🚀
【OpenAI】Whisper で音声データを文章化し、発話の開始時間と終了時間を含めたCSVデータにする


概要
- 音声データを文章化する
- 文章化するとある程度で区切られて出力され、その区切られた文章の開始時間と終了時間を含めCSVデータにする
- OpenAI が GitHub にオープンソースのモデルとして公開している Whisper を利用
実行するにあたって
- 無料で実行することができる
- google Colaboratory を利用して実行する
- 適当な音声ファイルをご準備ください
実行手順
今回実行した ipynbファイル は GitHub に公開しています。
GitHub に公開された ipynbファイル はリンクから Google Colaboratory で開くことができます。
![]()
-
上記の [Open in Colab] をクリックして、Google Colaboratory で開く
-
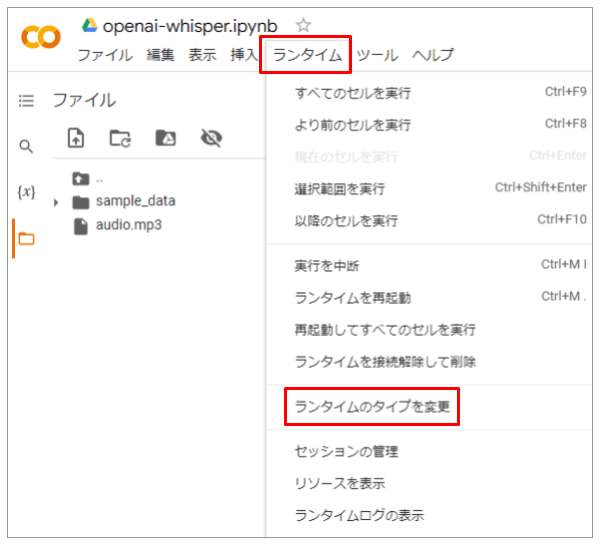
ランタイムの設定
-
メニューバーの [ランタイム] - [ランタイムのタイプの変更] をクリック
-
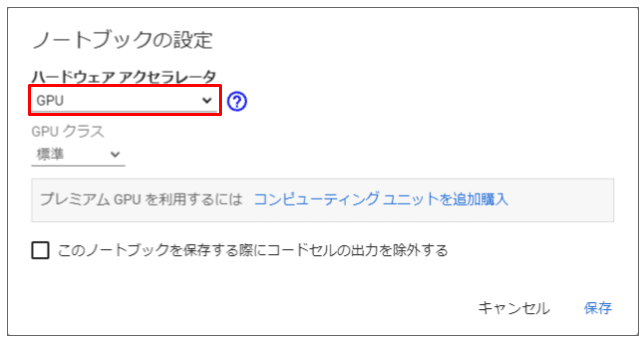
ハードウェア アクセラレータ で
GPUを設定する
-
-
音声データの追加
- サイドバーの 📁アイコン をクリックしてファイルの一覧を表示し、テキストを抽出したい 音声データ を drag & drop で追加
- サイドバーの 📁アイコン をクリックしてファイルの一覧を表示し、テキストを抽出したい 音声データ を drag & drop で追加
-
変数のセット
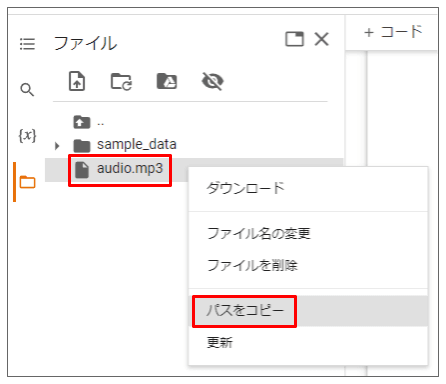
- 追加した 音声データ を右クリックして
パスをコピーでファイルの絶対パスをコピーする
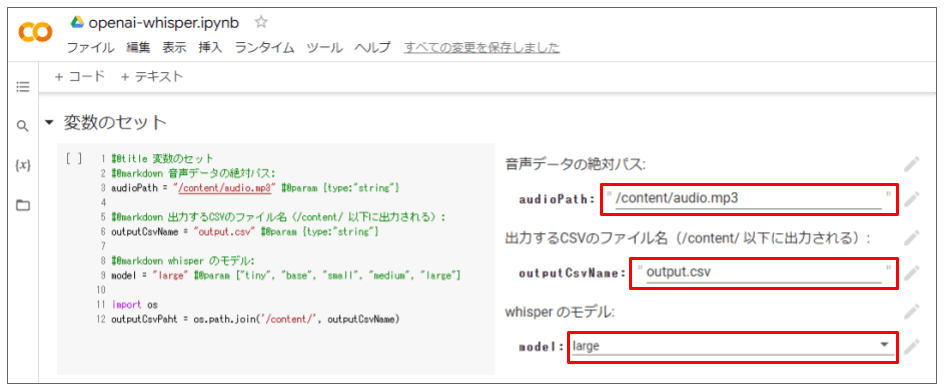
- 変数
audioPathに音声データの絶対パスをセット - 変数
outputCsvNameに出力するcsvのファイル名をセット - 変数
modelで 使用する whisper のモデルを選択する
- 追加した 音声データ を右クリックして

-
Ctrl + F9ですべてのセルを実行すると/content/以下に指定した名前のcsvファイルが出力される
実行している内容について
1. パッケージの導入
! pip install git+https://github.com/openai/whisper.git
OpenAI の Whisper のリポジトリから最新のコミットの内容と、依存するパッケージがインストールされます
2. 音声データを文章化
コード
import whisper
model = whisper.load_model(model)
result = model.transcribe(audioPath)
print('言語: ' + result["language"])
print(result["text"])
結果
言語: ja
宮沢賢治作 雨にも負けず雨にも負けず 風にも負けず雪にも 夏の暑さにも負けぬ丈夫な体を持ち...
音声を文章化するという点ではかなり正確に文章化されていました。
コードの内容
model = whisper.load_model(model)
