Snowflakeだけで完結するMLOps
はじめに
こんにちは、たきこみと申します。
普段は事業会社で機械学習モデルの開発やデータ基盤構築などの仕事をやっています。
データ基盤としてSnowflakeを採用しているのですが、SnowflakeはAIデータ基盤を謳っているということもあり、AI/ML系の機能拡充が留まることを知りません。
そろそろSnowflake単体でMLOps的な環境が作れるようになってきた気がしているので、MLOpsとSnowflakeの機能配置について考えをまとめておきたいと思い、この記事の執筆に至っています。
MLOps概略
まずは僕が実現したいと考えるMLOpsのサイクルを紹介します。

MLOpsにおいて大事なポイントは3つあると考えています。
- アイデアをすぐ形にできる開発環境
- 運用可能なコストラインを遵守できる計算リソース
- MLモデルと特徴量の状態を常時監視できる運用環境
細かい点は置いておいてこれらが守れていれば、MLOpsとしてのサイクルを回していくことができます。
上図の3つのサイクルはそれぞれこの三点にフォーカスしたサイクルになっています。
この後はそれぞれのサイクルについて詳細をご紹介します。
開発サイクル
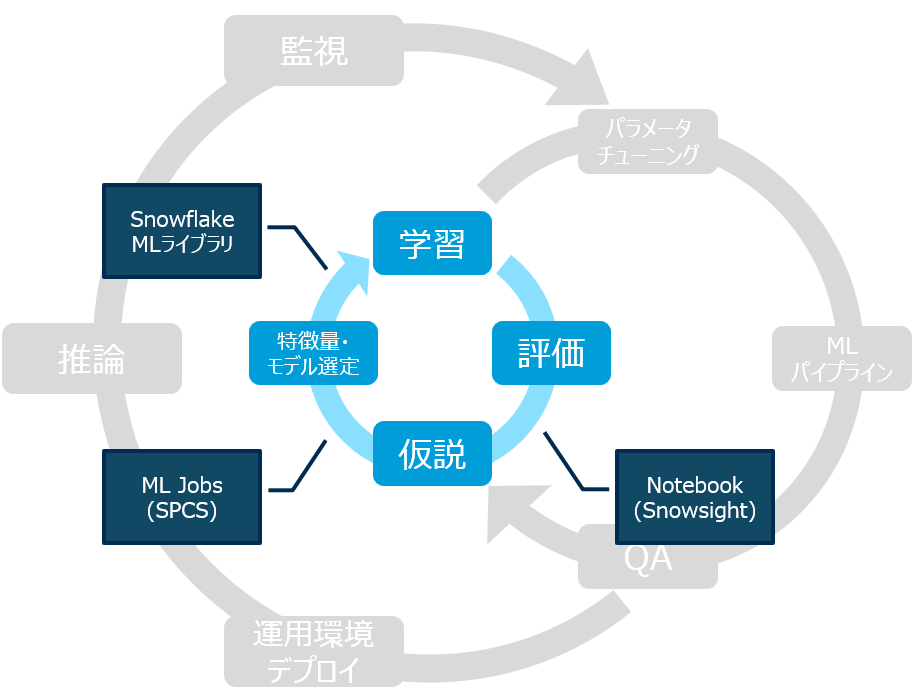
まずは一番内側の開発サイクルです。
ここではデータサイエンティストが個人レベルで仮説検証を繰り返していくことになります。
データ基盤としては、とにかくアイデアをすぐ形にできることが求められます。
データが綺麗な状態で揃っていることがまず最初の条件ですが、今回はそこは一旦置いておきます。
このサイクルではあくまで個人レベルでの作業が素早く進むことを念頭に置くべきです。
ノートブック(Snowsight)
今更紹介するようなものでもないですが、開発サイクルにおいてSnowsightのノートブック機能は非常に強力です。
繰り返しになりますが、開発サイクルにおいては環境構築などそっちのけで仮説検証に取り組みたいものです。Snowflakeノートブックは煩わしい環境構築をほとんど丸投げできます。制限はあるもののデータサイエンスに必要な著名なライブラリはすぐ使うことができますし、コンピューティングリソースも自由に選択できます。
使用感はJupyter Notebookとほとんど同じですが、PythonだけでなくSQLも実行できるという点が非常に強力です。僕の周囲には機械学習専門のデータサイエンティストはいません。バックグラウンドも様々です。Pythonが好きな人もいれば、なんでもかんでもSQLで書きたくなる人もいます。
