Snowlfake ML Jobsを使おう!
この記事は帰ってきたSPCS活用最新事例LT祭:再び解き放て、Snowpark Container Servicesの力!で話した内容の解説です。
アーカイブがこちらで公開されているのでぜひご覧ください!
SPCS関連のアレコレがギッチリ詰まった熱量高いLTイベントでした。
semi-AutoMLのススメ
機械学習を良い感じにやっていきたい時に、AutoMLを使うシチュエーションは多いと思います。
AutoMLは簡単な設定をして放っておけば、そこそこ良いモデルができるので便利ですが、反面小回りが利かない点があります。
例えば、「予測結果からSHAPを計算したい」と言ったときに「多重にアンサンブルしていて計算できません」とか「学習時のパラメータをちょいと調整したい」という要望に「細かい設定はできないんです、、、」と答えないといけないことがあったりとかします。
うーん、AutoMLみたいに大量の実験を動かしたいけど、細かい制御もしたいんだよなぁ~
というアナタにSnowflakeのMLJobsを使ったsemi-AutoMLをお届けします!
MLJobsとは
MLJobは開発環境(IDE)から直接ジョブを実行し、Snowflakeのコンテナーランタイム上でMLワークフローを処理できる機能です。
簡単な例を紹介します。
def greeting(name):
message = f"Hello, {name}!"
return message
これをローカルのVScode等で実行すると、ローカルのPython環境で実行されて戻り値が得られます。
この関数をSnowflakeのコンテナーランタイムで実行するには、以下のように修正します。
+ @remote(
+ compute_pool = 'MY_COMPUTE_POOL',
+ stage_name = 'MY_STAGE'
+ )
def greeting(name):
message = f"Hello, {name}!"
return message
remoteデコレータがついた関数を実行すると、SnowflakeのコンテナーランタイムにJobが作られ、非同期実行されます。
compute_poolは実行するコンピュートプール名を渡します。
stage_nameはジョブを保存する内部ステージ名を渡します。もし存在していないステージ名を渡した場合は、新規作成されます。
実行されたジョブはSnowsight上で確認できます。


semi-AutoMLイメージ
このMLJobを使って、大量に実験を並列に動かしつつあわよくばモデルのアンサンブルとかもやりたいな~と思い、以下のような処理を作ってみました。

ポイント
- ベースモデルは並列に学習する
- メタモデル(アンサンブル)はベースモデルの学習が全て終わった後に学習する
- 作成したモデルはSnowflakeに保管する
実装
ベースモデルの学習ジョブ
まずはベースモデルの実装をします。
ベースモデルはLightGBMやXGBoost、その他線形モデル等を使います。
ここで作るのは「パラメータを変えて実行可能なテンプレート」です。
実験ごとに前処理を変えたい、とかモデルのチューナーを使わずにハイパーパラメータの設定を行いたいといった希望はここで吸収します。
と言っても難しいことをするわけではなく、関数を定義するときに引数として設定を受け取る口を作っておくだけです。
以下はxgboostの例です。
from snowflake.ml.experiment import ExperimentTracking
from snowflake.ml.experiment.callback.xgboost import SnowflakeXgboostCallback
from snowflake.ml.model.model_signature import infer_signature
from snowflake.ml.jobs import remote
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split
@remote(compute_pool="SYSTEM_COMPUTE_POOL_CPU", stage_name="payload_stage")
