Rで複数のExcelファイルを読み込んでデータ抽出


はじめに
久しぶりの投稿です。社会人になって、Excelを使う頻度が増えました。複数のエクセルブックを開いて、コピーアンドペーストを手作業で繰り返すのがバカバカしくて、Rで関数を作ってみました!
(怠惰がたたって勉強するのはプログラミングをする人のあるあるだと信じてます)
目標
Rを使って、あるフォルダにしまってある複数のエクセルファイルから、それぞれ特定の列だけ抽出して新しいデータフレームを作成するスクリプトを書きます。
できるようになることのイメージ図↓
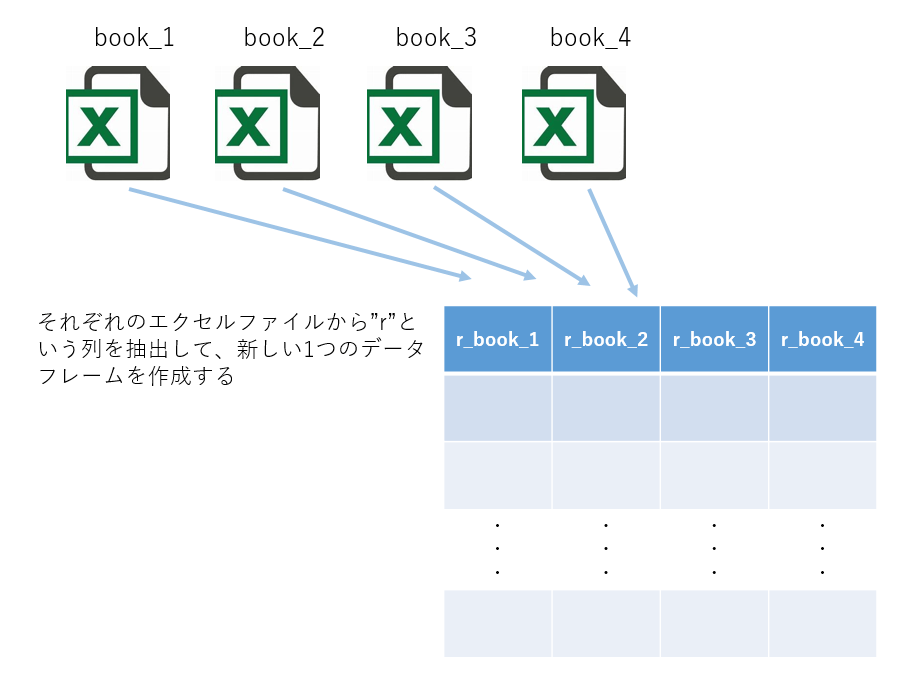
アプローチ
正直、やりたいことを達成するアプローチはいくつもあると思う。中でも一番簡単に思いつく方法は、read.xlsx()を繰り返すことかなあと思う。けどこれだと何回もエクセルのブック名を確認して、間違いのないように入力→read.xlsx()実行を何度もするのは面倒。
そこで今回は、「一つのフォルダにまとまっているxlsxファイルをリストとして取得し、そのファイルの中の列名を指定して抽出してデータフレームを作成する」という流れのアプローチでやります。
本当は実際のデータ使いながら記事を作りたいですが、研究所のデータ使うわけにもいかないので、なしで書いていきます。
動作環境
-
MacBook Air(M1, 2020), macOS Ventura 13.3.1
-
会社のWin10のPC(動作確認しただけ)
-
RStudio, "Ghost Orchid" Release for macOS Mozilla/5.0 (Macintosh; Intel Mac OS X 12_0_1)
全スクリプト
とりあえず先にスクリプトだけ載せます。(わりと綺麗に書いたんじゃないかなあと思います)
各行で何が起こっているのかについてはこのあとで。
library(readxl)
folder_path <- "エクセルファイルへのパスを入力"
file_list <- list.files(path = folder_path, pattern = "\\.xlsx$", full.names = TRUE)
data <- list()
for (file in file_list) {
df <- read_excel(file)
columns_to_extract <- c("列名1", "列名2")
for (column in columns_to_extract) {
if (column %in% colnames(df)) {
if (!is.null(data[[column]])) {
data[[column]][[basename(file)]] <- df[[column]]
} else {
data[[column]] <- list()
data[[column]][[basename(file)]] <- df[[column]]
}
}
}
}
dfs <- lapply(data, function(column_data) do.call(cbind, column_data))
combined_df <- do.call(cbind, dfs)
print(combined_df)
1.パッケージ準備
まずはエクセルファイルをRStudioで読み込むために、パッケージreadxlをロードしておきます。
パッケージをまだ使ったことがない人は、install.packages()を先に済ませておきましょう。
install.packages("readxl") # 初回のみ実行
library(readxl)
2.Excel bookの読み込み
まず、list.files()を使用して指定したフォルダ内のファイルのリストを取得していきます。
# Excelファイルが置かれているディレクトリの指定
folder_path <- "パスを書く"
