AIエンジニアのスキルロードマップと実践ガイド
AIエンジニアのスキルロードマップと実践ガイド
AIエンジニアとして成長するためには、技術的スキルだけでなく、ビジネス視点や継続的な学習姿勢も欠かせません。本記事では、AIエンジニアとしてのスキル習得ロードマップから実践的なハンズオン例、そして専門知識とソフトスキルの融合まで、総合的な成長戦略を解説します。
はじめに
近年、AI技術の急速な発展により、AIエンジニアの需要が高まっています。しかし、AIエンジニアとして活躍するためには、プログラミングやデータサイエンスの基礎から最新のAI技術まで、幅広い知識とスキルが求められます。
本記事は、以下の読者を対象としています:
- AIエンジニアを目指す開発者やデータサイエンティスト
- チームにAIエンジニアを育成したい技術マネージャー
- AIキャリアへの転向を検討している他分野のエンジニア
これから、実践的なスキル習得の学習ロードマップ、技術ギャップを埋めるためのハンズオン実践例、そしてソフトスキルと専門知識の融合について詳しく解説していきます。
1. 実践的スキル習得の学習ロードマップ
AIエンジニアとしてのスキル習得は一朝一夕には進みません。段階的なアプローチで着実にスキルを積み上げていくことが重要です。
段階的な学習アプローチ(初級→中級→上級)
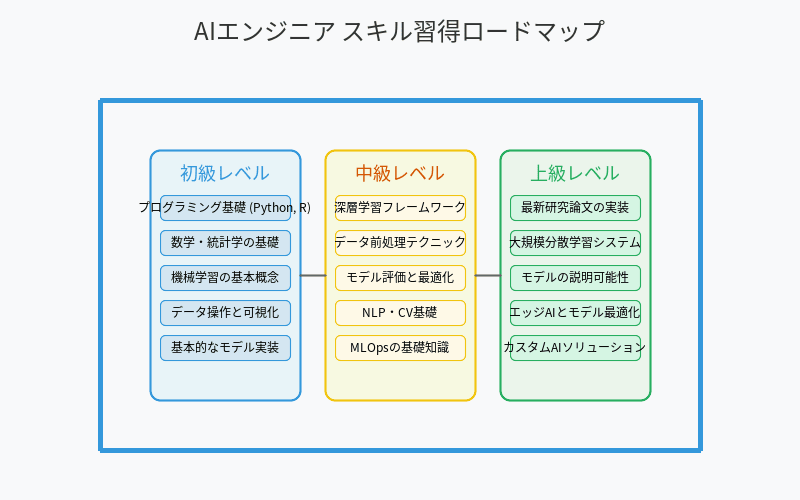
AIエンジニアとしてのスキル習得ロードマップ
初級レベル
- プログラミング基礎(Python、R)
- 数学・統計学の基礎(線形代数、確率統計、微積分)
- 機械学習の基本概念理解
- データ操作と可視化
- 基本的な分類・回帰モデルの実装
中級レベル
- 深層学習フレームワーク(TensorFlow、PyTorch)の活用
- データ前処理テクニック
- モデル評価と最適化
- 自然言語処理・コンピュータビジョンの基礎
- MLOpsの基礎知識
上級レベル
- 最新研究論文の実装と改良
- 大規模分散学習システムの構築
- モデルの解釈可能性と説明可能性
- エッジAIとモデル最適化
- カスタムAIソリューションの設計
効果的な学習リソースとツール
AIエンジニアとしてのスキルを効果的に習得するためには、適切な学習リソースとツールを活用することが重要です。
| スキルレベル | おすすめリソース | ツール |
|---|---|---|
| 初級 | Coursera, Udacity, edX, YouTube | Jupyter Notebook, Google Colab |
| 中級 | 専門書籍, GitHub, 論文解説サイト | Docker, クラウドプラットフォーム |
| 上級 | 学術論文, カンファレンス, ブログ | Kubernetes, MLOpsツール, 分散学習フレームワーク |
自己学習と組織的トレーニングの組み合わせ方
AIエンジニアとしての成長には、自己学習と組織的トレーニングの両方をバランスよく取り入れることが効果的です。
自己学習のアプローチ
- オンラインコースとチュートリアルの活用
- 個人プロジェクトの実施(Kaggleコンペなど)
- 技術ブログの定期的な閲覧と最新トレンドのキャッチアップ
- オープンソースプロジェクトへの貢献
組織的トレーニング
- 社内勉強会やワークショップの実施
- メンターシッププログラムの活用
- 専門家を招いたセミナーの開催
- 業界カンファレンスへの参加支援
効果的な組み合わせ方
- 組織のニーズに合わせた自己学習テーマの選定
- 学んだ内容を定期的に共有する場の設定
- 実務プロジェクトでの学習内容の積極的な適用
- 学習成果の定期的な振り返りと評価
実践プロジェクトの進め方
実践プロジェクトは、理論と実践をつなぎ、実務で必要なスキルを養うための重要な手段です。
プロジェクト選定のポイント
- 現在の技術レベルに適した難易度
- 実務に近い問題設定
- 明確な目標と評価指標
- 技術的多様性(データ収集から運用まで)
段階的なプロジェクト例
- 初級: 公開データセットを使った分類モデルの構築
- 中級: 実データを用いた予測モデルの開発と評価
- 上級: エンドツーエンドのAIシステム構築とデプロイ
プロジェクト進行のベストプラクティス
- 計画段階でのタイムボックス設定
- 定期的な振り返りと軌道修正
- ドキュメント作成の習慣化
- コードレビューとフィードバックの活用
2. 技術ギャップを埋めるためのハンズオン実践例
理論だけでなく、実践的なスキルを身につけるために、具体的なハンズオン例を通じて学習しましょう。
データ前処理とクレンジングの実践例
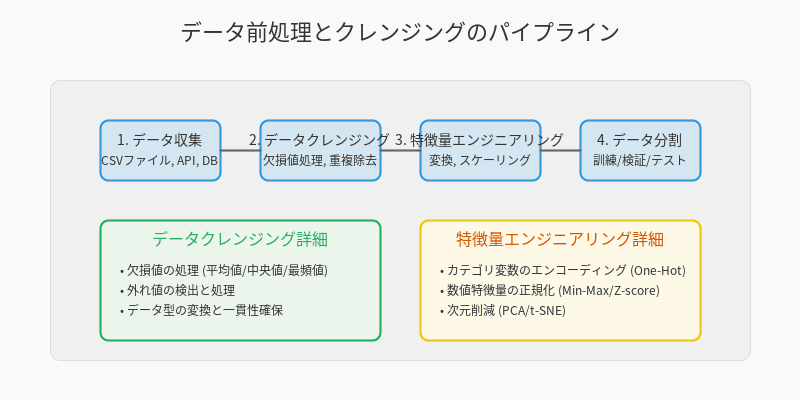
データ前処理とクレンジングの基本パイプライン
データ前処理は機械学習パイプラインの最も重要な部分の一つです。以下は、実際のデータセットに対する前処理の例です。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# サンプルデータの読み込み
df = pd.read_csv('customer_data.csv')
# 前処理パイプラインの構築
numeric_features = ['age', 'income', 'spending_score']
categorical_features = ['gender', 'location', 'membership_type']
# 欠損値の確認
print(f"欠損値の数:\n{df.isnull().sum()}")