def xgb_trainer(session, exception_features=None, monotone_constraints=None) :
"""
exception_features: ベースのテーブルから除外したい特徴量のリスト
monotone_constraints: 単調制約の設定をしたリスト
"""
df_pd = session.table('XS_SANDBOX.PUBLIC.WALMART_SALES_FEATURES').to_pandas()
feature_columns = [col for col in df_pd.columns if col not in ['STORE_CODE', 'TRANSACTION_DATE', 'WEEKLY_SALES']]
X = df_pd[feature_columns]
y = df_pd['WEEKLY_SALES']
if exception_features is not None: # 引数が与えられていたら、特徴量から除外する
X = X.drop(columns=exception_features)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
exp = ExperimentTracking(session=session)
exp.set_experiment("walmart_test")
sig = infer_signature(X_train, y_train)
callback = SnowflakeXgboostCallback(
exp, model_signature=sig
)
# もちろんランダムサーチやtunerによるパラメータチューニングも実行可能です
params = {
'max_depth': 5,
'learning_rate': 0.1,
'n_estimators': 100,
'subsample': 0.8,
'colsample_bytree': 0.8,
'random_state': 42
}
if monotone_constraints is not None: # 引数が与えられていたら、単調制約を設定する
params['monotone_constraints'] = monotone_constraints
model = XGBRegressor(**params, objective='reg:squarederror', callbacks=[callback])
with exp.start_run():
model.fit(X_train, y_train, eval_set=[(X_test, y_test)])
# 学習データに対する予測値を算出して、Snowflakeのテーブルに書き込んでおき、メタモデルの学習に利用する
df_pd['PREDICTION'] = model.predict(X)
df_pd['MODEL_NAME'] = model.__class__.__name__.upper()
session.write_pandas(
df_pd[['STORE_CODE', 'TRANSACTION_DATE', 'WEEKLY_SALES', 'PREDICTION', 'MODEL_NAME']],
table_name="WALMART_SALES_BASE_PREDICTIONS",
auto_create_table=True,
overwrite=False
)
LightGBM版はこちら
from snowflake.ml.experiment import ExperimentTracking
from snowflake.ml.experiment.callback.lightgbm import SnowflakeLightgbmCallback
from snowflake.ml.model.model_signature import infer_signature
from snowflake.ml.jobs import remote
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
@remote(compute_pool="SYSTEM_COMPUTE_POOL_CPU", stage_name="payload_stage")
