モジュラリティ最大化の計算を例に定式化の違いを見る (数理最適化 Advent Calendar 2022)
Twitter: @cocomoff / Zenn: @takilog です。本記事は 数理最適化 Advent Calendar 2022 の15日目の記事として書きました。今年、お仕事(研究)でいろんな最適化問題を見ていて、定式化のあーだこーだで悩むことが多かったので気分転換で書いている側面もあります。
はじめに
普段、職場のメンバと論文などを紹介しあう会を不定期にやっています。ある回でこの2本の論文を紹介しました。中身はこの記事には関係ないので一言コメントだけ付けておきますね(興味のある人は論文も見てみてください)。
- Gaurav Agarwal and David Kempe, Modularity-maximizing graph communities via mathematical programming, The European Physical Journal B 66, pp.409-418, 2008
- (一言でいうと)LPやQP、階層的なアルゴリズムなどを通じてモジュラリティ最大化によるコミュニティ検知についてまとめられている論文です。
- Filipi N. Silva, Aiiad Albeshri, Vijey Thayananthan, Wadee Alhalabi, and Santo Fortunato, Robustness modularity in complex networks, Physical Review E 105, 054308, 2022
- (一言でいうと)通常のモジュラリティはある程度意味のない構造でも数値が出ることがあるので、null modelを設定してランダム性に基づき、モジュラリティの計測にロバスト性を入れる手法についての話です。
ここで出てくるグラフのモジュラリティ (Modularity) はネットワーク解析でコミュニティ構造(頂点の分割のこと)を定量化したり議論するためによく使われる量です。式の真面目な解説はネット上の記事か、上の Wikipedia の記事などを参考にしてください。
簡単なイメージだけ考えると、ある2つの頂点
定式化の比較
上の論文を読んでいて、論文の定式化とUme本[1]の定式化が異なっていたので、面白いなと思って比較してみることにしました。
論文の説明
論文の通り説明します(記号は適当に変えています)。
無向グラフ
このとき、モジュラリティ最大化によるコミュニティ発見問題の目的関数と制約は以下の通りです。
- 目的関数
- 制約条件
- 変数の解釈:
x_{u, v} = 0 u v
以上の設定の下で、制約は次のように解釈できます(読まなくていいです)。
解釈
- もし
u w u w v 1 x u u w x, v, w u, v, w - もし
u w u, v, w - こんなのでうまく行くんですかね?不思議ですね〜(雑)。
Ume本の説明
この記事を読む人はおそらく本を所持していると思いますので(???)詳細は本を読んで頂くとして、このように分解された式で不等式制約を書いています。ついでに目的関数も
- 目的関数
- 制約条件
- 変数の解釈:
x_{u, v} = 1 u v
こちらの制約は次のように解釈できます(本のコピペです)。
解釈
- 制約1だけを考えます。これは「もし
u v v w u v -x_{u,w} - 制約2と3も同じ考え方です。
実装・実行結果
これまでの説明を振り返ると、
論文モデルの実装
式では for all しか書いていないところでこのような実装スタイルにしました(正しいかどうかは…?論文はこれだからダメです!)。
n = G.number_of_nodes()
m = G.number_of_edges()
nodes = list(G.nodes())
A = nx.adjacency_matrix(G).todense()
M = {(u, v): 0 for (u, v) in product(nodes, nodes)}
for i in nodes:
for j in nodes:
Aij = 1 if j in G[i] else 0
M[i, j] = Aij - G.degree(i) * G.degree(j) / (2 * m)
# solve
model = P.LpProblem("max-modularity", sense=P.LpMaximize)
x = P.LpVariable.dicts("x", (nodes, nodes), 0, 1, cat="Integer")
model += P.lpSum(M[i, j] * (1 - x[i][j])
for (i, j) in product(nodes, nodes)) / (2 * m)
