MLモデルをデータ毎に並列で扱おう on Snowflake
概要
こんにちは!SnowflakeのML機能使っていますか?
Snowflakeで機械学習する意味ってあんま無いよね(他に使いやすいサービスあるし。。。)、というのはちょっと前の話。
最近はSnowflakeで実装する意味も増えてきたなと感じています。
私の感覚では、SnowflakeのML機能は特に「楽に実装できる」という点にフォーカスが当たっているような気がしており、「便利な機能が少量のコードで実現できる」という体験が多いです。
先日Many Model Training(MMT)というこれまた便利な機能が提供されたので、早速使ってみます。
Many Model Training
つまるところ、こんな機能です。
「Snowflakeのテーブルの中からデータを取得し、特定の列の値ごとにMLモデルを作ります」
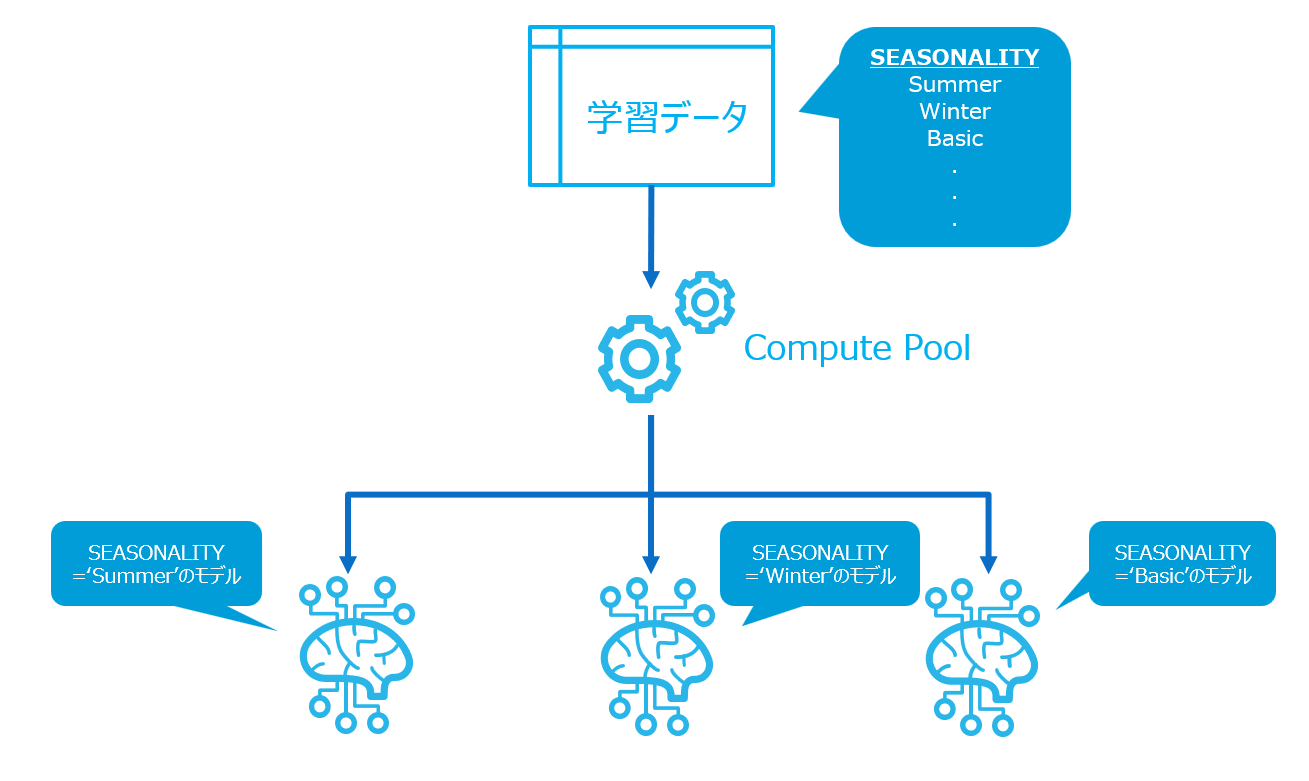
とあるコンビニで商品の販売数を予測するMLモデルを作るとします。
説明変数を持った学習データの中にSEASONALITYという列があります。
この列は商品ごとの販売傾向のうち、季節性を表す列です。
SEASONALITY='Summer'の商品は夏に売れやすいアイスや冷やし中華等です。また'Winter'の場合は反対に冬に売れやすいホットコーヒーやおでん等となっています。'Basic'はそのような季節性があまりないおにぎりのような商品が入っているとします。
今回はこのSEASONALITYごとにMLモデルを作成します。
つまり、「夏商品モデル」「冬商品モデル」「通常品モデル」の3つが出来上がるイメージです。
SnowflakeのMany Model Trainingを使うと、一回の実行でこの3つのモデルを並列に学習させることができます。
MLモデル学習
コードの全体像
いきなりですが、コードを書きます。
ちょっと長いのでアコーディオンです。
Many Model Training
# -------------
# import
# -------------
import pandas as pd
import numpy as np
import pickle
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import root_mean_squared_error
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark import Session
from snowflake.ml.runtime_cluster import scale_cluster
from snowflake.ml.modeling.distributors.many_model import ManyModelTraining
from snowflake.ml.utils.connection_params import SnowflakeLoginOptions
from snowflake.ml.modeling.distributors.distributed_partition_function.dpf import DPF
from snowflake.ml.modeling.distributors.distributed_partition_function.entities import RunStatus
session = get_active_session()
# -----------------
# 学習データ取得
# -----------------
train_data = session.table('sales_data')
# ---------------------
# MMT対象の関数を定義
# ---------------------
def train_xgboost_model(data_connector, context):
def cast_to_category(df:pd.DataFrame, cols:list)-> pd.DataFrame:
for col in cols:
df[col] = df[col].astype('category')
return df
def objective_xgb(trial):
'''
optunaの目的関数
'''
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 150),
'max_depth': trial.suggest_int('max_depth', 3, 12),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
'colsample_bynode': trial.suggest_float('colsample_bynode', 0.5,1.0),
'min_child_weight': trial.suggest_int('min_child_weight',1, 12),
'gamma': trial.suggest_float('gamma', 0.0, 5.0),
'reg_alpha':trial.suggest_float('reg_alpha', 0.0, 1.0),
