【論文5分まとめ】Simple Baselines for Image Restoration
概要
画像復元(Image Restoration)のためのシンプルなベースラインモデルを提案。しかし、本論文の最大の見どころは、UNetのようなシンプルなEncoder-Decoderネットワークの性能を保ちながら、非線形活性化関数を一切使わないモデルアーキテクチャであるNAFNetに至るという点にある。この点で、画像復元以外のタスクにも大きな示唆を与えうる研究になっている。
書誌情報
- Chen, Liangyu, et al. "Simple Baselines for Image Restoration." arXiv preprint arXiv:2204.04676 (2022).
- https://arxiv.org/abs/2204.04676
- MEGVII Technology
- 公式実装
ポイント
既存の画像復元のネットワークの複雑さをブロック間の複雑さとブロック内の複雑さに分け、それぞれを低減するためにどうすべきかを試行錯誤している。
ブロック間の複雑さの低減
画像復元のネットワークはEncoder-Decoder形式のネットワーク構造を採用しているものが多い。
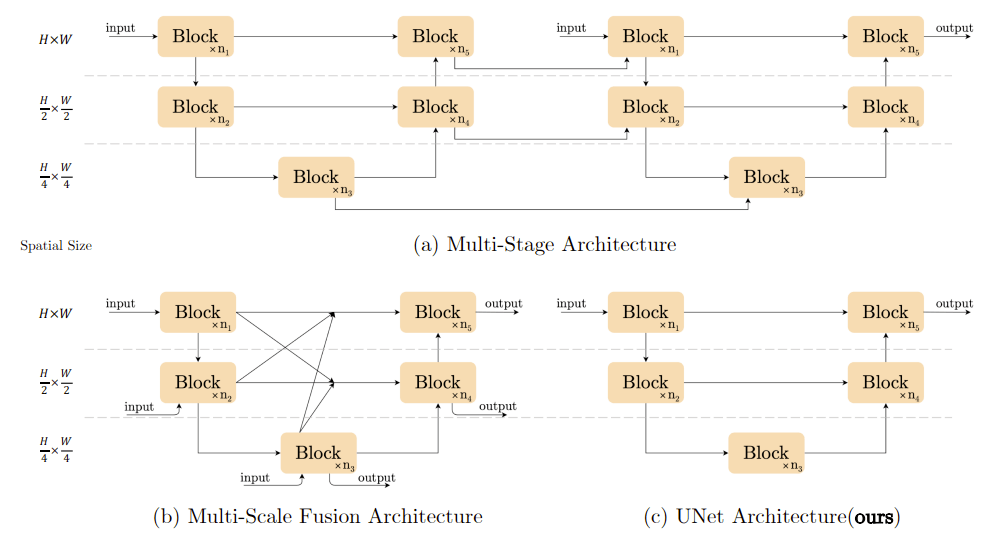
- (a)エンコードとデコードを繰り返す複数ステージの構造。後段のステージで細かい特徴を洗練させていく。
- (b)エンコーダとデコーダの間のスキップ接続の複雑さ。単純なスキップコネクションにはせずに、さまざまな特徴量の混交処理を加える。
本手法ではこういった複雑なブロック間構造を採用せず、単純なUNet構造(c)を採用している。
ブロック内の複雑さの低減
まず、既存の先端的な手法とオリジナルのUNetで使われるブロックの比較を行う。
Restformerで使われるブロック(a)は、TransformerによるSelf AttentionやLayer Normalizationなどが使われていることがわかる。
これと比べると、UNetのブロック(b)はいかにも単純であることがわかる。
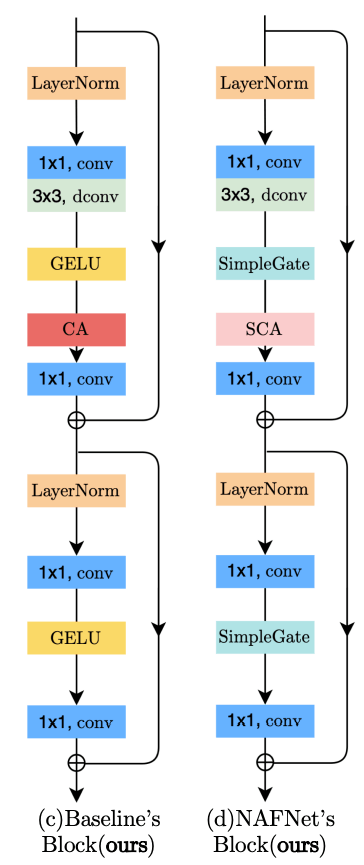
本研究では、UNetのブロックをベースとして最近の進展を取り入れることで(a)よりもはるかにシンプルなブロックでありながら同等以上の性能を達成できるようになっている。
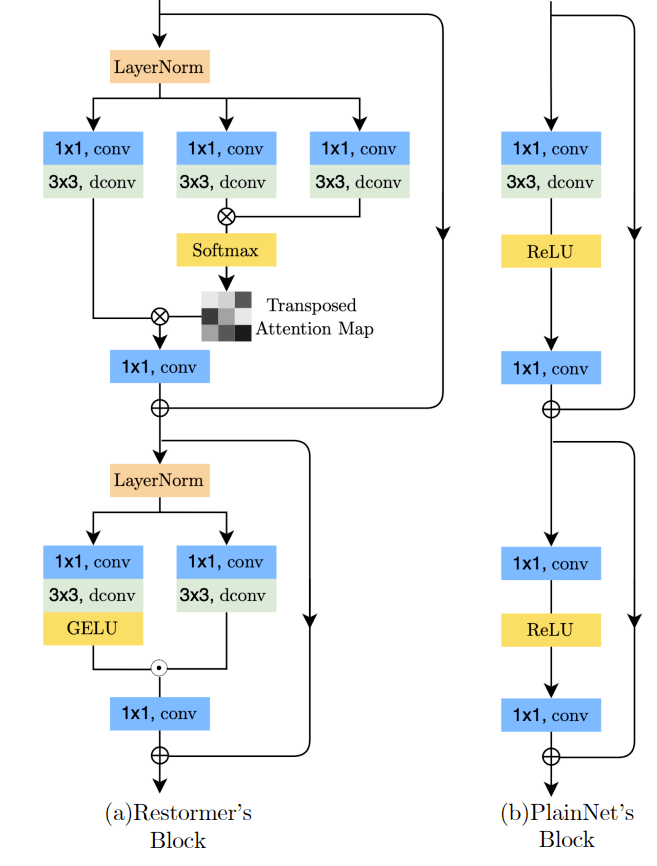
これによって、ブロックは以下の(c)のような構造になる。