Snowflake ノートブックはある程度の制約(使えるライブラリなど)を設けつつ、個人レベルで自由にエンジニアリングを進めるのにうってつけの機能です。
ML Jobs(SPCS)
「まぁ確かにノートブックは便利だよね~。でも小回りが利かないんだよなぁ~、ブラウザで作業するのも気が進まないし......」
という意見もあると思います。
そんな時はML Jobsを使ってみましょう。ML Jobsをざっくり言うと、ローカルで作業しつつ、実行環境はSnowflakeにする、みたいなイメージです。
Snowpark Container Service(SPCS)でPythonを実行できる機能ですが、コンテナーを実際に作成することなく、Snowflake側が良い感じにしてくれます。
手元のVS Codeで作業しつつ重たい処理はSnowflakeに投げる、ということが可能であり、また使用できるライブラリに制約がないため、使いこなせれば個人レベルの仮説検証において効率化が狙える機能です。
また、ノートブックは起動している時間だけ課金されますが、ML Jobsであれば処理実行中のみの課金になるため、コストカットにも寄与します。
ML Jobsは関数の頭にremoteデコレータを付けるだけで準備できます。
@remote("POOL_XS", stage_name="JOBS", session=session)
def process():
## 処理を書く ##
job = process()
蛇足になりますが、ML JobsはML関連以外の処理も実行できます。僕はzipファイルで連携されるデータを解凍してテーブルに格納するときにML Jobsを使ってます。もともとSnowflakeでzipファイルを処理するのって結構大変だったんですが、おかげさまでめっちゃ楽になりました。
Snowflake MLライブラリ
開発サイクルの最後に紹介するのはPythonライブラリであるSnowflake MLライブラリです。
SnowflakeでML関連の処理を行うときには避けて通れないライブラリです。
開発サイクルの中で特筆するべきなのは分散前処理の機能です
機械学習を行うときに実施する前処理をSnowflakeのウェアハウス上で分散実行する機能になります。
よく使うScikit-learnのスケーラーやエンコーダーをラップしており、ほとんどいつも使っているコードのまま実行できます。
データ量が多い実験を行う場合には特に有効です。
