Snowflake特徴量ストアのベストプラクティス
Snowflakeの特徴量ストアについて、ベストプラクティスガイドがチュートリアルの中に用意されていました。
体系的にまとまっていて良い内容だったので、サンプルデータを交えて解説したいと思います。
なぜこんな良いドキュメントが、チュートリアルのリポジトリに埋まっているのか、、、
特徴量ストアとは
まず初めに特徴量ストアの機能概要について解説します。
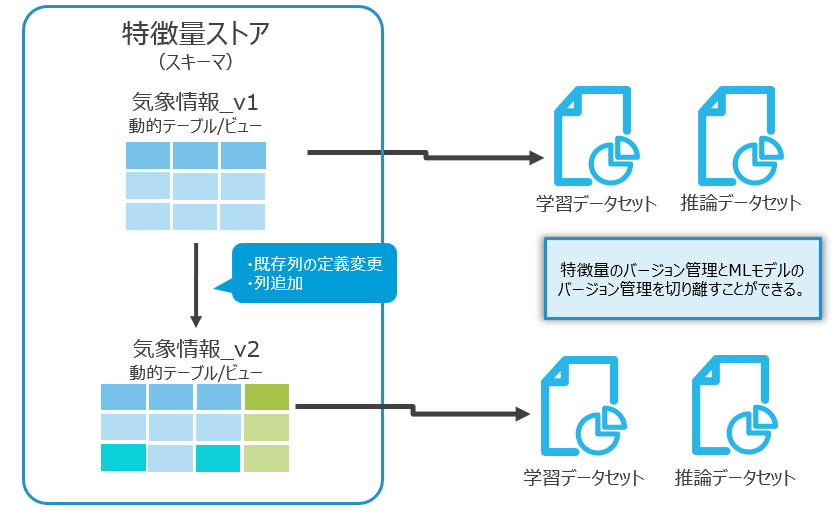
特徴量ストアはMLモデルで使用する特徴量を一元的に管理し、開発~本番運用まで一貫したロジックで特徴量の生成を可能にする機能です。
また、特徴量のバージョン管理が可能になっており、MLOps上で不可欠な機能です。
この後出てくる言葉を整理しておきます。
| 用語 | Snowflakeのオブジェクト | 概要 |
|---|---|---|
| 特徴量ストア | スキーマ | 特徴量を管理する専用のスキーマのこと。 |
| エンティティ | タグ | MLモデルを開発する対象となるビジネスエンティティを定義したもの。エンティティを識別するキーとして表現される。 |
| Feature View | ビュー/動的テーブル | 特徴量を保管するビュー、動的テーブルのこと。特徴量ストア内ではバージョン管理が可能。 |
| Spine | テーブル/DataFrame | 特徴量ストアからデータセットを作成するために必要なキーを絞ったデータのこと。学習・予測対象のデータが持つエンティティを結合したもの。 |
ベストプラクティスガイドを解釈していくに当たって、サンプルのデータがあった方が分かりやすいので、Snowflake MLのサンプルデータからairline_featuresを使用します。
from snowflake.snowpark.context import get_active_session
session = get_active_session()
# 特徴量ストアとして使用するスキーマを変数化しています
# 今回はcurrent_schemaを特徴量ストアとして扱います
FS_DEMO_SCHEMA = session.get_current_schema()
# サンプルデータをロードします
from snowflake.ml.feature_store.examples.example_helper import ExampleHelper
example_helper = ExampleHelper(session, session.get_current_database(), FS_DEMO_SCHEMA)
source_tables = example_helper.load_example('airline_features')
# 取り込んだデータの確認
for table in source_tables:
print(f"{table}:")
df = session.table(table).limit(5).to_pandas()
df.style
特徴量ストアの基本情報
エンティティの定義
まずは特徴量ストアとエンティティを定義するところからです。
from snowflake.ml.feature_store import (
FeatureStore,
FeatureView,
Entity,
CreationMode
)
# 特徴量ストアを定義
fs = FeatureStore(
session=session,
database=session.get_current_database(),
name=FS_DEMO_SCHEMA,
default_warehouse=session.get_current_warehouse(),
creation_mode=CreationMode.CREATE_IF_NOT_EXIST,
)
# エンティティを定義
zipcode_entity = Entity(
name="AIRPORT_ZIP_CODE",
join_keys=["AIRPORT_ZIP_CODE"], #SpineとFeature Viewを結合するキーを指定
desc="Zip code of the airport.",
)
fs.register_entity(zipcode_entity) #->エンティティを登録
plane_entity = Entity(name="PLANE_MODEL", join_keys=["PLANE_MODEL"], desc="The model of an airplane.")
