dbt-labs packages
暇で、次の職場でdbtを色々使うことになりそうなので、便利なものがないかザーッと見てみる。
とりあえず、dbtの概念自体は長年色々やっていたので、つかめるだろう。
が付属するエコシステム周りは知らないと辛いこともあるかと思うので、「知るために」ザーッと洗う。
とりあえず、documentを見ると
「Hub Packages」というのがおすすめらしく、そこから見ていくと良さそうなのであらっていく。
synapse_statistic
Azureのsynapse用のpackage。
分析用のviewを作ることができるらしい。Azure synapseは使ったことがないので詳細はわからない。
コードをみたが、information schemaのようなものを作ってくれるものっぽかった。
なるほど、dbtはELTを委ねる認識が強かったがこういうものも管理させるという選択肢もあるのかもしれない。
uaparser
UA文字列を分解するpackage。
なぜだがembulkを思い出した。
これはmacroなので、UDFを作るみたい。
実装を見たが、javascriptでゴリってた。
ん、ということはjavascript実装があるUDFに限られる?(bigquery/snowflake)
snowflakeだけみたい。
avo_audit
AVOのeventの発生件数から「anomaly detection」するというもの。
全体のイベント件数と日別の件数を比較するというのがベース。
こういうのは便利だよね。
AVOというのが全然聞き覚えがなかったが、 https://www.avo.app/security これっぽい?
dbt_artifacts
dbt上で管理されているものをdwhに上げ、さらにいい感じのmartを作成してくれる。
実行履歴や、sourceや変数定義なども含まれる模様。
uploadされるデータなどはすべてこちらにある。
データガバナンスのためにdbt以外でメタデータやリネージュを構築することは多くあると思われるため、これを元データにするのは大変良さそう。
ジョブの実行状態のモニタリングなどもこれを利用すれば良さそうな気はする。
documentを読めばわかるが、on-run-endを入れずにデータがuploadされずに悶ていた。
仕組みをよくわかっていない証拠ですね。
dbt_date
日付系の便利関数が集まっている・・・!
基本これらは自前で実装(することもしないことも)あるので、これらが最初から用意されるのはとてもいいですね。
あとは、Bigquery/snowflake/Redshiftで関数や引数が異なることも多いので、これで抽象化されるのはとてもいい。
timezoneも変数で固定化できる・・・うれP
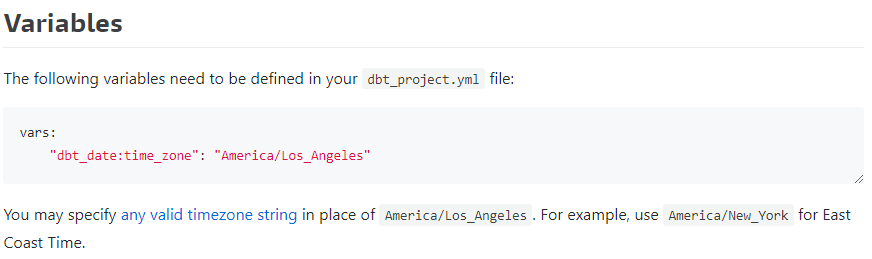
dbt-expectations
Greate Expectetions packages for Pythonに影響を受けたらしいが、もとを知らない。
テスト系のpackageであることがわかる。
かなり多くのテストがある。
いいなーって思ったのをメモってく
- expect_column_to_exist
- select * で雑に書いちゃうときに、上流の変更だったりでなくなったりしちゃうことが過去に稀にあったので、それを検知できるのはいい
- expect_table_aggregation_to_equal_other_table
- データソースは異なるが、集計値は一致スべきであるデータなどがある、そういったときに良い
- expect_column_values_to_be_between
- expect_column_values_to_be_increasing/decreasing
- 累積系のデータとかの検証にいいよね
- expect_column_value_lengths_to_be_between
- まれにある人間入力系のマスターデータでデータフォーマットの異常検知に使えそうな感じ
他にもいろいろ使えそうなのがあった。
基本的にテストを書く場合は、頑張る前にこのpackageでカバーできないか?を確認すべきっぽい。
airbyte_*
https://airbyte.com/ のコネクター用のモデル定義。
違う話だけど、データメッシュを作るときとかにdbt packageとしてデータ定義を公開し、それを利用することでhogehogeとかできそう・・・?って見えた。
airbyteはELTツール。一瞬検討したが、つかわなかった懐かしい。
dbt_profiler
dbtのprofilerかと思ったが、データのプロファイリングを行うもの。
データカタログでありがちな、最大/最小/分布みたいなのを集計し、document化する。
システムメタデータの生成を自動化してくれる、というイメージ化。
ここらへんを時前でやるのは結構骨が折れるから、いいですね。
profile用のsqlを作る必要があるっぽいから、そこら編の管理とかすべてのテーブルを対象にするのは地獄なのでうまく工夫をしたい。
コマンドラインから指定のテーブルを取得する機能もあるようなので、CIに組み込みやすさもありそう。
