【論文5分まとめ】Deep Supervised Hashing Based on Stable Distribution
概要
画像検索のために画像特徴量をバイナリ化するDeepHashの一手法であるDSHSDを提案。既存の手法を大きく上回る性能を達成。
書誌情報
- Wu, Lei, et al. "Deep supervised hashing based on stable distribution." IEEE Access 7 (2019): 36489-36499.
- https://ieeexplore.ieee.org/document/8648432
ポイント
前提となるネットワーク構造を以下に示す。このネットワーク構造である理由は、既存手法との比較のためであり、特徴抽出を行うネットワーク構造は何でも良い。
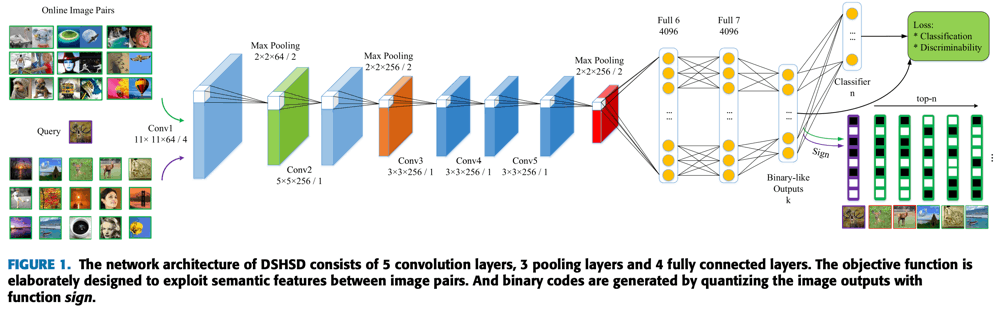
重要なのは、出力付近にあるLinear層とSign操作によるバイナリ化、および損失である。
処理の流れ
入力画像
訓練時は
推論時は
損失関数
訓練時に使用する損失関数は、理想的には以下のような形で考えられる。
-
\mathcal{S} \boldsymbol{I}_{i} \boldsymbol{I}_{j} -
m m k
しかし、この損失関数は、離散化操作が途中にあることにより最小化が難しい。そこで、既存の手法では、
量子化正則化は一見よさそうに思えるが、画像特徴量

このような問題を回避するために、本研究ではStable分布という概念を導入している。厳密な定義は論文中に記載されているが、要するに、単峰の分布を保てるように、
実際、このような損失関数に変更することで、
最終的な損失関数は以下のようになる。分類損失
実装は簡単
非公式実装を見てみるとわかるが、DSHSDは以下のとおり非常にシンプルに実装できる。
DSHSD
class DSHSDLoss(torch.nn.Module):
def __init__(self, config, bit):
super(DSHSDLoss, self).__init__()
self.m = 2 * bit
self.fc = torch.nn.Linear(bit, config["n_class"], bias=False).to(config["device"])
def forward(self, u, y, ind, config):
u = torch.tanh(u)
dist = (u.unsqueeze(1) - u.unsqueeze(0)).pow(2).sum(dim=2)
s = (y @ y.t() == 0).float()
Ld = (1 - s) / 2 * dist + s / 2 * (self.m - dist).clamp(min=0)
Ld = config["alpha"] * Ld.mean()
o = self.fc(u)
if "nuswide" in config["dataset"]:
# formula 8, multiple labels classification loss
Lc = (o - y * o + ((1 + (-o).exp()).log())).sum(dim=1).mean()
else:
# formula 7, single labels classification loss
Lc = (-o.softmax(dim=1).log() * y).sum(dim=1).mean()
return Lc + Ld
実験
詳細は省く。
- CIFAR-10, NUS-WIDE, ImageNetで検索し、TopNのPrecisionの平均値であるMAPで評価している。
- CIFAR-10での実験から
\alpha - ビット数
k - 既存の手法と比較し、安定して高いMAPが得られることを確認している。
Discussion