fs.register_entity(plane_entity) #-> エンティティを登録
fs.list_entities().show()
エンティティを定義するときに最も大事なことは、「特徴量ストア内で一意に定まる定義をする」ということです。
先程のコードではAIRPORT_ZIP_CODEとPLANE_MODELというエンティティを定義しました。
AIPORT_ZIP_CODEは空港所在地の郵便番号です。
従って、どんなビジネスをやっていたとしても一意に定まります。
以下にアンチパターンの一例をあげます。
空港を表すコードは大きく二種類存在していることをご存じでしょうか?
国際航空運送協会(IATA)が定めるコードと国際民間航空機関(ICAO)が定めるコードの二種類が存在しています。
前者は3文字なので3レターコード、後者は4文字なので4レターコードと呼ばれています。
例えば羽田空港であれば、前者はHNDで後者はRJTTです。関空だとKIXとRJBBです。
3レターは航空機に乗る際にチケットに印字されますので、見たことがあるかもしれません。
4レターはパイロットや航空管制官等の運航に関わる人々が業務で使うコードです。
閑話休題。
特徴量ストアのエンティティとしてAIRPORT_CODEを定めたとします。
これがFeature Viewごとに3レターなのか4レターなのかで定義が異なっていると、Feature Viewを結合するために他のマスタを経由する必要が発生してしまいます。
これは特徴量ストアの設計としてよろしくありません。
エンティティを定義するときは、開発チーム内で(あるいはビジネス側とも)合意形成をするべきでしょう。
組織と特徴量ストアの関係
特徴量ストアはアカウント内にいくつでも作成することができますが、数が増えれば増えるほど組織全体での利活用が難しくなります。
ビジネスドメインなどである程度まとめて断片化を最小限に抑えることがベストプラクティスとされています。
また、機密性が高い特徴量を作成する場合はアクセス制御の観点で特徴量ストアを分離することも推奨されています。

Feature Viewを作成する
さて実際に特徴量を作ってみましょう。特徴量を保管するオブジェクトはFeature Viewと呼ばれています。
Feature Viewはビュー又は動的テーブルとして作成します。
all_feature_views = []
for fv in example_helper.load_draft_feature_views():
rf = fs.register_feature_view(
feature_view=fv, # Feature Viewの定義を渡す
version='1.0'
)
all_feature_views.append(rf)
fs.list_feature_views().select('name', 'version', 'desc', 'refresh_freq').show()
今回はexample_helperを使いましたので、もともとFeature Viewの定義が済んでいました。
自前でFeature Viewを作成するときは以下のコードです。
fv = FeatureView(
name="MY_FV",
entities=[entity],
feature_df=my_df, # 特徴量定義をしたSnowpark DataFrameを渡す
timestamp_col="ts", # (optional)タイムスタンプ列
refresh_freq="5 minutes", # 更新頻度を指定
desc="my feature view"
)
この時、refresh_freq = Noneとするとビューが作成され、それ以外だと動的テーブルとしてデータが実体化されます。
ここまでコードを実行するとSnowsight上でエンティティやFeature Viewを閲覧できるようになります。
「AI&ML」タブから「Features」を選択するとアカウント内の特徴量ストアを一覧表示できます。

Entitiesをクリックすると、先ほど作成したエンティティが一覧表示されます。

エンティティを利用可能にするJOIN_KEYやFeature Viewを一覧表示できます。
Feature Viewsをクリックすると、Feature Viewの一覧を確認できます。
また、各Feature Viewのバージョンや動的テーブルの更新状態をチェックすることが可能です。

データセットを作成する
作成したFeature Viewから学習・推論に使用するデータセットを作成します。
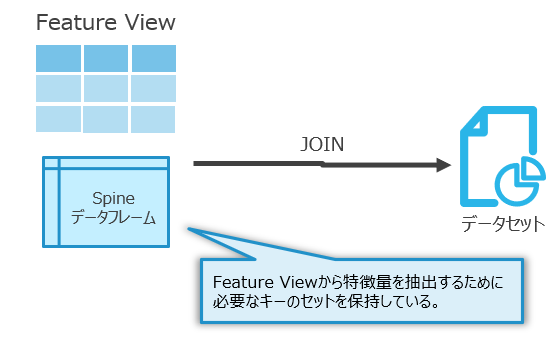
このとき使用するのがspine(背骨)データフレームです。
平たく言うと、spineは学習・推論対象の集まりで、Feature Viewから特徴量を取得するためのキーを備えたデータフレームです。
spineとFeature Viewを結合することで学習・推論のデータセットを作成できます。
# spineデータフレームを定義
query = """