# フォルダ内のxlsxファイルのリストを取得
file_list <- list.files(path = folder_path, pattern = "\\.xlsx$", full.names = TRUE)
-
path引数で、ファイルを検索するディレクトリのパスを指定します。
今回のコードでは、folder_pathという名前をつけた変数にフォルダのパスを入力するようにしました。(グループメンバーが使用する可能性を考え、あまりコードの基幹部分を編集したくないと思案)
-
pattern引数で、ファイル名のパターンを指定します。
今回は、拡張子が「.xlsx」であるファイルのみを抽出したいです。しかし、そのままpattern = ".xlsx"と指定してしまうと、怠惰な人(僕とか僕)がフォルダ内におきっぱなしにした、邪魔なものまで読み込んでしまう可能性があります。
こんなやつ↓
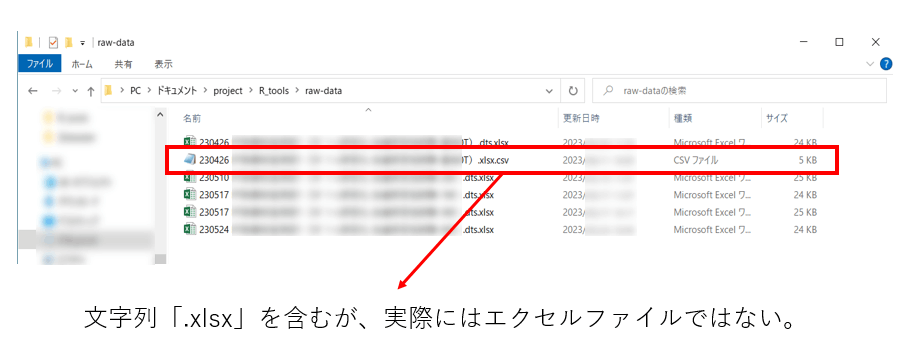
そこで、これを回避するために、
$(ドルマーク)で、「文字列の最後」にマッチする「.xlsx」を認識させます。(これによって、上の画像のような「.xlsx.csv」みたいなファイルの取得を回避できる。)
さらに、R言語における.(ドット)は、「任意の一文字」を認識してしまいます。そのため、「.(ドット)を.(ドット)として認識させる」ために、\\(バックスラッシュ2個)をドットの前につけておきました。
果たしてここまでする意味はあったのか…?
3.抽出データの格納場所を設定
続いて、dataという名前の空のリストを作成しておきます。このリストは、抽出した列のデータを格納するために使用します。
# 列を保存するためのリストを作成
data <- list()
4.取得したExcelから列データを抽出
ここが色々と処理を行う部分です。
for (file in file_list) {
df <- read_excel(file)
columns_to_extract <- c("列名1", "列名2")
for (column in columns_to_extract) {
if (column %in% colnames(df)) {
if (!is.null(data[[column]])) {
data[[column]][[basename(file)]] <- df[[column]]
} else {
data[[column]] <- list()
data[[column]][[basename(file)]] <- df[[column]]
}
}
}
}
説明は時間ある時に熱意があれば書きます。コメントくれたら仕方なくやります。
要は、「file_listにあるExcel全てに対して、column_to_extractで指定した列名に合致する列データを抽出する」という作業を繰り返し実行させるプログラムです。
5.データフレームとして出力
最後に、dataリスト内の各列のデータを結合し、1つのデータフレームとして組み合わせます。
dfs <- lapply(data, function(column_data) do.call(cbind, column_data))
combined_df <- do.call(cbind, dfs)
これで、初めに指定したディレクトリ下にあるexcelファイルから、指定した列名のデータをそれぞれのエクセルファイルを開いてコピーペースト…なんて面倒なことをせずに、ひとまとめにすることができました〜!
(最後のcbindをrbindにしたいケースも多いかもしれない)
終わり
記事はやっつけ感ありますが、スクリプト自体の作成は結構時間かけちゃいました〜…
今後も仕事で使うことになると思うし、応用もたくさんできそうなので、またアップデートがあれば続きの記事書こうかなと思います!
約9ヶ月ぶりの記事作成&投稿でした。読了お疲れさまでした!
Discussion