'reg_lambda':trial.suggest_float('reg_lambda', 0.0, 5.0),
}
model = XGBRegressor(**params,
tree_method='hist',
enable_categorical=True,
objective='reg:squarederror',
eval_metric='rmse'
)
model.fit(X, y, eval_set = [(X_val, y_val)])
preds = model.predict(X_val)
rmse = root_mean_squared_error(y_val, preds)
return rmse
### ここからが処理内容 ###
# log
print(f"Training model for partition: {context.partition_id}")
df = data_connector.to_pandas() # SnowparkからPandasに持ち直し
# 型の変換
cat_cols = ['WEEKDAY_CODE', 'MONTH', ... ]
df = cast_to_category(df, cat_cols)
### こんな感じで、###
### Pandasに持ち直してから実施したい処理はここに書いていきます ###
# データ分割
df_train, df_valid = train_test_split(df, test_size=0.2, random_state=seed)
X = df_train.drop(columns=['PRODUCT_CODE','DATE','SEASONALITY',...])
# 説明変数に使用しない列を落とします
# partitionに使っているSEASONALITYは説明変数には使いません
y = df_train['SOLD_QUANTITY'] # 今回の目的変数列
X_val = df_valid.drop(columns=['PRODUCT_CODE','DATE','SEASONALITY',...])
y_val = df_valid['SOLD_QUANTITY']
# XGBoost + Optuna
study = optuna.create_study(direction='minimize')
study.optimize(objective_xgb, n_trials=20)
best_params = study.best_params
best_params.update({
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'tree_method': 'hist',
'enable_categorical': True
})
best_model = XGBRegressor(**best_params)
best_model.fit(X, y, eval_set = [(X_val, y_val)])
return best_model # MMTの出力
# Compute poolのスケールを指定する場合はこんな感じで書きます
scale_cluster(2)
# ---------------
# MMT実行
# ---------------
trainer = ManyModelTraining(train_xgboost_model, "DEMO_DB.DEMO_SCHEMA.DEMO_STAGE")
training_run = trainer.run(
partition_by="SEASONALITY",
snowpark_dataframe=train_data,
run_id= "seasonality_model_v1"
on_existing_artifacts='overwrite'
)
final_status = training_run.wait()
実行するとこんなプログレスバーが出ます。

データをコンピュートプールに取り込む部分と、学習の部分が別々に表示されます。
(そしてこのプログレスバーはちょこちょこ表示がおかしくなります)
今回はクラスター数を2に設定したので、それぞれのノードのCPUとメモリの状況をリアルタイムで表示してくれます。これは便利。
クラスター数を2に設定しても、必ず2つ使われるわけではなく、一つのノードで処理できる分の処理量であれば一つのノードだけがビジーになるようです。
それではコードの詳細を見ていきます。
実行環境 (もとい必要なもの)
- Snowflake Notebook
- Compute Pool
- 内部ステージ
MMTはコンテナランタイムの環境が必要です。コンピュートプールは普段使っているサイズで大丈夫です。
実行に際して内部ステージが必ず必要です。事前に準備しておきます。
コード内で使用するOptunaはpip installが必要です。
データ
MMTを使うにはある程度整形済みのデータがテーブルとして存在している必要があります。
今回は冒頭で触れたコンビニの販売数量を予測するイメージでデータを作成しました。
以下の列を持っています。
- PRODUCT_CODE (商品コード)
- DATE(日付)
- SOLD_QUANTITY(販売数量の実績値)