SELECT
scheduled_departure_utc,
airport_zip_code, -- エンティティの結合キー
departure_code,
destination_code,
tickets_sold,
plane_model -- エンティティの結合キー
FROM us_flight_schedules
"""
spine_df = session.sql(query)
ds = fs.generate_dataset(
name="trip_duration_ds",
spine_df=spine_df,
features=[plane_fv, airport_weather_fv], # 特徴量を取得するFeature Viewを指定
spine_timestamp_col="SCHEDULED_DEPARTURE_UTC", # 時系列データはASOF JOINで結合されます
spine_label_cols=["TICKETS_SOLD"],
include_feature_view_timestamp_col=False, # optional
)
ds.read.to_pandas().head(5)
generate_dataset()を使用すると、Snowflake Datasetとして永続化されます。これはSnowflake内部でParquet形式で管理されるデータで、immutableです。
したがってnameに同じ文字列を与えて再実行するとエラーになります。
Snowflake Datasetは大規模なデータセットや、分散トレーニング等のワークロードに向いています。
基本的には不変なファイルベースのオブジェクトになるので監査性も高く、本番運用ではdatasetを使うメリットが大きいです。
モデル開発等の実験段階では、不変オブジェクトとして保存する必要がないケースも多いと思いますので、そういう場合はgenerate_training_set()を使います。
これはデータセットとしてSnowpark DataFrameを作成するメソッドです。
シチュエーションに応じて使い分けて下さい。
エンティティとFeature Viewの関係
ひとつのFeature Viewに複数のエンティティを割り当てることができます。
しかし、関連付けるエンティティはあくまで特徴量を一意に絞るために必要最低限のEntityを紐付けることが推奨されています。
複数のエンティティから特徴量を取得したい場合は、Feature Viewにエンティティを含ませるのではなく、spineにエンティティを持たせて、Feature Viewは疎結合にしておくことが推奨されています。

ビュー vs 動的テーブル
Feature Viewにはビューと動的テーブルの選択肢があります。
用途に応じて使い分けが必要ですが、一般的なオブジェクトとしての差異を意識しておけば大丈夫なので、簡単な説明に留めます。
ポイントをいくつかまとめておきます。
- 特徴量の実験・開発フェーズではビューベースのFeature Viewを使うと計算・ストレージコストを抑えられます
- ソースデータが頻繁に更新されるテーブルの場合、動的テーブルは増分更新に大きな計算コストがかかる場合があるため、ビューを使用します
- 特徴量の定義が複雑になる場合は動的テーブルを使用することで、使用時のクエリパフォーマンスが向上することがあります
特徴量を開発する
ここからは特徴量ストア内で管理する特徴量に目を向けます。
特徴量ストアで管理するべき特徴量の基準
まず特徴量ストアで管理するべき特徴量の基準として「モデル固有の前処理変換ではない」という点が挙げられます。
例えば、以下のような特徴量はモデル固有の前処理と言えるでしょう。
- カテゴリ列のOne-Hot Encodeing
- 数値列のmin-max Scaling
これらは通常、学習データセット内でスケーラーがフィッティングされるため、MLモデルごとにスケーラーが必要になります。これを特徴量ストアで管理しようとすると、モデル開発の度に毎回Feature Viewを作成することになり、開発効率が下がってしまいます。
サンプリングされたデータを学習に使うべきところで、グローバルにスケーリングされた特徴量を使ってしまうと、MLモデルは本来入手できない情報を入手して学習することになります。これは一般的にデータリークと呼ばれています。
ベストプラクティスガイドでは、本番運用に向けてはデータリークに注意を払いなさいとしながらも、開発効率を上げるために実験フェーズではデータリークを許容し、特徴量ストア内でこのような特徴量を管理することもある、としています。
変換処理を定義する
特徴量ストアで管理する特徴量を決めたら、次は実装方法を検討します。
簡単な変換であれば、SQLやSnowpark DataFrame APIを利用して直接Feature Viewの定義に盛り込むことができます。UDFを使うことができるので、Python,Scala,Java等を利用できます。
少し複雑な変換、例えば前述のmin-max scaling等はモデルレジストリの活用が推奨されています。
