この記事はdbt Advent Calendar 2022の12月1日の記事です。
サマリ
- DuckDBとdbtを使えばローカル環境で一定のデータ量であればオレオレDWHっぽいものが作れるようになる
- 社内にデータ分析基盤がない、データ活用しようにもデータ基盤がなく本格的に取り組もうと思うとセキュリティや運用までかんがえると始めることすらままならないようなプロジェクトや会社でも始められる可能性がある
- MLのデータの前処理とdb Pythonモデルを使ってローカル環境で一定のクレンジングと前処理のパイプライン等も作れるかも?

DuckDBとは?
SQLiteをベースとした軽量で高速なOLAPデータベースです。
近年のPCのメモリ増加で16GBとか乗っていると数百万行ぐらいのデータでもローカルで高速に一定処理することが可能になってしまっています。
詳しくは @notrogue さんが書いた記事を拝見するのが良いです。
dbtのインストール
dbt Core(CLI版)をインストールします。
詳しくは他の記事に任せます。
データの準備
サンプルデータの用意
今回はKaggleのE-Commerce Dataをサンプルにやってみます。
登録して手元にダウンロードしてみましょう。
以下のようなデータが入っています
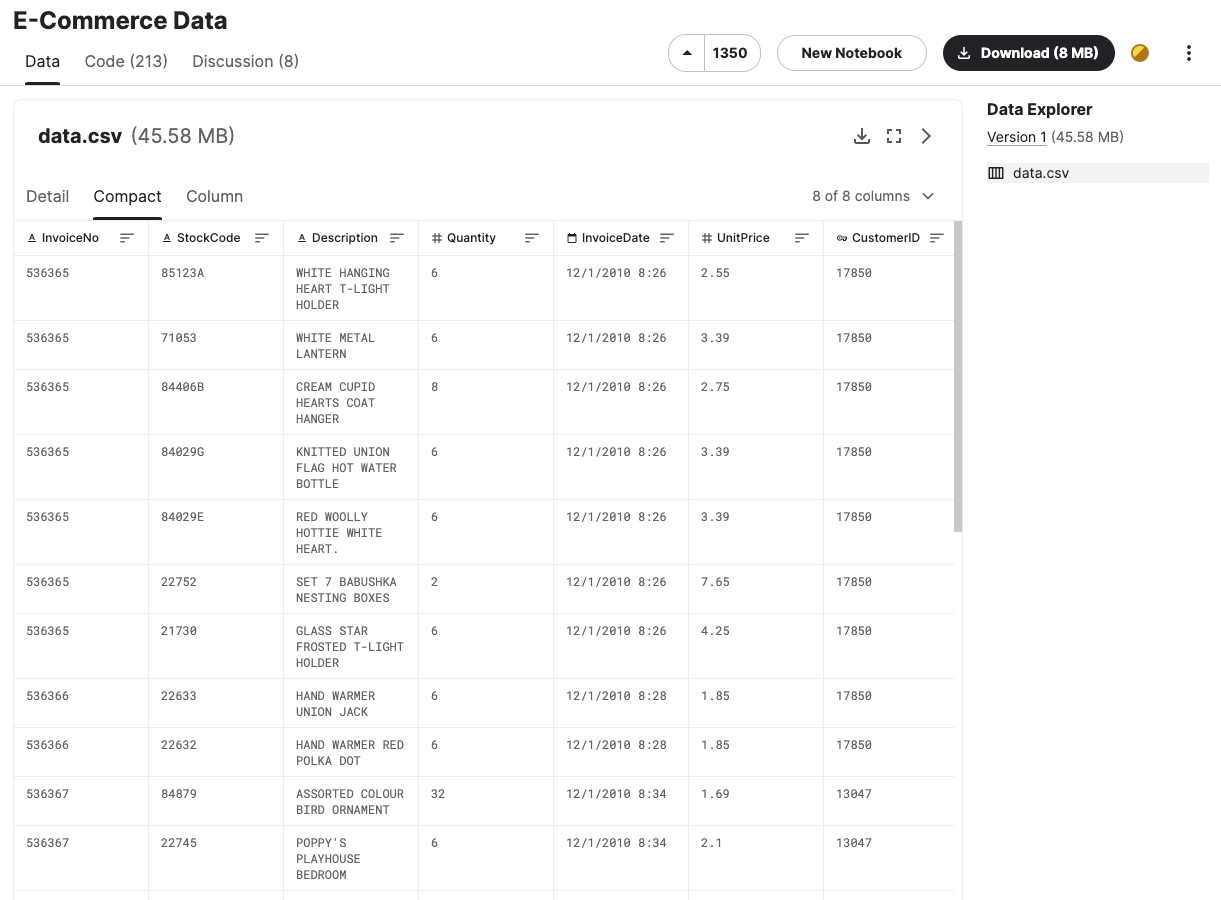
今回は試しやすいようにduckdbの同じフォルダに置いたと仮定して進めます
DuckDBのインストール
CLI版をインストールしましょう。
以下のURLから「CLI」自分のOSを選んでダウンロードしましょう。
ダウンロードし、解凍して展開されたファイルがアプリケーションになります。

DuckDBの起動
以下のコマンドで起動できます。
第1引数にファイル名を渡すとメモリー上での動作モードではなく、永続的なデータ読み書きをするようになります。
./duckdb dbt.duckdb
動くか試してみる
D select 'dbt';
無事に動いたようです。