def lgbm_trainer(session, exception_features=None) :
"""
exception_features: ベースのテーブルから除外したい特徴量のリスト
monotone_constraints: 単調制約の設定をしたリスト
"""
df_pd = session.table('XS_SANDBOX.PUBLIC.WALMART_SALES_FEATURES').to_pandas()
feature_columns = [col for col in df_pd.columns if col not in ['STORE_CODE', 'TRANSACTION_DATE', 'WEEKLY_SALES']]
X = df_pd[feature_columns]
y = df_pd['WEEKLY_SALES']
if exception_features is not None: # 引数が与えられていたら、特徴量から除外する
X = X.drop(columns=exception_features)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
exp = ExperimentTracking(session=session)
exp.set_experiment("walmart_test")
sig = infer_signature(X_train, y_train)
callback = SnowflakeLightgbmCallback(
exp, model_signature=sig
)
# もちろんランダムサーチやtunerによるパラメータチューニングも実行可能です
params = {
'objective': 'regression',
'metric': 'rmse',
'n_estimators': 100,
'learning_rate': 0.1,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 1,
'verbose': -1,
'random_state': 42
}
model = LGBMRegressor(**params)
with exp.start_run():
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], callbacks=[callback])
# 学習データに対する予測値を算出して、Snowflakeのテーブルに書き込んでおき、メタモデルの学習に利用する
df_pd['PREDICTION'] = model.predict(X)
df_pd['MODEL_NAME'] = model.__class__.__name__.upper()
session.write_pandas(
df_pd[['STORE_CODE', 'TRANSACTION_DATE', 'WEEKLY_SALES', 'PREDICTION', 'MODEL_NAME']],
table_name="WALMART_SALES_BASE_PREDICTIONS",
auto_create_table=True,
overwrite=False
)
今回は割愛しますが、メタモデルも同じようにジョブを用意しておきます。
実行制御
これまでに作ったジョブを実行します。
予めモデルと引数の組み合わせを配列に入れておいて、ループで実行していきます。
MLJobsは基本的には非同期実行ですので、ジョブがSnowflake側に作成されたらそこで処理完了です。
前のジョブの終了を待つことなく、並列でMLモデルを学習させることができます。
ベースモデルは非同期実行でいいのですが、メタモデルの学習はベースモデルの学習が全て終わってから実行したいですよね。
そんなときはwaitメソッドを使います。
たったこれだけで、ジョブのステータスを取得し完了するまで待ってくれます。
ということで、実行制御自体は以下のようなお手軽コードで書けます。
base_models= [
(xgb_trainer, {exception_features: ['IS_HOLIDAY'], monotone_constraints:(0,1,0,0,0,-1,0)}),