snowflake.ml.modelingにはscikit-learnをラップした前処理関数が用意されています。
予めフィッティングしたスケーラーをモデルレジストリに保存し、UDFを使ってtransformを呼び出すことで、Feature View内で利用できるようになります。
補足:動的テーブルで使用するUDF
動的テーブルベースのFeature ViewでUDFを使用する際、増分更新がサポートされているのはIMMUTABLEプロパティが設定されたUDFのみです。
IMMUTABLEプロパティについてはこちらの記事が参考になります。
特徴量ストアとDevOps
ここからは開発した特徴量を運用に載せるためのDevOpsとの関連やFeature Viewのバージョン管理について見ていきます。
環境構成と特徴量ストアのライフサイクル戦略
特徴量ストアの実態はスキーマなので、基本的には所属するデータベース・アカウントのDevOps戦略に従います。
シングルアカウントで運用されている環境であれば、アカウント内にDEV_DB, TEST_DB, PRD_DBが存在していることが多いと思いますし、マルチアカウントであればDEV_ACCOUNT, PRD_ACCOUNTに同じ物理名のDBが存在していることが多いと思います。
特徴量ストアも同様に扱うことができます。
特徴量ストアもアカウント間共有が可能です。PRD_ACCOUNTからDEV_ACCOUNTへデータ共有すれば、本番環境と同じデータを使ったモデル開発が可能になります。
またSnowflakeの特徴量ストアは、複数の特徴量ストアから特徴量を取得し結合する、ということがサポートされています。
そのため開発環境ではViewベースのFeature Viewを作成し、本番環境のFeature Viewを参照することでストレージコストや動的テーブルの計算コストを節約することが可能になります。

prd_df = session.table('prd_feature_view') # PRD環境のFeature Viewを指定
fv = FeatureView(
name="DEV_FV",
entities=[entity],
feature_df=prd_df,
refresh_freq=None, # 更新頻度をNoneにすることでViewベースのFeature Viewが作成される
desc="PRD参照のFeature View"
)
Feature Viewのバージョン管理
特徴量ストアのFeature View、つまりビューと動的テーブルはバージョン管理することができます。
Feature Viewは作成時にバージョンを指定します。
rf = fs.register_feature_view(fv, version="2.0")
一度作られたバージョンは基本的には不変なオブジェクトとして扱われます。
したがって、上記のコードは二回実行するとエラーになります。
しかし、Feature Viewをdbt等のツールを使って管理する場合、環境によっては同じバージョンを上書きする必要があるかもしれません。
その場合はパラメータを追加します。
rf = fs.register_feature_view(fv, version="2.0", overwrite=True)
繰り返しになりますが、基本的には一度作ったバージョンは不変なオブジェクトとして扱われるべきなので、どうしても必要な時のみこのパラメータを使います。
同じFeature Viewに新しいバージョンを追加するとSnowsightでは新旧全てのバージョンを閲覧できます。
オブジェクト名+バージョン名が付与されたオブジェクトになります。

新しいバージョンを作成した場合、上図のように別のオブジェクトとして作成されます。
したがって、動的テーブルの場合はバックフィルと追加更新分が再計算されます。
古いバージョンがすでに計算した分のデータが新しいバージョンに引き継がれることはありません。
また、古いバージョンの動的テーブルもrefreshを続けるので、ストレージコスト・コンピューティングコスト両方に注意が必要です。
古いバージョンは放置せず、不要になったタイミングで更新を止めることが望ましいです。
これはオブジェクトの削除ではありません。
計算の重複回避
Feature Viewのバージョンを更新する度に動的テーブルの再計算が走るとなると、コスト面やデータ整合性の担保が心配になります。
ベストプラクティスガイドでは、この追加の計算とストレージのオーバーヘッドを避けるために、ブランチとマージという考え方が紹介されています。
ブランチFeature View
既存のFeature Viewに新しい特徴量を追加、もしくは定義を変更する場合、同じFeature Viewの新バージョンではなく変更箇所のみを含む新しいFeature Viewを作ります。
特徴量を新たに作成する場合、それは当面の間「実験フェーズ」であることが多いと思います。この新しく作成されたブランチFeature viewは実験フェーズの間は元のFeature ViewとJoinして使用することになります。