$ dbt run-operation print_profile_schema --args '{"relation_name": "stg__test_table"}'
04:10:20 Running with dbt=1.4.1
04:10:23 version: 2
models:
- name: stg__test_table
description: ''
columns:
- name: id
description: ''
meta:
data_type: number
row_count: 10.0
not_null_proportion: 1.0
distinct_proportion: 0.2
distinct_count: 2.0
is_unique: false
min: '1'
max: '2'
avg: 1.5
std_dev_population: 0.5
std_dev_sample: 0.5270464875131984
profiled_at: 2023-02-21 20:10:23.394 -0800
- name: name
description: ''
meta:
data_type: text
row_count: 10.0
not_null_proportion: 1.0
distinct_proportion: 0.2
distinct_count: 2.0
is_unique: false
min: null
max: null
avg: null
std_dev_population: null
std_dev_sample: null
profiled_at: 2023-02-21 20:10:23.394 -0800
dbt_quickbooks
Quickbooksデータ?のdatalakehouse connectorのためのデータ定義。
Quickbooksデータというのは会計用のSaaSらしい。
他にもdatalakehouse製品のコネクターがいくつかある。
dbtvalut
DataValut 2.0をdbtで扱うためのpackage.
これ単体だけで1週間はかかると思うので、存在の認知だけに納める。
ga4_metrics
GA4のデータをいい感じに分析しやすいデータにしてくれるやつ。
UAの頃からそうだったけど、素のデータだとstructだったり扱いにくいからね。
ただeventがflattenされてテーブル化されたり、結構気をつけないといけなそう。
これを参考にしつつ、結局自分たちでカスタマイズって感じka
profitwell_metrics
Profitwellというデータのよくある指標を集計してくれるやつ。
作者がGA4と同じ人。この人が使ってるデータなんだろうけど、それを公開してくれるとかすごい。
profitwellというのはsubscriptionの分析用ツール?っぽい。あまりこの分野には明るくないので、よくわからない。
adwords
Google Adwordsのデータモデル。
Adwordsなくなったので久々に見て懐かしくなった。
dbt_project_evaluator
データモデルとしてのbest practiceを集めて、ルール化したもの。
ある種のlinter的なものと思うが、アラートだらけにならないのだろうか?
ルールいろいろある。
- Direct Join to Source
- 直接sourceをjoinしているケース
- これはたしかに
- 直接sourceをjoinしているケース
- Downstream Models Dependent on Source
- downstreamのデータがsourceに依存しているケース
- これはたしかに
- downstreamのデータがsourceに依存しているケース
- Hard Coded References
- 直接テーブルを参照しているケース
- これはたしかに
- 直接テーブルを参照しているケース
- Model Fanout
- 多いと良くないケースはあるが、割とあるよなーっていう感覚。直接は意外とないか?
- Multiple Sources Joined
- 複数のsourceがjoinされている
- これはたしかに
- 複数のsourceがjoinされている
- Rejoining of Upstream Concepts
- 1つのSQLでやれ、という話はそのとおりだが、経験から一度テーブルに出力したいケースもあるんだよなー
ちょっと全部はメモできないが、やる必要性にはレベル感はあった(それはそう)
ルールの柔軟な制御はできるようなのでうまく使っていければよいね。
metrics
集計をmacro化する、というもの。
よくある集計を設定ベースでできる。
ぼくはSQL書けてしまうので、そっちが早くないか?という感覚がある。
レビューはし易いかも?
色々思うところはあるが、要検討。
考えたが、人がわかりやすいのが重要ではなくシステムがわかりやすくすることに真価がある、ということを思い見方が変わった。
データガバナンスの文脈でシステムでの解釈が可能な状態にすることでメリットがあると思った。
stitch_utils
stitchというデータローダーで取り込まれたテーブルのためのutility。
ちょっと詳細は不明。
audit_helper
データの比較を行うためのpackage.