性能的には、SIDD(ノイズ除去), GoPro(ブラー除去)においていずれもシンプルなUNet(PlainNet)から向上する。
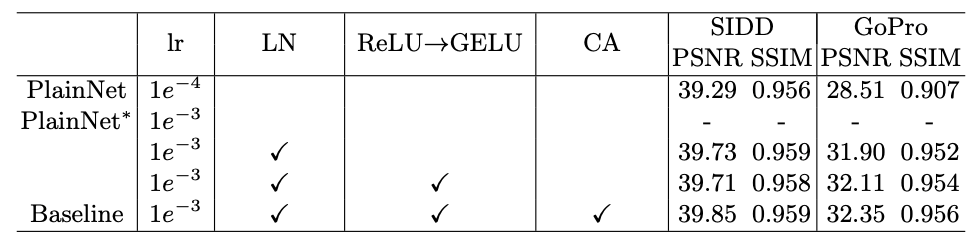
また、この時点で多くの既存手法を上回る性能を獲得できることが、実験によって確かめられている。
ベースライン
まずは、Layer Normalization、GeLU, Channel-Attentionを導入する。
- 近年実績のあるLayer Normalizationを正規化として導入
- 近年ReLUから置き換わりつつあるGeLUを導入
- TransformerによるSelf-Attentionと似たような効果を得るために、Channel-Attentionを採用している。
- Transformerそのものは2次の複雑さを持つので不採用とし、それに対象するためのwindowベースのSelf-Attentionも採用しない。
- 局所的な特徴の相互作用は、depthwise convolutionによって実現し、画像復元で実績のあるChannel-Attentionを採用する。
- Transformer系とConv系どちらが良いかは、本研究のスコープではないのでこれ以上の深入りは避けている。
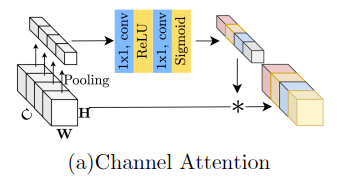
Channel-Attentionは以下のような構造になっている。
GeLUをSimpleGateへ置換
ベースラインは近年の工夫を取り込んだ形になっているが、ここからさらに複雑さを軽減できないかを検討している。
その対象として、GeLUとChannel-Attentionの簡素化を試みている。
まず、GeLUは以下のような形の活性化関数である。
ここで、Gated Linear Unit(GLU)について考える。GLUは以下のように表現されるゲート構造である。
上式と見比べると、
さらに、
また、さらにシンプルにするために、特徴マップをチャネル次元で2つ(
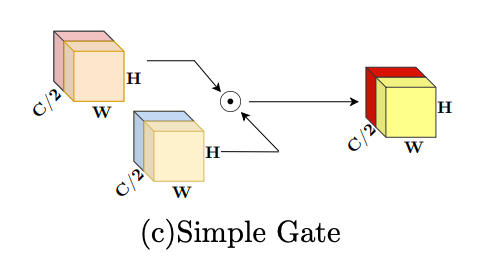
SimpleGateに関しては、より一般的に非線形活性化

Simplified Channel-Attention
次に、Channel-Attentionの簡素化を考えている。
Channel-Attentionは以下のように表現される。
ここで、
SCAの導入は、元のCAからの性能を維持しつつ、ブロック内の複雑さを低減させることに成功している。
以上の2つの簡素化によって、ブロック構造は以下のようになった。このブロックを用いたネットワークには一切の非線形活性化関数が含まれていないため、NAFNet(Nonlinear Activation Free Network)と名づけている。
実験
SIDD(ノイズ除去)およびGoPro(ブラー除去)の結果は以下の通り。


ネットワークのスケーリングとして、ブロック数をいくつ使うかというハイパーパラメータがある。既存手法と同等以上の性能を発揮するブロック数において、計算量(GMACs)は既存手法よりも小さいことを確認している。


また、詳細は省くが、Raw画像のノイズ除去やJPEG画像のノイズ除去に関しても実験を行っている。
Discussion