そこで、特徴量の名称(つまり列名)が被らないように、列名にもバージョンを表す接頭語/接尾語を付与することが推奨されています。
マージ
ブランチで作成していた特徴量が本番運用可能であると判断された場合、それらを「マージ」します。
既存のFeature ViewとブランチFeature Viewを結合するようなマスターFeature Viewを作成します。
このマスターFeature ViewはViewベースのFeature Viewとして作成することで、ストレージのオーバーヘッドを発生させずにバージョン更新が可能になります。

私の感覚ですが、ここで紹介されているブランチ/マージ手法にはデメリットもありそうだと感じています。
一つはブランチFeature Viewの大量発生です。
Feature Viewの開発が進んでいったときにブランチFeature Viewがどんどん増えていくことになります。
稼働しないといけない古いバージョンが残り続けるのは、運用負荷が高くなっていきそうだな、、、と感じています。
もう一つはマスターFeature Viewの煩雑化です。
ややもすればマスターFeature View自体のバージョン管理が発生し、マスターFeature Viewを参照するマスターFeature Viewが発生するのではないかという気がしています。
上記2つの事からブランチ/マージ手法はあくまで、動的テーブルベースのFeature Viewを使っているケースでコストのオーバーヘッドが許容できない場合に取る措置だと考えています。コスト面がそんなに大きくないFeature Viewであれば、この手法を取るよりFeature View全体のバージョンを更新していくほうが、実際の運用に即していると思います。
特徴量ストアを運用するときに気を付けること
ここまでで特徴量ストアの運用に関する大事な点は抑えられています。
最後に、特徴量ストアの前段のデータパイプラインに関係する話を中心に補足事項をまとめます。
動的テーブルベースのFeature View
動的テーブルベースのFeature Viewを運用する時には、いくつか注意するべきところがあります。
アーカイビング
Feature Viewの履歴をソースデータの保持期間を超えて保管する必要がある場合、定期的にFeature Viewの履歴を別のテーブルやストレージにコピーしておく必要があります。
実際に使うFeature Viewはこのアーカイブされたデータと最新のデータを結合したビューになるため、アーキテクチャが煩雑になります。
私見を述べると、特徴量として使いたいのにソースデータが一定期間で破棄されるというシチュエーションの場合、そのソースデータをアーカイブしておく(特徴量ストアのためにステージングする)テーブルを用意してそのテーブルのソースデータとしてFeature Viewを構成するほうが、遥かに簡単だと思います。
ソースデータが多すぎるという場合はこの後のセクションで記載する方法で絞り込みが可能です。
したがって、特徴量ストアを構築する際には、ソースデータはData Vault2.0のような完全な履歴管理の仕組みを用意することを検討したほうが良いです。
MLモデルを作ってみたら学習データが足りなかった、なんてことは避けたいですからね…
履歴の動的な管理
例えばソーステーブルに4年分のデータが入っているが、MLモデルの特徴量としては過去1年分のデータがあれば十分だ、というケースがあるかもしれません。
その場合は動的テーブルに過去データの保持量に関するフィルターを加えておくことで、適切なサイズのFeature Viewに保つことができます。
別のパラメータテーブル等に最大レコード数を登録しておき、row_number()/qualifyで適用する手法が紹介されています。
-- パラメータテーブルを作成
create or replace table DEMO_DB.FEATURE_STORE.FS_RETENTION_PARAMETER(
fq_feature_view varchar,
max_rows_per_zipcode integer)
;
-- パラメータを設定
insert into DEMO_DB.FEATURE_STORE.FS_RETENTION_PARAMETER
select 'aiport_weather_station$2', 500
;
-- Feature Viewの定義に絞り込みを追加
create or replace dynamic table DEMO_DB.FEATURE_STORE.F_WEATHER$2 (
TS,
AIRPORT_ZIP_CODE,
RAIN_SUM_30M COMMENT 'The sum of rain fall over past 30 minutes for one zipcode.',
RAIN_SUM_60M COMMENT 'The sum of rain fall over past 1 hour for one zipcode.'
