【論文5分まとめ】Deep Mutual Learning
概要
通常の蒸留のような教師と生徒の間で行われる学習とは異なり、生徒同士で協力して学習する枠組みであるDeep Mutual Learningを提案している。
書誌情報
- Zhang, Ying, et al. "Deep mutual learning." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
- https://arxiv.org/abs/1706.00384
ポイント
2つのネットワークの訓練
下図に示すように、通常の分類損失に加え、2つのネットワーク

このようなシナリオは、より多くの生徒ネットワーク
- 1つ目は、自分以外のネットワークの出力とのKL距離をそれぞれ出し、それらを平均する方法である。
- 2つ目は、自分以外のネットワークの出力の平均とのKL距離を出す方法である。
それぞれの損失関数は以下のようになる。
先に結論を述べておくと、前者の方法の方がより良い精度が得られることが、実験によって明らかになっている。
実験
実験は、CIFAR-100およびMarket-1501で行っている。以下の疑問への回答が示されている。
- DMLの効果はどうか?
- DMLは蒸留よりも優れているのか?
- ネットワークの数を増やした時の効果は?
- ネットワークの数が多い時の損失はどうすべきか?
DMLの効果
以下は、CIFAR-100での実験結果を表した表である。DMLはそれぞれのネットワークを個別に訓練した時よりもより良い精度が得られる、ということがわかる。
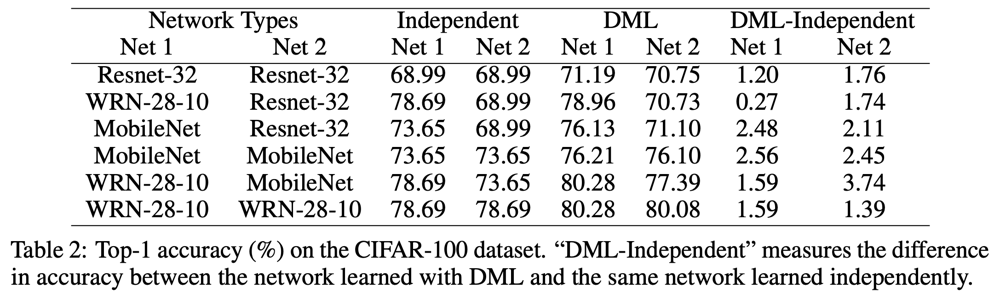
同様に、Market-1501での結果は以下の表のようになっている。こちらでも、DMLの導入により、精度が一貫して向上することが示されている。

蒸留とDMLの比較
一般的な蒸留と同じように、1つ目のネットワークを教師モデルとして、2つ目のネットワークを生徒モデルとして訓練している。その場合とDMLを使用して訓練したモデルと比較すると、DMLを使用した場合の方が良い精度が得られている。

ネットワーク数の影響
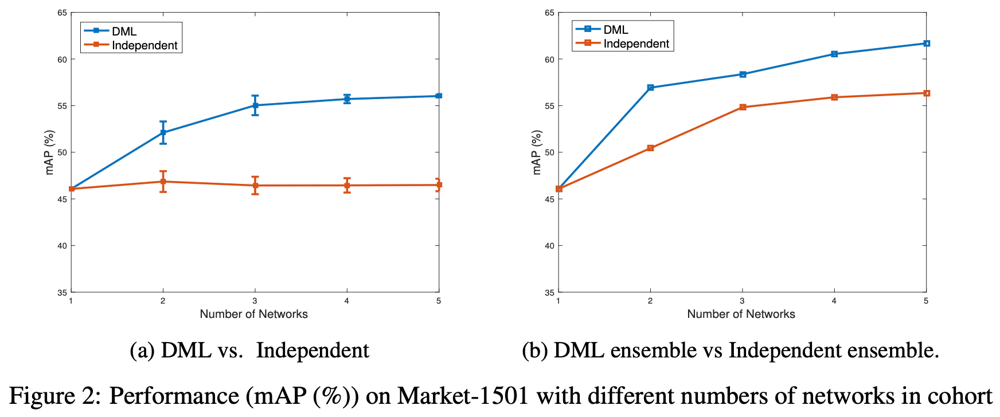
(a)ネットワーク数を増加させたとき、個別に訓練した場合は、その平均精度は当然横ばいになる。一方で、DMLを用いると同時に訓練するネットワークの数を増やすことで、明らかに個別に訓練した場合よりも高精度になることがわかる。
(b)複数のネットワークを個別に訓練しても、その出力を平均してアンサンブルしてあげれば、一般的に精度は向上する。DMLでもアンサンブルは有効で、個別に訓練したモデルのアンサンブルよりもDMLで訓練したモデルのアンサンブルの方が良い精度が得られている。
ネットワーク数が多いときの損失関数
ネットワークの数

そもそも蒸留は、通常のone-hotターゲットでは与えられない2位以下の確率を教師信号として与えることによって、モデルを大域最適化することができる。DMLではその効果がさらに強く与えられることで、大域最適解が得られていると考えられる。
一般に、アンサンブルしたモデルは高い精度を実現できるが、DML_eの場合はこれが裏目に出ている。DML_eがDMLに比べて悪い精度になってしまうのは、アンサンブルによって得られる確率分布が鋭いピークをもつため、DMLが本来与えられるはずの2位以下の重要な情報を低減させてしまうことが原因と考えられる。
Discussion