# 数値データのパイプライン
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# カテゴリデータのパイプライン
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 前処理パイプラインの統合
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 前処理の実行
processed_data = preprocessor.fit_transform(df)
print(f"前処理後のデータ形状: {processed_data.shape}")
データ前処理のベストプラクティス
- 探索的データ分析(EDA)を徹底的に行う
- ドメイン知識を活用した特徴量エンジニアリング
- 再現可能な前処理パイプラインの構築
- クロスバリデーションを考慮した前処理の設計
機械学習モデル構築の基本ステップ
機械学習モデルの構築は、問題定義からデプロイまでの一連のプロセスです。以下に基本的なステップを示します。
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# データの分割
X = processed_data
y = df['customer_segment']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# モデルの構築
model = RandomForestClassifier(random_state=42)
# ハイパーパラメータのチューニング
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='f1_macro', n_jobs=-1)
grid_search.fit(X_train, y_train)
# 最適モデルの評価
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
print(f"最適パラメータ: {grid_search.best_params_}")
print(f"モデル評価:\n{classification_report(y_test, y_pred)}")
print(f"混同行列:\n{confusion_matrix(y_test, y_pred)}")
モデル構築のポイント
- 問題に適したアルゴリズムの選択
- 適切な評価指標の設定
- バイアスとバリアンスのトレードオフ考慮
- モデルの解釈可能性の確保
APIとの連携と実システムへの組み込み方
AIモデルを実用化するためには、APIとして提供し、実システムに組み込む必要があります。
from fastapi import FastAPI
import uvicorn
import joblib
from pydantic import BaseModel
import numpy as np
# モデルの読み込み
model = joblib.load('customer_segment_model.pkl')
preprocessor = joblib.load('preprocessor.pkl')
# FastAPIアプリケーションの作成
app = FastAPI(title="顧客セグメンテーションAPI")
# 入力データの定義
class CustomerData(BaseModel):
age: int
income: float
spending_score: float
gender: str
location: str
membership_type: str
# 予測エンドポイントの定義
@app.post("/predict/")
async def predict_segment(customer: CustomerData):
# 入力データをDataFrameに変換
input_df = pd.DataFrame([customer.dict()])
# 前処理の適用
processed_input = preprocessor.transform(input_df)
# 予測の実行
prediction = model.predict(processed_input)[0]
prediction_proba = model.predict_proba(processed_input)[0].tolist()
return {
"customer_segment": prediction,
"confidence_scores": {f"segment_{i}": score for i, score in enumerate(prediction_proba)}
}
# APIサーバーの起動
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
API統合のベストプラクティス
- RESTfulなAPIデザイン
- 入力バリデーションの徹底
- 適切なエラーハンドリング
- パフォーマンスモニタリングの実装
- ドキュメンテーションの充実
チームでの協働開発の進め方
AIプロジェクトは通常、データサイエンティスト、エンジニア、ドメインエキスパートなど、さまざまな専門家のチームで進められます。効果的な協働のためのポイントを紹介します。
バージョン管理とコード共有
# Gitを使ったコラボレーション例
git clone https://github.com/company/ai-project.git
cd ai-project
git checkout -b feature/improve-data-preprocessing
# コードの修正
git add .