名前から監査ログとかか?って思ったけど、データの同一性を確認するという意味での監査だったらしい。
ここらへんのクエリは地味に使う割に共通化するモチベーションが起きないので嬉しいですね。
比較する粒度を制御できるっぽいのでうれしい。
定常的なモデルに組み込むというよりは、データ・処理の移行や集計の確認などでうまく使えれば良さそう。
dbt_utils
よく使うクエリ集。
めっちゃいろいろある。
Test
定数比較ではなく、行数は他のモデルと比較できるのは大変良い
なんというかやったほうがいいし、やりたいがなかなか手が回らない系の静的テストが概ねあるという印象。。。
うまく集計は結構複雑なことも多いし、こういうテストでデータのあるべき状態を記述できるのはいいよね~~~
Macros
- get_column_values
- 例えば縦を横に変換するときにいいよね~
- 条件もかけるらしいし。。。
- 例えば縦を横に変換するときにいいよね~
- get_relations_by_pattern
- まれによくやるやつ
こっちは使い所や魔改造ができるな、という感じ。
あんまり使ってはいけない感覚。
SQL generators
- data_spine
- うれしい!
- Bigqueryは簡単に生成できるのだけど、Redshiftはいろいろあって強引にしないといけないので
- うれしい!
- star
- 地味だが超嬉しい!!
- BQでいうexceptをしたいときに他DWHだとできなくて辛い
- 地味だが超嬉しい!!
こっちは積極的に使っていきたい。
使うことによってクエリの意図が簡単に伝えられるのはうれしいよね。
redshift
Redshiftのシステムテーブルのモデル。
だけとおもったら、compressとかunloadのマクロがなにげにありいいですね。
dbt-codegen
dbtのコードを生成するやつ。
sourceの既存テーブルのimportとかないのかなーとか思ってたからやっぱりあった。
modelの生成もいいですね。
CTESの生成もありといえばあり。。。か?いや微妙そう。
facebook_ads
facebook adsのデータモデル。
facebook adsにはあまりいい思い出がないので、うってなった。
こっちは開発をシてないらしいので注意。(fivetran側にある)
snowplow
snowplowというSaaSのデータモデル。
snowplowは行動データを収集できるやつ。GAとかに近いのかな?
こっちもあまり開発していない。
dbt_external_tables
外部テーブル用のpacakge。
ん、切り出されているということは標準では外部テーブルは扱えない?
標準で「external」定義することで扱えるがよりよく扱うためのものっぽい。
これを入れることで未定義である外部テーブルをdbtごしに作成してくれるもの?っぽい。
加えて、paritiion設定などもやってくれるので、これはうれしい。
logging
入れちゃうと速度低下するって警告をされている上に、dbt_artifactsを使ってくださいとのこと。
役割は一緒っぽい。
spark_utils
sparkの便利マクロを合わせたもの。
spark自体が懐かしい。
これから使うことはないと思うので一旦スキップ。
tsql_utils
Azure系のdatabaseに関するもの? へーTransact-SQLっていうのか。
natural_language
自然言語をSQLにおこすらしい。
どうやっているのかは興味があるが使うことはないと思うでスキップ
dbt_dataquality
dbt freshness/testの結果からデータ品質の可視化を行うもの。
ぱっと見はすげーっとなったが、使い所は難しそう。
レポート用のファイルを生成するらしいので、その内容次第では品質のmonitoring用途の一部として使えなくはない?
でもたぶんdbt_artifactsを仕込めばいいんだよなーっていう感覚がある。
snowflake_env_setup
snowflakeの環境をdeployするためのpackage。
こんなものもあるのかー。terraformなどでやるのがbetterとおもうので、サラーっとみておわる。
SQLを書くのも(頻度多くないので)忘れるので、CLIとしての利用価値は一定あるのかも。
edu_edfi_source
のモデル。
edu_wh
のモデリング。
elementary
データ監視を行う。
dbt_artifactsにUIを提供したもの的なニュアンスもあるか。
良さげ。
この手のものは実際に触って見ないことには。
dptplyr
dplyrをdbtで、というなかなかになかなかな発想。
dplyr懐かしいね。
dbt_snow_mask
snowflakeのデータマスキングのpackage.