- SEASONALITY(商品の季節性を表すラベル)
- WEEKDAY_CODE(曜日)
- MONTH(月)
- その他説明変数
時系列データをxgboostで予測するので、SOLD_QUANTITYのLAGとかを加えています。
ここまではテーブルとして用意しておいて、Snowpark DataFrameとして扱います。
train_data = session.table('sales_data')
MMTの本体
ちょっと飛ばして最後のほうに行きます。
以下がMMTを実行する部分になります。
ManyModelTrainingに渡しているtrain_xgboost_modelは後述する自作関数です。
また第二引数は内部ステージ名です。このステージ内にログや作成したモデルのpklファイルが格納されます。
trainer = ManyModelTraining(train_xgboost_model, "DEMO_DB.DEMO_SCHEMA.DEMO_STAGE")
training_run = trainer.run(
partition_by="SEASONALITY",
snowpark_dataframe=train_data,
run_id= "seasonality_model_v1"
on_existing_artifacts='overwrite'
)
final_status = training_run.wait()
run()メソッドでpartition_byに指定した列の値ごとにモデルが作成されます。
run_idはそのままステージ内に作成されるフォルダ名になるので、分かりやすくしておくと良いと思います。
ステージ内にrun_idと同じフォルダが存在している場合はMMTの実行はエラーになります。
上書きしても良い場合のみon_existing_artifacts='overwrite'とすることで、ファイルが上書きされ、エラーを吐かなくなります。
実行関数
MMTで分割されるデータの単位はパーティションと呼ばれます。
各パーティションで何を実行するかはある程度自由に書くことができますが、シリアライズ(pickle化)できるものでないと外部の変数や関数を利用することができません。
面倒だったので、各パーティションで実行したい処理は実行関数内にネストして定義しました。
def train_xgboost_model(data_connector, context):
# 中略 #
### ここからが処理内容 ###
# log
print(f"Training model for partition: {context.partition_id}")
df = data_connector.to_pandas() # SnowparkからPandasに持ち直し
# 中略 #
# XGBoost + Optuna
study = optuna.create_study(direction='minimize')
study.optimize(objective_xgb, n_trials=20)
best_params = study.best_params
best_params.update({
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'tree_method': 'hist',
'enable_categorical': True
})
best_model = XGBRegressor(**best_params)
best_model.fit(X, y, eval_set = [(X_val, y_val)])
return best_model # MMTの出力
大事なのは引数として渡しているdata_connectorとcontextです。
data_connectorはrun()の引数で渡したsnowpark_dataframeから各パーティションにフィルターした状態のDataFrameになっています。
またcontextは各パーティションの情報を持っており、分岐処理などに活用できます。
(特定のパーティションだけ特徴量を増やすとか……)
さて、ドキドキの初回実行です。
エラーが出た……

どのパーティションでエラーになったかとか、どんなエラーなのかとかは教えてくれないみたいです。
各パーティションごとのログは引数で渡している内部ステージに保存されています。
@DEMO_DB.DEMO_SCHEMA.DEMO_STAGE/seasonality_model_v1
@DEMO_DB.DEMO_SCHEMA.DEMO_STAGE/seasonality_model_v1/winter
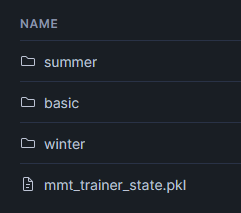

フォルダをディグっていくとtrain.logというファイルがでており、こちらを覗くとエラーの詳細が分かります。
ValueError: DataFrame.dtypes for data must be int, float, bool or category.
When categorical type is supplied, the experimental DMatrix parameter`enable_categorical` must be set to `True`.