Snowflakeのウェアハウスの課金は秒単位なので、とにかく処理がすぐ終わることが偉いです。
開発サイクルにおいてはトライ&エラーを繰り返しますが、その大半はエラー(思った成果が出ない)です。このサイクルを何回も何回も繰り返していくことがMLOpsの第一歩ですが、Snowflakeはお財布事情が気にならないストレスフリーな環境を用意してくれています。
検証サイクル

このサイクルでは作成したMLモデルが運用に耐えられる性能かどうかを検証します。
MLOpsにおいて「性能」という言葉には大きく二つの意味があると考えています。
- 推論精度
- 運用にかかるコスト
この検証サイクルにおいては後者の意味です。
Snowflakeはコンピューティングを複数段階から選択でき、他サービスに比べてかなり明朗会計です。Snowflake上でMLOpsを構築する場合は、お金というよりも処理にかけられる時間にウェイトを置いたコストバランスを考えていくのが無難です。
以下にサラッとMLパイプラインの実装手法を書いておきます(他にもMLパイプラインの実装方法はありますが、長くなってしまうので割愛します)。
Snowflake MLライブラリ
Snowflake MLライブラリは検証サイクルにおいても活用できます。
そのうちの一つがパラメータチューニングです。
有名なライブラリにOptunaがあります。これはベイズ推定を利用して最適なパラメータを探すものです。残念ながら(当然といえば当然ですが)ベイズ推定のような手法は対象外ですが、より簡素なグリッドサーチやランダムサーチはSnowflakeのウェアハウス上で分散実行することができます。
ストアドプロシージャ
SnowflakeでMLパイプラインを作る最も簡単な方法はストアドプロシージャです。
Pythonでコードを書きタスクを使ってDAGとして実行することができます。
ただし、一部ライブラリやメソッドに制限があるため、環境によっては適さない可能性があります。
ML Jobs
開発サイクルで使用したML Jobsですが、一度Jobとして登録したものはいつでも呼び出して実行することができます。
こちらはストアドプロシージャよりも柔軟にコードを書くことができますし、開発サイクルで使用したコードを再利用できる可能性もあるため、ある程度MLOpsが成熟している組織ではオススメの機能です。
運用サイクル
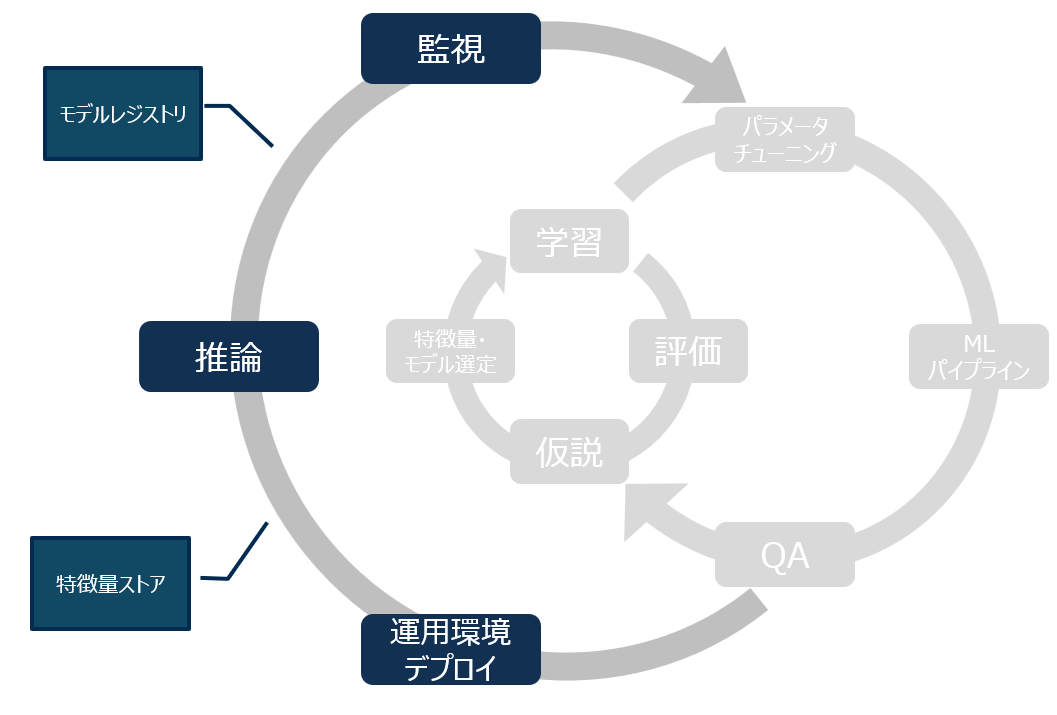
MLOpsにおいて最も重要かつ最も難しいのが運用サイクルです。