for (i, j, k) in product(nodes, nodes, nodes):
if len(set({i, j, k})) == 3: # ここは適当です
model += x[i][k] <= x[i][j] + x[j][k]
solver = P.SCIP(msg=0)
model.solve(solver)
Ume本モデルの実装
次はUme本の実装ですが、こちらは
n = G.number_of_nodes()
m = G.number_of_edges()
A = nx.adjacency_matrix(G).todense()
M = {(u, v): 0 for (u, v) in product(range(n), range(n))}
for i in range(n):
for j in range(n):
Aij = 1 if j in G[i] else 0
M[i, j] = Aij - G.degree(i) * G.degree(j) / (2 * m)
# solve
model = P.LpProblem("max-modularity", sense=P.LpMaximize)
x = P.LpVariable.dicts("x", (range(n), range(n)), 0, 1, "Integer")
obj1 = P.lpSum(M[i, j] * x[i][j]
for i in range(n) for j in range(i + 1, n)) / m
obj2 = P.lpSum(M[i, i] * x[i][i] for i in range(n)) / (2 * m)
model += obj1 + obj2
# 後で考えたら (u, v, w) にしたほうが良かった…
for i in range(n):
for j in range(i + 1, n):
for k in range(j + 1, n):
model += x[i][j] + x[j][k] - x[i][k] <= 1
model += x[i][j] - x[j][k] + x[i][k] <= 1
model += -x[i][j] + x[j][k] + x[i][k] <= 1
solver = P.SCIP(msg=0)
model.solve(solver)
あとは動かしてみるだけですね。
動作確認
上のコードを実際に動かします。
0-1の整数計画問題のため、小さめのグラフで動作を確認することにします。0-1の整数計画問題を連続緩和して丸めながら解く方法なども論文に紹介されていますので、興味がある方はそちらも確認してみてください。実際に実装してみると、そこそこの近似解が出ました。
karate club
有名なグラフデータです。
コミュニティ検知の手法自体は、networkxに実装されているヒューリスティクス や貪欲法が使えるので、それらも適用した上で結果を出力してみました。ネットワークの可視化が適当でpulpの解だけ見た目が変わってしまっています。
良さそうな感じですね。
| 貪欲法 | もっと賢いやつ (Louvain) | pulpの解 |
|---|---|---|
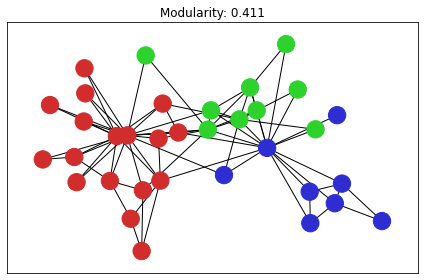 |
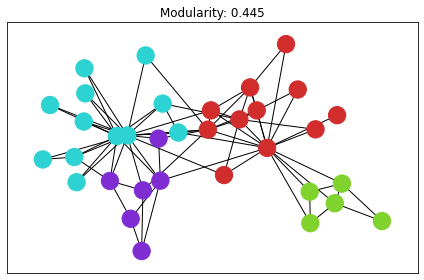 |
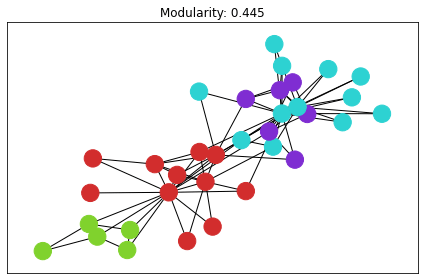 |
random geometric graph
ランダム幾何グラフでも動かしてみます。サイズ
G = nx.random_geometric_graph(N, 0.55)
サイズ
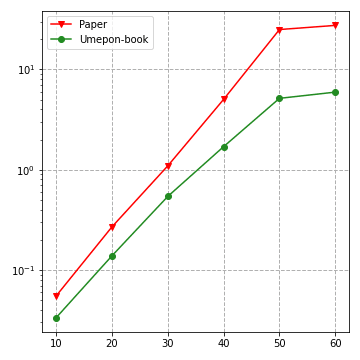
結果を見ると、安定してUmepon-bookのモデルの方が高速に計算できた様子です。制約が良かったみたいですね。このように同じ問題の実装でも制約をうまく設定して実行可能領域などをいい感じに表現できていると、結果に響いてくるわけですね。しっかり制約を準備しましょう!(雑)。
まとめ
モジュラリティ最大化ぐらいメジャーな問題だと、良い多面体を表現する不等式を世の中の人が考えていると思います。論文を探すと見つかる可能性が高いでしょうか。
一方で、企業の謎にカスタマイズされたものは望み薄でしょうか。原理検証で汎用の数理最適化ソルバーを使うことは多いと思うので、そのまま力づくでソルバーに投げてポイっとやってしまうしかないですね。難しいですね〜(雑)。これからもいろいろと頭を悩ませながら仕事することになりそうです。
来年こそは真面目な記事を書くつもりでいます(フラグ)。
-
梅谷先生の最適化本のことです(しっかり学ぶ数理最適化)。 ↩︎
Discussion