データマスキング側の機能をよくしらないのでなんともいえない。
ただパッと見は、ymlに宣言的にかけるのでわかりやすそうではあった。
だが、modelを記述するdbtにそこまでやらせるべきなのか?という話はあるかも?
dbt_snow_utils
snowflakeの便利packageっぽい。
そんなに便利そうでもなかったかもしれない。
dbt_models_metadata
modelのメタデータを生成するやつ。
記録するカラムを追加でき、例えばデータが生成されたcommit hashを含めることでモデルの追跡が比較的容易になるのかも?
feature_store
feature storeのpackage。
あんまりピントは来てないが、特徴量生成の上でよくやるmacroなどがある?
fivetran
大量のコネクターのモデル。
こういうのをちゃんと用意してくれるのはいいよね。
dbt_segment
segmentと呼ばれる製品のデータモデル?
segmentはわからんがwebトラッキングっぽい。
明日は、get-selectから
dbt_snowflake_monitoring
snowflakeのmonitoring関連のmart生成
- cost
- wh
- storage
- query
- dbt自体のクエリコスト
など色々出してくれる。
便利だなあ。
dbt_snowflake_query_tags
dbtで発行されたクエリに自動でtagを付与するもの
↑のsnowflake_monitoringの依存でもあるっぽい
以前は全部自前で作りあげていたが、仕事なくなっちゃうね。
snowflake_spend
「dbt_snowflake_monitoring」とかぶるのでそっちをいれればよさそう。
fhir_dbt_analytics
FHIRデータのデータ品質を分析するためのモデル。
FHIRデータとは「Fast Healthcare Interoperability Resources」で、健康状態を記述するためのデータフォーマットらしい。
dbt_hightouch
hightouchというSaaSのためのモデル。
hightouchはReverseETLツール。
hightouchへの書き戻しログのようなものを管理するためのもの?っぽい。
carbon-analytics
carbon emissionsの分析のためのモデル。
おそらく
のこと。
グリーンテックってやつ?時代は進んでいる。
dq_tools
「Data Quality tools」とのこと。
6つの観点で評価を行う
- Accuracy
- Consitency
- Completeness
- Timeliness
- Validity
- Uniqueness
指標はカスタムできるが非推奨らしい。
組み込み方自体は、dbt testに専用のmacroを利用して行うとのこと。
結局各ドメインごとにどれがどうであればよいのかは変わってくると思うので、どのテストが何を目的としたものなのかを合意をとって、dbt artifactsでmonitoringしたほうが良さそう?って思った。
jitsu
jitsuのモデル。
jitsuはwebアプリ向けのデータ統合ソリューション。
アクセスログをDWHに直接送ってくれるらしい
segmentと似ているとのこと。
data_profiler
dbt_profilerをベースにしている。
列が拡張されているとのことなので、場合によっては選択肢に入るかも?
dbt_graph_theory
グラフ構造をdbtでうまくモデリングしたらしい。
recursive CTEを使ってやるやつ。
たぶんこれを使うシチュエーションになったら便利だと思う。
この手のクエリは読み解けないし、バグ入りやすいし、、、
でも書かなくていい状況作りたいね。。。
dbt_ml
BQMLをdbtで扱うというもの。
めっちゃいいっすね。
custom materializeにmodelが加わったイメージ出かけるのでよい。
hyper parameterのチューニングもやれるらしいので便利。
ただ、BQ MLが結局本番運用されたことはないのであった。
athena_utils
AWS Athenaのutlility。
dbt_utilsがathenaに対応していないので拡張しようというもの。
Athenaはテーブル定義でだいぶハックができてしまうので、そこら編がうまくカバーできていると嬉しいなと思ったが、そこは守備範囲外か。
upstream_prod
上流データをprod(というか別の環境)のデータを使って下流のモデルを作るというやつ。
dbtのdeferオプションを使えば?って思った。
upstream-prod is a dbt package for easily using production data in a development environment. It's like an alternative to the defer flag - only without the need to find and download a production manifest.
manifestってなんだっておもったら、実行時にtargetフォルダに生成されるファイル。
あーこれからdbt_artifactはデータ生成してるのか・・・
そして、これはproductionではs3などに連携するのが良いっぽいな。
deferの場合は、このproduction用のファイルを持っておく必要があるらしい。
そこらへんがこのpackageだと不要っていうメリット。
nayamu
materialize_dbt_utils
materilizeというdbのutil
materialize自体は知らなかった。
streamingデータに対しての分析を行う用途のdatabase。
へえ。
DuckDBもそうだが、OLAP周りも形態がいろいろ変わってきていると感じているので、新しい界隈をキャッチアップしていかないといけないな、と感じた。
dbt_datamocktool
source/refのモデルのデータをmock化するためのpackage。
seedデータと生成されたデータを比較するためのunit test package?