(xgb_trainer, {exception_features: [], monotone_constraints:(0,0,0,0,0,0,0)}),
(lgbm_trainer, {exception_features: ['IS_HOLIDAY']}),
(lgbm_trainer, {exception_features: []}),
# 実行したいジョブを列挙しておく
]
meta_models = [
(voting_trainer, {select_method:'random', num_models:5}),
(voting_trainer, {select_method:'ranking', num_models:5}),
# 実行したいジョブを列挙しておく
]
train_jobs = []
for func, kwargs in base_models:
train_jobs.append(func(session, **kwargs)) # ベースモデルの学習を並列で実行
for job in train_jobs:
job.wait() # ベースモデルの学習終了を待つ
for func, kwargs in meta_models:
train_jobs.append(func(session, **kwargs)) # メタモデルの学習を並列で実行
この仕組みで、沢山の実験を同時実行しつつ、細かくモデル設定を行うことができるようになりました。
よりAutoMLっぽくするなら、前処理とベースモデルの組み合わせを用意しておいて、ジョブの引数に渡して切り替えられるようにします。
コンテナーランタイム上で処理が実行されますが、イメージを自作する必要がないという点がとても大きいです。
実験管理
MLJobsを使って大量の実験を比較的楽に投げられるようになったので、次は投げた実験を並べて比較したくなりますね。
ちょっと前ならMLflowをSPCSに載せて、、、とかやるところなのですが、先日Snowflakeネイティブな機能としてExperimentalTrackingがプレビューになりました。
先程ベースモデルジョブに仕込んでいたのは、この機能のコードです。
現時点ではXGBoostとLightGBMがauto_logに対応しており、他モデルは自分でコードを書けば記録を残すことができます。
APIはMLflowに非常に似ており、すぐに移行できます。
保存した実験はSnowsightから閲覧できます。
こちらの記事がとても良くまとまっていますので、ここではサラッと触れるに留めます。
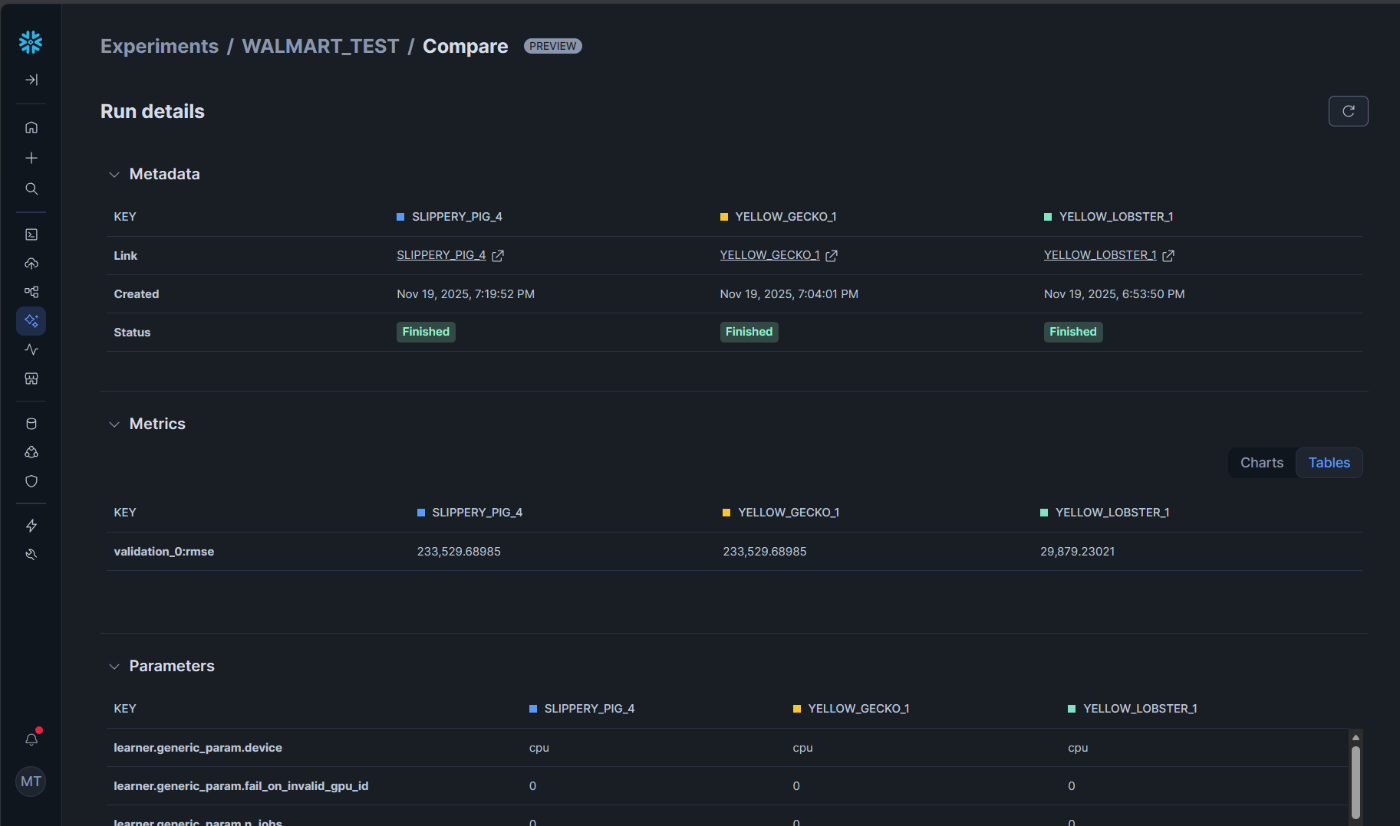
auto_logの機能でパラメータが全て保存されています。
出来上がったモデルも自動でモデルレジストリに保存されます。

モデルレジストリからそのままモデルサービング(推論エンドポイントを作成すること)が可能です。

ボタンポチポチでSPCS上にサービスができあがります。
とても楽~~~~~~~~~~~~~~~~~~~~~~~~~
MLJobsの使いどころ
MLJobsはML以外のワークロードにも使用できます。
要するにお手軽外付けコンピューティングです。
ローカルにデータを持ってくるには重すぎる処理や、Snowflakeの外部にデータを持ち出したくない場合に有効活用できます。
また今回は割愛してますが、ファイルやディレクトリをMLJobsとして扱うことが可能です。
ファイルをgit管理しておいて、Azure PipelinesやGithub Actionsで実行すれば、そのままCI/CDのプロセスに組み込むことができます。
CI/CDのエージェントが低スペックでも実行でき、開発時とほとんど同じコードで実行できるため運用負荷を下げることができます。とてもオススメです。
さいごに
今回SPCSのLT祭ということで一枠頂いて登壇させて頂きました。
SnowVillageの#containerというチャネルでは月に一回、勉強会が開催されています。
(@あれさんがファシリテートしてくださっていますっ!!!!)
SPCS使ってみたいけど、どうしたらいいか分からない!という方や最新アップデートを追いかけたい!という方はぜひご参加ください!
Discussion