git commit -m "Improve data preprocessing with robust outlier detection"
git push origin feature/improve-data-preprocessing
# プルリクエストを作成
協働開発のポイント
-
明確な役割分担
- データエンジニア: データ収集と前処理
- データサイエンティスト: モデル構築と評価
- MLエンジニア: モデルのデプロイと運用
- プロジェクトマネージャー: 全体調整とステークホルダー調整
-
効果的なコミュニケーション
- 定期的な進捗ミーティング
- 技術的意思決定の透明化
- ドキュメンテーションの徹底
-
品質管理プロセス
- コードレビューの実施
- テスト自動化の導入
- 継続的インテグレーション/継続的デプロイ(CI/CD)
3. ソフトスキルと専門知識の融合
AIエンジニアとして成功するためには、技術的スキルだけでなく、ビジネス理解やコミュニケーション能力などのソフトスキルも重要です。
ビジネス課題の理解と技術的解決策の提案能力
AIプロジェクトの成功は、技術的な精度だけでなく、ビジネス課題の解決にどれだけ貢献できるかで評価されます。
ビジネス理解のポイント
- 業界・ドメイン知識の習得
- ビジネスKPIと技術指標の関連付け
- ステークホルダーのニーズと期待の理解
- コスト・ベネフィット分析の実施
効果的な提案のためのフレームワーク
- 問題定義: ビジネス課題の明確化
- 解決策の範囲: 技術的に解決可能な領域の特定
- 成功指標: 技術的・ビジネス的評価指標の設定
- リスク評価: 技術的リスクとビジネスリスクの分析
- 実装計画: 短期・中期・長期のロードマップ作成
プロジェクト管理とコミュニケーションスキル
AIプロジェクトの複雑さを考えると、効果的なプロジェクト管理とコミュニケーションスキルが不可欠です。
プロジェクト管理のコツ
- アジャイル/スクラム手法の適用
- MVP(Minimum Viable Product)アプローチの採用
- 定期的な振り返りと改善サイクルの実施
- 適切なタスク分割と進捗管理
効果的なコミュニケーションのために
- 技術的内容の非技術者向け説明能力
- 可視化ツールの活用(ダッシュボードなど)
- 定期的なステータスレポートの提供
- フィードバックの収集と反映
倫理的考慮事項と社会的影響の理解
AIシステムの開発・運用においては、倫理的考慮事項と社会的影響を十分に理解することが重要です。
倫理的AIのためのチェックリスト
- バイアスとフェアネスの評価
- プライバシーとデータセキュリティの確保
- 説明可能性と透明性の担保
- 持続可能性と環境影響の考慮
実践的なアプローチ
- 多様なステークホルダーの参加
- 継続的な倫理的評価の実施
- 倫理ガイドラインの策定と遵守
- レスポンシブルAI原則の採用
継続的な学習とキャリア開発
AI分野は急速に進化しているため、継続的な学習とキャリア開発が不可欠です。
継続的学習のアプローチ
- 学習時間の確保(週に数時間の専用時間)
- 多様な学習リソースの活用
- 定期的な知識のアップデート
- 実験と失敗からの学び
キャリア開発のステップ
- 専門性の確立: 特定のAI分野での専門知識の深化
- 多様な経験: 異なる業界・プロジェクトへの挑戦
- コミュニティ参加: オープンソースやAIコミュニティへの貢献
- 知識の共有: 執筆、講演、メンタリングの実施
- リーダーシップ: AIチームやプロジェクトのリード
まとめ
AIエンジニアとしてのキャリアは、技術的スキル、ビジネス理解、倫理的考慮の3つの柱の上に成り立ちます。本記事で紹介した学習ロードマップ、ハンズオン実践例、ソフトスキルの融合を参考に、バランスの取れたスキルセットを構築していくことが重要です。
最後に、AIエンジニアとしての成功の鍵は以下の点にあります:
- 基礎となる技術スキルの確実な習得
- 実践プロジェクトを通じた経験の蓄積
- ビジネス課題を解決する視点の養成
- 継続的な学習と適応力の維持
- 倫理的視点と社会的責任の認識
これらのバランスを取りながら、AIエンジニアとしてのキャリアを構築していきましょう。
参考資料とリソース
- 書籍: 『Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow』
- オンラインコース: Coursera Machine Learning Specialization
- コミュニティ: Kaggle, GitHub, Stack Overflow
- カンファレンス: NeurIPS, ICML, ICLR, Applied ML Days
- ブログ: Towards Data Science, Analytics Vidhya
Discussion