) target_lag = '1 day' refresh_mode = AUTO initialize = ON_CREATE warehouse = FEATURE_STORE_WH
COMMENT='Airport weather features refreshed every day.'
cluster by (AIRPORT_ZIP_CODE, TS) as
SELECT
datetime_utc AS ts,
airport_zip_code,
SUM(rain_mm_h) OVER (
PARTITION BY airport_zip_code
ORDER BY datetime_utc
RANGE BETWEEN INTERVAL '30 minutes' PRECEDING AND CURRENT ROW
) AS rain_sum_30m,
SUM(rain_mm_h) OVER (
PARTITION BY airport_zip_code
ORDER BY datetime_utc
RANGE BETWEEN INTERVAL '60 minutes' PRECEDING AND CURRENT ROW
) AS rain_sum_60m
FROM demo_raw.airport_weather_station,
demo_raw.fs_retention_parameter
where
fq_feature_view = 'aiport_weather_station$2'
qualify
row_number() over (partition by airport_zip_code order by datetime_utc desc) <= max_rows_per_zipcode
;
qualify句の中でairport_zip_codeごとに取得する行数を絞っているという仕様です。
今回作成している特徴量は降水量の累計なので、このような絞り込みはしないと思いますが、あくまで一例としてご紹介しました。
初めてFeature Viewを作成するときも、利用するタイムスタンプの最小値を決めておき、それ以降のデータに絞って作成することで、不要なコストを省くことができます。
ただし、これらは動的テーブル内にハードコーディングするのではなく、パラメータテーブルとして保管し、動的テーブルの定義を変更することなく状態管理ができるようにするべきです。
ソーステーブルの再作成
動的テーブルのソーステーブルが再作成された場合、Change tracking is not enabled or has been missing for the time range requested on table ...というエラーが発生し更新されなくなります。すなわちデータパイプラインの破損です。
この場合はFeature Viewをoverride=Trueにして再作成する必要があります。
動的テーブルを再作成する場合、過去更新されていたデータについても再計算されるため大規模なテーブルの場合はコストがかかることがあります。
コストを抑える手法としては、破損した動的テーブルを残し、再作成のタイミング以降のデータを計算する動的テーブルを新たに作成します。この新旧両方の動的テーブルをUNIONするビューを用意することで、引き続き運用可能になります。
ただし、何回もこの「継ぎ接ぎ」をしていくのは運用的に大変なので、多少のコストには目を瞑って動的テーブルも再作成するほうが楽だと思います。
タイリング (Tiling)
タイムスタンプやDATE型の列について、様々な時間粒度で事前集計しておくことをタイリングと言います。
例えば日次集計 → 週次集計 → 月次集計のようにFeature Viewを用意しておくことで、高次の集計を利用するときに必要な計算リソースを削減することができます。
データセット内に時間のデータがあるときは試してみてもいいですが、Feature Viewを重ねていく煩雑さとのトレードオフになるかなと思います。
Feature Viewの品質監視
Feature View のデータ品質および統計的変動を監視するために、Data Metric Functions (DMF)を使うことができます。
Snowsight上で簡単なデータの統計情報と自分で定義したDMFに基づくモニターを確認することができます。

さいごに
ここまで読んで下さり、ありがとうございました。
Snowflakeの特徴量ストアを利用することで、データエンジニアリング領域の延長線にデータサイエンス領域を置くことができます。
2つの領域で働くエンジニアを合流させる、言わば乗換駅的な機能がSnowflakeの特徴量ストアだと思います。
Dataプラットフォームでもなく、MLプラットフォームでもなく、DataターミナルとしてSnowflakeを使ってみてはいかがでしょうか?
Discussion