使い方がちょっとよくわからなかったが、
inputをseedのデータに置き換え、expectデータと一致するかをseedで比較するみたい。
input_mapping:
source('jaffle_shop', 'raw_customers'): ref('dmt__raw_customers_1')
で、sourceをローカルに配置されているseedファイルに置き換える
expected_output: ref('dmt__expected_stg_customers_1')
でローカルに配置されているseedファイルと比較する。
この手のテストはデータの準備が大変なので限ったデータだけにしたいが、比較するためのロジックが予め準備されているのは最高
dbt_product_analytics
製品分析を提供するモデル。
- event_stream
- イベントの流れをトラッキングする
- 新規→継続とかそういうやつ
- イベントの流れをトラッキングする
- funnel
- ファネル分析
- retention
- flows
クエリでよく書く割にいつもしんどいクエリになりがちなのでいいですね。
ただしんどいクエリになるのは結構ドメインごとに集計条件がことなるという・・・
まあなので、これに食わせるモデル化をしっかりやろうっていう話か。
初期分析として入れておくと分析の初速が付きそうでよいかも。
dbt_ml_preprocessing
機械学習でよく行う前処理をmacro化して提供。
OneHotEncodingはもちろん、正規化とか様々なものを提供している。
便利そう。
ただ、この処理をDWHでやらせるべきなのか?という話もありそう。
dbt_privacy
メールアドレスなどのprivacyデータの保護を目的としてpackage。
いいんだけども、そもそも入る前にやる、というの要件に基本はいるので難しい・・・
DWHに入れてもいいが、外に出してはいけないっていうときにつかうとよい?
まああとはガバナンス的な話で「どういう maskingがあるのか」を知っておく意味でも一目透しておくと良いかも。
re_data
data riliabilityのためのフレームワークらしいが、、、
redataと呼ばれるダッシュボードに食わせるデータみたい。
live demoが用意されていた。
わるくはなさそうだが。。。データ品質のモニタリングが必要になった場合に選択肢として考えておこう。
id_stitching
ID統合を行うpackage。
自前でクエリを書いたなあっていうきおく。
dbt_constraints
制約に基づくテストを実行する、p-keyや参照整合性とか。
参照整合性のテストが振られている場合は、main tableにすべて含まれるかなど確認しに行くらしい。
データ基盤的な特性だと、テストにいろいろ工夫が必要かもなあとか思ったりした。
いまいち正確に把握できていないと思うので、後で試す。
metalog
dbtでmetaデータ管理をするやつ。
modelのconfigにデータを記述できる。
I/Fは外でも良いが生成システムとしてdbtを使うのはよさそうかも?
ビジネスメタデータ自体が非エンジニアじゃないパターンが多いので。
メタデータのスキーマもこれで定義できるとのこと。
dbt_meta_testing
projectのtest/docのカバレッジに基づくテストを行うというもの?
docは必須、xxxフォルダにはAAテストは必須などをルールづける。
dbt_project_evaluatorがなければ良さそうだった。
まとめ
途中からmodel系のpackageは端折ったが、2023-02-24時点のdbthubに https://hub.getdbt.com/ を一通り見ていった。
結果、以下のものはまた見ていきたい。
- dbt_artifacts
- dbt_date
- dbt-expectations
- dbt_profiler
- dbt_project_evaluator
- metrics
- audit_helper
- dbt_utils
- dbt-codegen
- dbt_external_tables
- elementary
- dbt_snowflake_monitoring
- dbt_datamocktool
ここらへんは実際に使ってみて、より理解を深めていきたい。
感想
汎用モデルとしてのpackageと、dbtを拡張(データ品質/検証)するもの、クエリの簡易化マクロを提供しているpackageが大きく分けるとあるようだった。
汎用モデルは公開されているものを利用する、というよりは社内向けに育てていくとメリットが出そうに思った。
拡張系に関しては使い方を誤ると黒魔術になりがちそうだったので注意したほうが良さそうだった。
でも全体的に柔軟で自由度が高いツールであることがわかったので良かった。