【論文5分まとめ】Deep Hough-Transform Line Priors

概要
微分可能なHough変換と逆Hough変換を実現するモジュールHT-IHT Blockを提案している。本研究がメインとしているタスクはワイヤーフレームの推定であり、とくに教師データが少ない時のPriorとして機能することが具体的な実験によって示されているが、本稿では特定のタスク向けの詳細は省略する。
書誌情報
- Lin, Yancong, Silvia L. Pintea, and Jan C. van Gemert. "Deep hough-transform line priors." European Conference on Computer Vision. Springer, Cham, 2020.
- ECCV2020
- https://arxiv.org/abs/2007.09493
- 公式実装
ポイント
Recap: Hough変換の流れ
画像中のある直線は、Houghドメインの特定の
-
\rho -
\theta 0 \pi -
\rho, \theta \rho \theta
画像中の座標
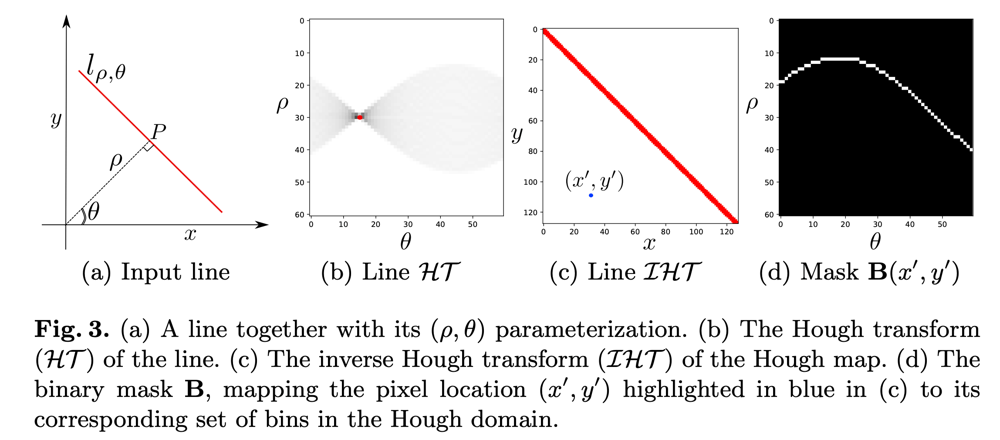
以上のような対応づけによるHoufh変換の流れを図示すると以下のようになる。
- (a)は入力画像中の線分を表し、この直線上の点
(x, y) (\rho, \theta) - (b)はHoughドメインにおける投票数を表し、投票数が非常に多い点以外を抑制すると、赤い1点が得られる。
- (c)はHoughドメインにおいて支配的だった点に対応する直線を表す。
- (d)は、(c)におけるある点
(x', y') (x', y') (\rho, \theta)
HT-IHT Block
本研究では、
本手法では、投票の重みとして入力された特徴マップ
バイナリマップ
一方、逆Hough変換は、下式によって行われる。ここで、
Hough変換と同様に、
一般的なHough変換では、Houghドメインで支配的な点のみを抽出することが多い。似たようなフィルタリング機能を、本手法では1次元Conv層によって実現する。

実験
HT-IHT Blockが標準的な2次元Conv層よりも優れていることを確認するため、簡単なダミーデータによる実験を行っている。
この実験の目的は、ダミーデータに対する高精度なモデルを構築することではない。出力が直線のみから構成されるというPriorを、HT-IHTによって表現できることを確認することを目的としている。
下図の一番左の画像が入力された時に、直線の要素である2列目の画像を出力できるかを、3種類の非常に薄いネットワークで比較している
- Local-only:3x3Conv -> ReLUのみ
- Global-only:
\mathcal{HT} \mathcal{IHT} - Local+Global:Global-onlyの出力を元の入力画像に対して掛ける。これにより無限に続く直線ではなく、線分に限定できる。
Local+Globalがもっとも良いAverage Precisionを達成でき、HT-IHT Blockによって3x3Convよりも直線要素を綺麗に抽出できることが確認できている。

Discussion