このフェーズではMLモデルは予測値を提供しており、またそれを使用するユーザーがいます。
日々特徴量がどのように動いていて、予測値がどのように移ろいでいくかを正しく観測する必要があります。
実は僕がSnowflakeでMLOpsを実現したいと考える理由の大部分がこのサイクルによるものです。
MLOpsの過程ではたくさんの中間データが発生しますが、Snowflakeはそれら全てを受け止めることができ、また簡単に管理、監視することができます。
特徴量ストア
まずは特徴量の管理についてです。
Snowflakeには特徴量ストアという機能があります。
これ自体は単なるスキーマ(の一種)ですが、MLモデルに投入する特徴量を管理するために細かい機能が追加されています。
このスキーマに配置するのは動的テーブルかビューです。これらはフィーチャービューと呼ばれます。
特徴量はエンティティごとにまとめて管理することができ、バージョン管理されることから学習時から推論時まで一貫した特徴量の保管が可能になります。
モデルレジストリ
続いてはMLモデルを管理する、モデルレジストリという機能です。
こちらはMLモデルをバージョン管理しながら保存できるスキーマオブジェクトです。
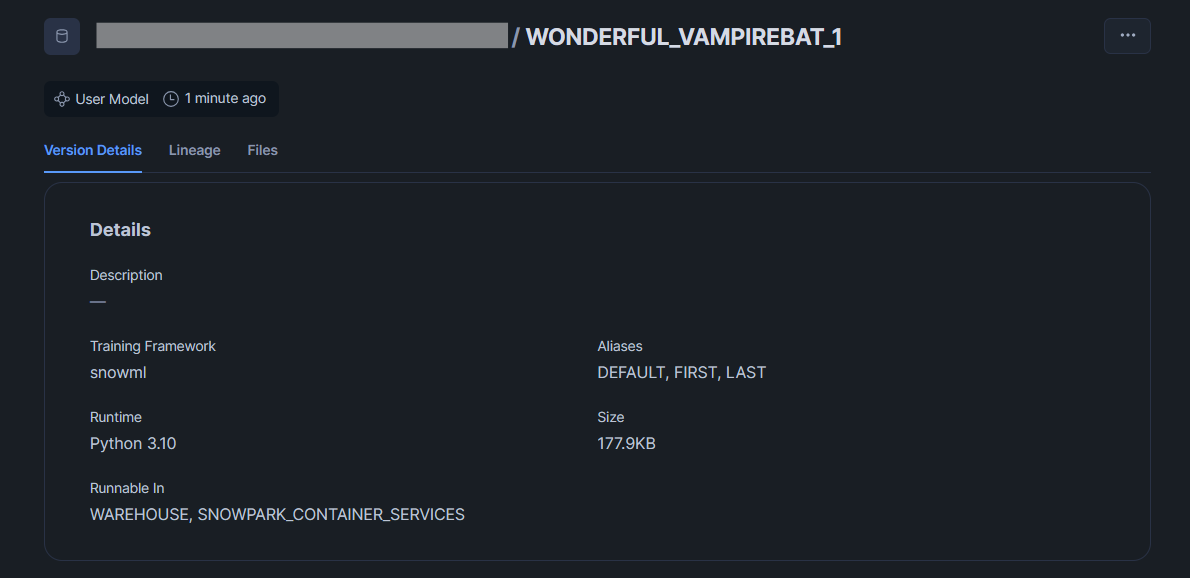
モデルレジストリを使うことで、どのモデルでどの特徴量が使われているかといった情報や使用できるメソッドがSnowsight上に表示されます。

またLightGBMなどのモデルではSHAPを算出するexplainメソッドがデフォルトで利用でき、推論時の特徴量重要度を簡単に入手することができます。
from snowflake.ml.registry import registry
from snowflake.ml.monitoring import explain_visualize
## 登録済みモデルを取得
reg = registry.Registry(session=session, database_name='DEMO', schema_name='DEMO')
mv = reg.get_model('DEMO_MODEL').version('WONDERFUL_VAMPIREBAT_1')
## 推論データを取得
pred_tbl= (
session.table("demo.demo.pred_data")
.select("LAG_1", "LAG_2", "LAG_3", "LAG_7", "LAG_14")