DuckDBでサンプルデータを操作してみる
read_csv_autoで良い感じに読み込んでくれます。
基本varcharで読み込み、staging層でうまく処理できればよいのでautoでも良さそう。
D create table raw_ecommerce as select * from read_csv_auto('ecommerce.csv');
D select * from raw_ecommerce;

dbtのプロジェクトをDuckDBで動かすための「dbt-duckdb」
dbt-bigquery等と兄弟なようなもので、DuckDBをベースに動くdbtのプロジェクトを作成することが出来るようになります。
$ pip3 install dbt-duckdb
dbtでマートを作ってみる
この記事では詳しく触れませんが、以下のベスプラに沿ってみても良いと思います。
初期セットアップ
dbt initでduckdb用のdbtプロジェクトを作りましょう
$ dbt init duckdbtsample
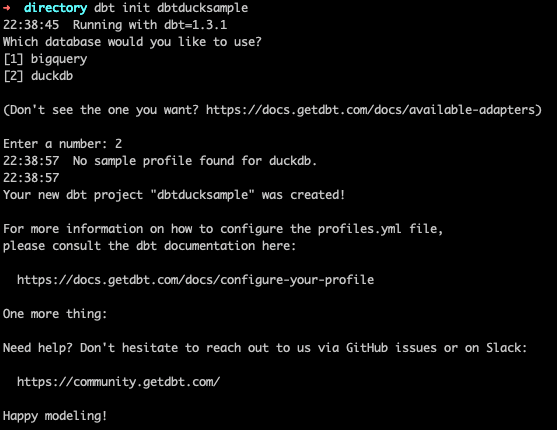
profile名はユニークなものをつけましょう
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'duckdbsample'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'duckdbsample'
先程作った
duckdbsample:
outputs:
dev:
type: duckdb
path: /Users/local/directory/dbt.duckdb
target: dev
モデル周りの開発
この記事では詳しく触れませんが、以下のベスプラに沿ってみても良いと思います。
version: 2
sources:
- name: main
tables:
- name: raw_ecommerce
select
"Ship Date" as ship_date,
"Order ID" as order_id,
"Customer Name" as customer_name,
"Country" as country,
"Region" as region,
"State" as state,
"City" as city,
"Order Date" as order_date,
"Product" as produxt,
"Sales" as sales,
"Quantity" as quantity,
"Discount" as discount,
"Profit" as profit,
"Segment" as segment
from {{ source('main', 'raw_ecommerce') }}
locationにファイルパスを指定することで実行結果がローカルのファイルにも書き出されます
{{ config(
materialized='external',
location='/Users/local/directory/export_data/fact_orders.csv',
format='csv'
) }}
select *
from {{ ref('staging_ecommerce') }}
全モデルを処理しておきましょう
$ dbt run
ローカル環境で動作するシンプルBIツールの「Rill」
RIllはSQLベースのデータモデラー、リアルタイムデータベース、メトリクスダッシュボードを提供する製品です。機能もシンプルですが、高速にローカル環境でも動作します。
Rillのインストールと起動
Developer版がFreeで使用できます
$ curl -s https://cdn.rilldata.com/install.sh | bash
インストールした後にターミナル等で以下のコマンドを打つとブラウザにツールが立ち上がります
$ rill start
Rillでfact_ordersを元にダッシュボードを作ってみる
立ち上がったツールでソースを追加します。

Rillは以下のような機能でデータを設定します
- 「モデル」
- ソースデータを一定の条件で絞り込んだり、必要なカラムに絞ったりして大福帳的なデータとしてデータを固めます。今回の例ではfact_ordersをそのままで良さそうです
- 「ダッシュボード」
- メトリクスとディメンジョンを定義して集計軸を定義します
それぞれを登録すると以下のようなダッシュボードが作成できます!お手軽!
またRillは各カラムのデータの統計量等も表示してくれるのでさくっと探索的にデータを見たいようなユースケースにもマッチしそうです。


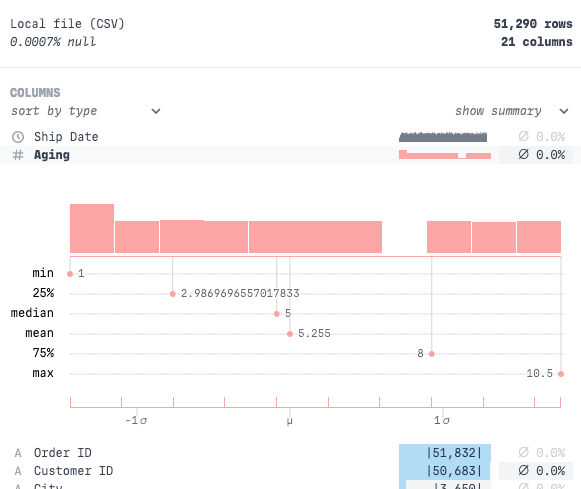
この記事で紹介できなかったこと
- より実践的なデータを例にしたユースケース
- DuckDBの詳細な機能
- Rillの機能紹介(もっと説明したいことがある)
まとめ
いかがでしたでしょうか?
実際のユースケースでどの程度耐えられるか、また実運用をしていこうとなると課題になることもCDW等で運用する場合とは違うものも出てきたり、超大規模なデータや多くの人が使う前提のDWHの構築はもちろん難しい場面もありそうですが、一定の可能性を感じる事が個人的には出来ました。

Discussion