変数 model に指定したモデルが読み込まれます。モデルには tiny, base, small, medium, large があり、後のものほど精度が良くなりますが、変換に時間が掛かり、必要になるメモリも大きくなります。
large の場合モデルが読み込みで 1分30秒 程度掛かりました。
result = model.transcribe(audioPath)
transcribe で指定した音声ファイルの文章化が実行されます。large の場合、2分程度の音声ファイルで 30秒 程度掛かりました。
transcribe は dict を返し、以下 key を持っています。
language: 検出された言語
text: 文章全体
segments: 分割された文章の詳細情報(その文章の開始時間や終了時間の情報も含む)
3. 発話の開始時間と終了時間を含めたCSVデータにする
コード
import pandas as pd
segmentsDf = pd.DataFrame.from_dict(result["segments"])
# csv ファイルに出力
segmentsDf.to_csv(outputCsvPath)
# 内容の表示
segmentsDf.head(10)
結果
-
contentディレクトリ以下に、指定したファイル名の csvファイル が出力 - 以下の内容を表示
| id | seek | start | end | text | … | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.00 | 11.00 | 宮沢賢治作 雨にも負けず | … |
| 1 | 1 | 0 | 11.00 | 14.08 | 雨にも負けず 風にも負けず | … |
| 2 | 2 | 0 | 14.08 | 19.52 | 雪にも 夏の暑さにも負けぬ | … |
| 3 | 3 | 0 | 19.52 | 24.38 | 丈夫な体を持ち 欲はなく | … |
| 4 | 4 | 0 | 24.38 | 28.20 | 決して怒らず いつも静かに笑っている | … |
| 5 | 5 | 2820 | 28.20 | 37.82 | 一日に玄米四合と味噌と少しの 野菜を食べ | … |
| 6 | 6 | 2820 | 37.82 | 42.76 | あらゆることを自分を感情に入れ ずに | … |
| 7 | 7 | 2820 | 42.76 | 48.20 | よく見聞きしわかりそして忘れず | … |
| 8 | 8 | 2820 | 48.20 | 55.36 | 野原の松の林の陰の小さなかや ぶきの小屋にいて | … |
| 9 | 9 | 5536 | 55.36 | 62.00 | 東に病気の子供あれば 行って看病してやり | … |
コードの内容
import pandas as pd
segmentsDf = pd.DataFrame.from_dict(result["segments"])
# csv ファイルに出力
segmentsDf.to_csv(outputCsvPath)
segments に分割された文章と開始時間、終了時間などを持っています。pandas で segments を読み込み、CSVファイルとして出力しています。
Discussion