すいません、普通にxgboostの使い方を間違えてました。
上記のコードではenable_categorical=Trueにしているので動きます。
とまぁこんな感じで学習まで完了しました。
勝手に内部ステージにモデルが保存されるので助かります。
内部ステージのモデルをモデルレジストリに登録することもできるようですが、今回は割愛。
推論
学習が並列でできたので、今度は推論を並列にしたいですよね。
MMTと同じ仕組みでDistributed Partition Function(DPF)というのも実装されており、こちらはMLモデルの学習以外のことを並列で動かせるようになります。
こちらも先にコードの全体をお見せします。
Distributed Partition Function
def predict_on_dpf(data_connector, context):
def cast_to_category(df:pd.DataFrame, cols:list)-> pd.DataFrame:
for col in cols:
df[col] = df[col].astype('category')
return df
### ここからが処理 ###
df = data_connector.to_pandas()
print(f"predict_on_partition: {context.partition_id}")
session = get_active_session()
session.file.get(f'@demo_db.demo_schema.demo_stage/seasonality_model_v1/{context.partition_id}/model.pkl','/tmp')
local_pkl = '/tmp/model.pkl'
with open(local_pkl, "rb") as f:
model = pickle.load(f)
# 学習時と同様の処理を施す。
# 型の変換
cat_cols = ['WEEKDAY_CODE', 'MONTH', ... ]
df = cast_to_category(df, cat_cols)
# 列の順序を整える
feature_cols = model.get_booster().feature_names
X_test = df[feature_cols].copy()
# 推論
df['PRED_SOLD_QUANTITY'] = model.predict(X_test)
# 予測値をテーブルに書き込み
df['MODEL_NAME'] = 'seasonality_model_v1'
df['VERSION'] = context.partition_id
select = df[['MODEL_NAME','VERSION','DATE','PRODUCT_CODE','PRED_SOLD_QUANTITY']]
session.write_pandas(select, table_name='PRED_RESULTS', schema='DEMO_SCHEMA', overwrite=False, auto_create_table=True)
# --------------------
# DPF実行
# --------------------
dpf = DPF(predict_by_dpf, "demo_db.demo_schema.demo_stage")
run = dpf.run(
partition_by="SEASONALITY",
snowpark_dataframe=test_data,
run_id="test",
on_existing_artifacts='overwrite'
)
final_status = run.wait()
DPFを実行する
まずは最後の方に書いてあるDPFの実行部分を見ます。
dpf = DPF(predict_by_dpf, "demo_db.demo_schema.demo_stage")
run = dpf.run(
partition_by="SEASONALITY",
snowpark_dataframe=test_data,
run_id="test",
on_existing_artifacts='overwrite'
)
final_status = run.wait()
MMTと違いはありません。呼び出すクラスがManyModelTarainingからDPFになっただけです。
predict_by_dpfは自作関数で、各パーティションの中で実行する関数になります。
モデルを呼び出す
predict_by_dpf()の中身を見ていきます。
まずはモデルの呼び出しです。
公式ドキュメントには、以下コードでステージに保存された結果を呼び出すことができるとあります。
# Restore training run from stage
restored_run = ManyModelTraining.restore_from("regional_models_v1", "model_stage")
# Access models from restored run
north_model = restored_run.get_model("North")
south_model = restored_run.get_model("South")
実行してみたところ、エラーが出て使用できませんでした。
AttributeError: type object 'ManyModelTraining' has no attribute 'restore_from'
まぁリリースされたばっかりなので、こういうこともありますね……
でも大丈夫です。モデルは内部ステージにpklファイルとして保存されているので、正攻法で取りに行きます。
session = get_active_session()
session.file.get(f'@demo_db.demo_schema.demo_stage/seasonality_model_v1/{context.partition_id}/model.pkl','/tmp')
local_pkl = '/tmp/model.pkl'
with open(local_pkl, "rb") as f:
model = pickle.load(f)
引数として渡しているcontextを利用することで、各パーティションで使いたいモデルを読み込むことができます。
ちなみにセッションは各パーティションごとに立ち上げる必要があります。DPF実行関数の外部で作成されたセッションはシリアライズできないため、利用することができません。
外で作られたセッションを使おうとすると以下のエラーが出ます。
TypeError: Could not serialize the argument <function predict_by_dpf at 0x7f30e7e70940> for a task or actor snowflake.ml.modeling.distributors.distributed_partition_function.orchestrator_actor.DPFOrchestrator.__init__: ......
推論結果を保存
推論結果は各パーティションごとにテーブルに保存するようにしました。
jsonやcsvで一回内部ステージに置いておくほうが安全なのかなぁという気もしますが、そこはご愛嬌。
ちなみにセッションはモデルを呼び出したときのものを再利用しています。
df['MODEL_NAME'] = 'seasonality_model_v1'
df['VERSION'] = context.partition_id
select = df[['MODEL_NAME','VERSION','DATE','PRODUCT_CODE','PRED_SOLD_QUANTITY']]
session.write_pandas(select, table_name='PRED_RESULTS', schema='DEMO_SCHEMA', overwrite=False, auto_create_table=True)
これで学習→推論を並列に実施することができました!

MMTと同じで、データ取込と処理が別々にプログレスバーに表示されます。
今回はモデルの学習ではないのですが、Training Completeになっていますね。内部的にはMMTもDPFも同じロジックを使っていそうです。
あとがき
似たような特徴量を使いつつ、いくつか分割してモデルを作成したいというシチュエーションは実務でも結構あるかと思います。
Snowflakeのリソースを活かして並列で実行できるのはとてもありがたいですね!
DPFはML以外の用途でも使えるシチュエーションあるのでは?と感じています。
ありがたや~~~~~~
公式ドキュメント
今回参考にしたドキュメントはこちら
Discussion