なる基本的な指示だけでなく、より複雑で微妙なニュアンスを伝えることができます。以下に高度なプロンプト設計の例を示します:
感情の遷移を指示するプロンプト例:
「あなたは物語の語り手です。最初は静かで穏やかに話し始め、物語が進むにつれて徐々に声のトーンを上げ、クライマックスでは情熱的で迫力のある声で話し、最後は再び穏やかで思慮深い口調に戻してください。特に重要な単語や文はゆっくりと強調してください。」
特定のキャラクターを演じるプロンプト例:
「あなたは老練な探偵役を演じています。低めの声でゆっくりと話し、時々考え込むように間を置き、重要な推理の部分では声のトーンをやや上げて説明してください。時々、『うーむ』や『なるほど』といった思考の合間の言葉を自然に挿入してください。」
特定の話し方やアクセントのプロンプト例:
「あなたは西日本出身のキャラクターです。関西弁のイントネーションで話し、『~やねん』『~でんねん』などの表現を使い、明るく陽気な口調で話してください。質問の最後は声を上げて話すようにしてください。」
複数ボイスの連携と会話生成
単一の音声だけでなく、複数の音声を効果的に組み合わせることで、より豊かなコンテンツを作成できます。
会話シーンの作成テクニック:
-
キャラクター設定: 各キャラクターに一貫した声とバイブの設定を使用します。
キャラクターA: Voice=Nova, Vibe=Sincere キャラクターB: Voice=Echo, Vibe=Dramatic キャラクターC: Voice=Shimmer, Vibe=Fitness Instructor -
会話フロー設計: 会話の自然な流れを設計します。
A: こんにちは、今日はいい天気ですね。 B: ええ、久しぶりの晴れ間です。最近はずっと雨でしたからね。 C: みんな元気? 私はすごく元気だよ! 今日は何をして遊ぶ? A: そうですね、公園に行くのはどうでしょうか。 -
会話の編集と統合: 個別に生成した音声を編集ソフトウェアで統合します。
インタビュー形式コンテンツの作成例:
// インタビュアーとゲストの音声設定
const interviewer = { voice: 'alloy', vibe: 'sincere' };
const guest = { voice: 'echo', vibe: 'dramatic' };
// インタビューシーンの作成
const interviewSegments = [
{ speaker: interviewer, text: "本日のゲストをご紹介します。AI研究の第一人者である鈴木博士です。博士、ようこそお越しくださいました。" },
{ speaker: guest, text: "お招きいただきありがとうございます。今日はAIの未来について語れることを楽しみにしています。" },
{ speaker: interviewer, text: "早速ですが、最近のAI開発で最もエキサイティングな進展は何だとお考えですか?" },
{ speaker: guest, text: "私が特に注目しているのは、マルチモーダルAIの急速な発展です。テキスト、画像、音声を統合的に理解する能力は、人間のコミュニケーションの本質に近づいていると言えるでしょう。" }
];
// 各セグメントの音声を生成して結合
ビジネスでの差別化ポイント
ビジネス用途でOpenAI.fmを活用する際の差別化ポイントを紹介します。
ブランドボイスの確立:
- ブランドに合わせた一貫した音声キャラクターを設計する
- 企業のトーンアンドマナーに合った音声スタイルを選定する
- マーケティング資料や製品説明に一貫したボイスを使用する
例: ブランドボイス設計:
// テクノロジー企業の例
Voice: Alloy
Vibe: Sincere
Prompt: "専門的でありながらも親しみやすく、新しい技術について説明する時は少し興奮した調子で話し、ユーザーのニーズについて語る時は共感的なトーンで話してください。"
// 高級ブランドの例
Voice: Echo
Vibe: Serene
Prompt: "優雅で落ち着いた口調で、言葉をはっきりと丁寧に発音し、洗練された印象を与えてください。"
カスタマーサポートの強化:
- 様々なシナリオに対応した音声レスポンスを事前に用意
- 問題の種類や深刻度に応じた適切な声色と話し方を設計
- 多言語対応の自動音声レスポンスシステムの構築
ユーザーエクスペリエンス向上のためのテクニック
ユーザーエクスペリエンスを向上させる高度なテクニックを紹介します。
文脈に応じた声の切り替え:
- ユーザーの感情や状況に応じて、適切な声と感情表現を切り替える
- 情報の種類(重要なアラート、一般的な通知、カジュアルな会話など)に合わせた声を使い分ける
例: 音声アシスタントの状況別応答設計:
// ユーザー状態に基づく音声設定の選択
function selectVoiceSettings(userContext) {
if (userContext.isUrgent) {
// 緊急事態には明確で力強い声
return { voice: 'echo', vibe: 'dramatic',
prompt: "はっきりと明確に、重要情報を強調して話してください" };
} else if (userContext.isLearning) {
// 学習モードでは教師のような説明調
return { voice: 'alloy', vibe: 'sincere',
prompt: "教育的な口調で、ゆっくりと概念を説明してください" };
} else if (userContext.isRelaxed) {
// リラックスモードでは穏やかな声
return { voice: 'nova', vibe: 'serene',
prompt: "穏やかでリラックスした口調で話してください" };
}
// デフォルト設定
return { voice: 'alloy', vibe: 'sincere', prompt: "" };
}
インタラクティブな音声体験:
- ユーザーの応答や選択に基づいて動的に変化する音声コンテンツ
- 一方的な音声だけでなく、ユーザーとの対話を想定した間の取り方やプロンプト設計
ぴょんぴょん!これらの差別化テクニックを活用して、他にはない独自の音声体験を創り出してみてください!
まとめ
本記事では、OpenAI.fmの基本的な使い方から高度なカスタマイズテクニック、API連携、そして差別化されたコンテンツ制作方法までを幅広く解説しました。
重要ポイントの振り返り
- 基本機能: OpenAI.fmは多様なボイスタイプ、感情表現(バイブ)、プロンプト指示による高度なカスタマイズが可能
- ユニークな活用法: 感情パターンの組み合わせ、多言語コンテンツ制作、キャラクター作成、ポッドキャスト制作など
- API連携: JavaScript、Pythonなどの言語から簡単にOpenAI APIを使ってTTS機能を実装可能
- 差別化テクニック: 高度なプロンプトエンジニアリング、複数ボイスの連携、ビジネス活用戦略など
OpenAI.fmの将来性と展望
OpenAI.fmとその基盤となるTTS技術は急速に発展しており、今後さらに以下のような進化が期待されます:
- より自然で感情豊かな音声表現
- リアルタイム音声生成とインタラクション
- 個人の声に基づいたカスタムボイスの作成
- 多言語対応のさらなる強化
- 音楽や環境音と連携した包括的な音響体験
読者がさらに学べるリソース
より詳しく学びたい方のために、以下のリソースを参考にしてください:
OpenAI.fmの世界を探索して、あなただけのユニークな音声コンテンツを生み出してください。テキストから音声への変換は、単なる機能ではなく、新しい表現の可能性を広げるクリエイティブな手段です。
うさぎだってできる素敵な音声の世界で、あなたのクリエイティビティを思う存分発揮してくださいね!ぴょんぴょん!
Discussion