).to_pandas()
## SHAPを計算
raw_shap = mv.run(pred_tbl,function_name='explain')
## 可視化
explain_visualize.plot_force(raw_shap.iloc[15],pred_tbl.iloc[15])
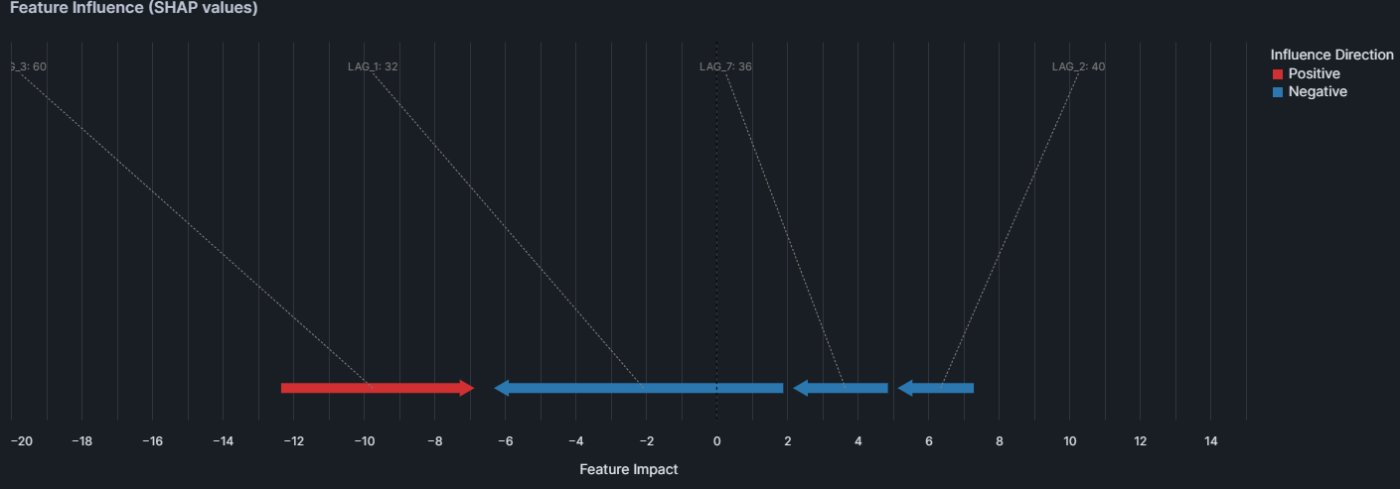
SHAPの可視化がネイティブにサポートされたことで、運用サイクルから再び開発サイクルへ戻っていく流れがよりシームレスになってきました。
まさにMLOpsの実現と言えます。
モデルモニター
モデルレジストリを使用するメリットの一つにモデルモニターがあります。
これはモデルの精度を測ったり、データドリフトの検知を自動で行う機能になります。
CREATE MODEL MONITOR FOR_DEMO_MODEL
WITH
MODEL=DEMO_MODEL
VERSION=WONDERFUL_VAMPIREBAT_1
FUNCTION=predict
SOURCE=PRED_DATA_WITH_ACT --推論結果と実績値を格納したテーブル
BASELINE=TRAIN_DATA --学習データのテーブル
TIMESTAMP_COLUMN=TRANSACTIONDATE -- 時系列列
PREDICTION_SCORE_COLUMNS=(PRED) -- 予測値列
ACTUAL_SCORE_COLUMNS=(TARGET) -- 実績値
WAREHOUSE=COMPUTE_XSMALL
REFRESH_INTERVAL='1 day'
AGGREGATION_WINDOW='1 day';
上記クエリを実行することで自動的にダッシュボードを作成してくれます。


モデルモニターの情報はSQLを使ってクエリすることが可能であるため、定時実行することで、ドリフト状態を開発者にアラートすることができます。
おわりに
MLに特化したプロダクトは世の中に沢山あります。
これまではSnowflakeのML関連機能といえば片手落ち感が否めず、わざわざSnowflakeでやる必要はないよね~というレベルでしたが、特徴量ストアやモデルレジストリの拡張機能など「データを中心に置いているSnowflakeだからこそ手軽に実装できる」という機能が増えてきました。
MLOpsは技術とビジネスの融和を極限まで高めていくプロセスです。Snowflakeはその受け皿として活躍できるのではないでしょうか。
Discussion